
SQL 튜닝을 위해 Index를 활용해야 하는 것도 알겠고
어떤 기준(실행 시간/계획)으로 판단하며 진행 해야하는지도 알게된 상황에서
그럼 각 Case에 따라서 어떻게(How) Index를 적용해야 하는지 알아보자!
[조건절이 2개 이상인 Query 상황]

문제가 되는 Query가 위와 같다고 가정해보자(data는 1,000,000 row)
조건절이 2개인 경우 어디에 어떻게 Index를 걸어야 할까?
(department? created_at? 둘 다 복합 Index로?)
[1. department에 Index]

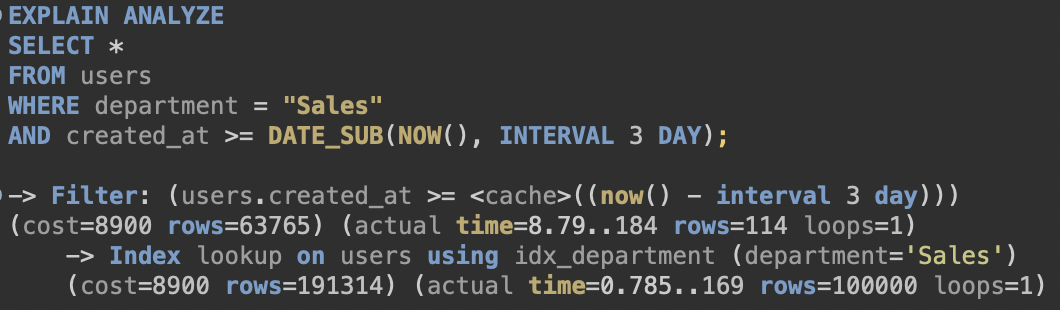
실행 시간 : 252ms -> 191ms(첫 실행때는 631ms까지 튀었는데 이유는…)
실행 계획 : 처음 가져오는 data 수 100,000 row
실행 시간이 Index가 없을 때에 비하면 줄긴 했으나 두드러지지 않는다.
부서라는 컬럼의 특성상 중복도가 높아서 처음 가져오는 row의 수도 적지 않다.
[2. created_at에 Index]

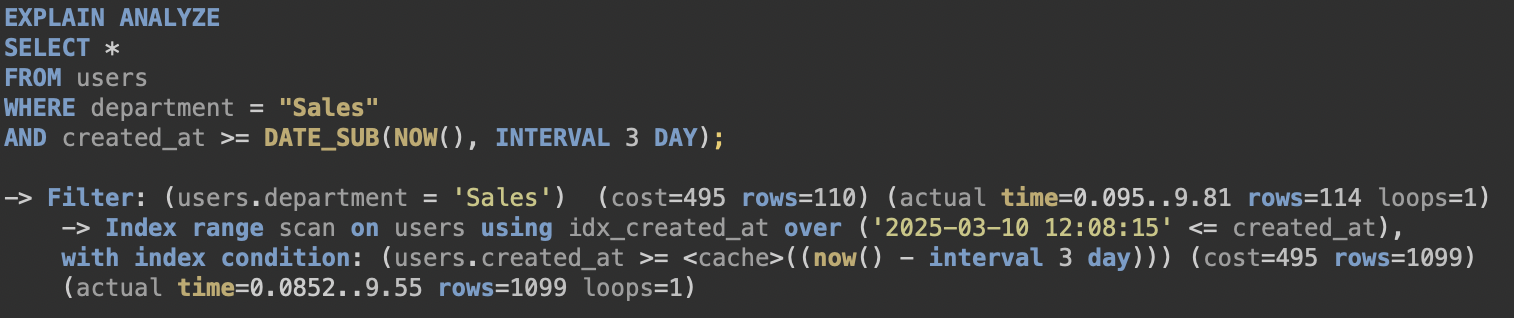
실행 시간 : 252ms -> 28ms
실행 계획 : 처음 가져오는 data 수 1099 row
실행 속도가 거의 10배 가까히 빨라졌고, 가져오는 row 수도 크게 압축되었다
[3. 복합 Index(department, created_at)]
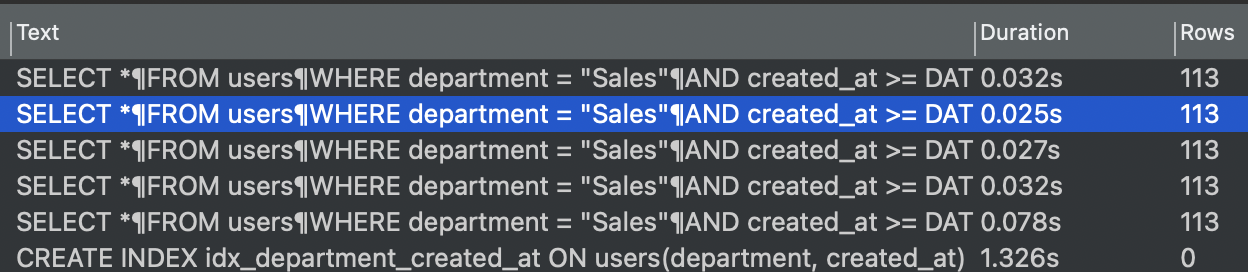

실행 시간 : 252ms -> 25ms
실행 계획 : 처음 가져오는 data 수 113 row
복합 Index 또한 실행 속도가 10배 가까히 빨라졌고, row 수는 created_at에 비해서도 적다.
[결론]
실행 시간 : idx_department_created_at(25ms) > idx_created_at(28ms) > idx_department(252ms)
선택 : idx_created_at만 생성
"idx_department_created_at"이 가장 빠르니 복합 Index를 선택해야 하는 것 아닌가? 할 수 있지만
단일 Index와 복합 Index의 성능 차이가 크지 않다면 단일 Index만 생성하는 것이 권장된다.
Index도 결국 비용이기 때문에 가능하면 최소화하는 것이 좋다.(Index Table 공간 + 쓰기 작업 부하 가중)
ps. 둘 다 각각 Index를 설정(idx_created_at / idx_department)하면 어떨까?
둘 다 각각 Index를 설정하면 옵티마이저가 idx_created_at 만 사용하게 됨(EXPLAIN의 key 결과)
-> idx_department가 낭비됨
