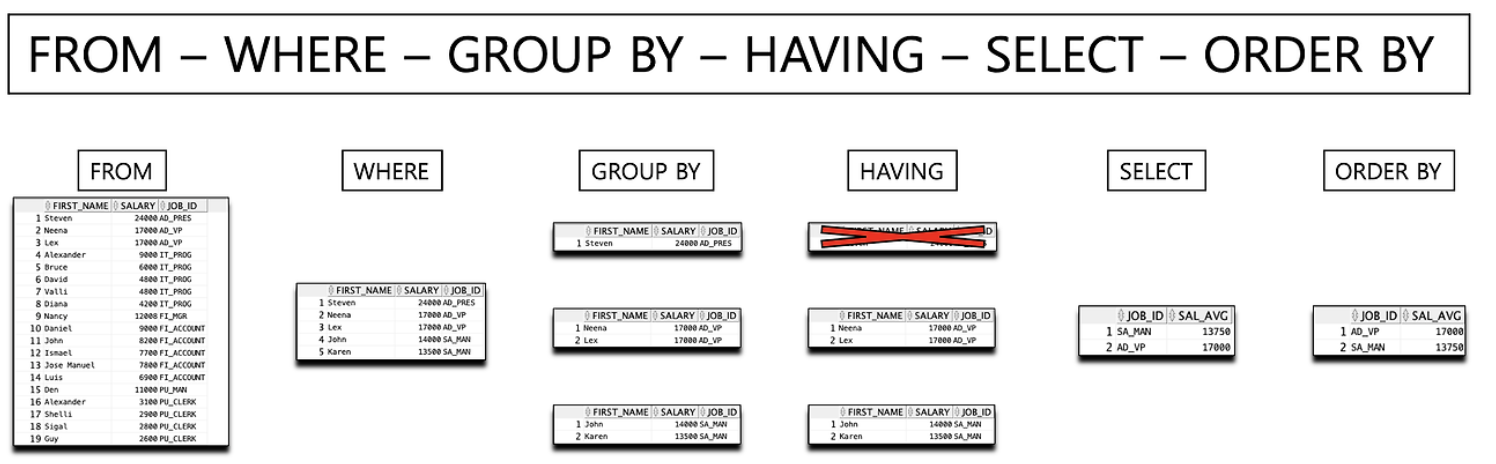
SQL 실행 순서를 더 직관적으로 이해할 수 있는 좋은 이미지다.
결국 튜닝에서도 기본 개념이 중요하다는 생각이 들었다.
[HAVING 절 컬럼에 Index 적용]
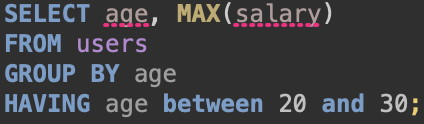
튜닝을 해볼 Query는 위와 같다.
적용해 볼 컬럼은 age 하나로 보이는데 age에 index를 적용하면 어떻게 될까?
[age에 index 미적용 상태]

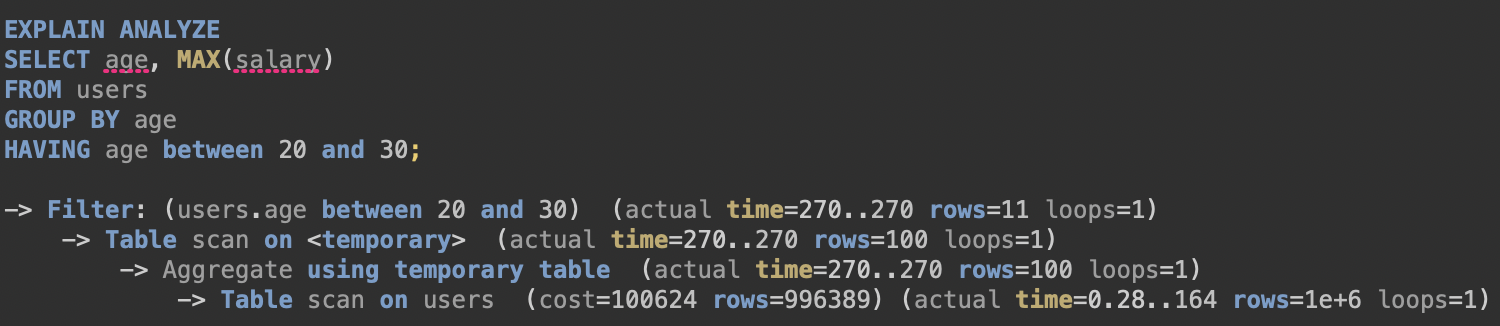
실행 시간 : 263ms
실행 계획 : 처음 가져오는 data 수 1000000 row(총 data 1000000 row)
비교 대상이 없지만 index를 적용하면 더 빠르게 집계하지 않을까?
라고 잠시 생각했었다...
[age에 index 적용]


실행 시간 : 263ms -> 1532ms(5배 이상 느려짐)
실행 계획 : 처음 가져오는 data 수 1000000 row(총 data 1000000 row)
index Table(age)만 스캔하면 salary 값을 알 수 없기에
결국 다시 원래 Table을 조회해야 해서 Index Table이 오히려 병목(1437ms)이 되어버렸다.
그럼 기존 쿼리를 그냥 두는 것이 최선일까?
[HAVING 대신에 WHERE 필터링]
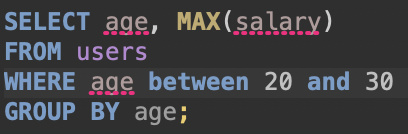
기존에 group by로 묶고 having으로 필터링하는 방식에서
미리 where로 필터링하고 group by 하는 형식으로 쿼리를 바꿨다.
[age Index 미적용(WHERE)]


실행 시간 : 263ms(having) -> 198ms(where)
실행 계획 : 처음 가져오는 data 수 1000000 row(총 data 1000000 row)
실행 시간이 크게 줄지는 않았지만, 필터링이 되면서 10분의 1 정도의 data 만을 대상으로 집계가 이루어졌다.
(생각보다 큰 속도 차이가 있지는 않다)
[age Index 적용(WHERE)]


실행 시간 : 198ms(where) -> 227ms(where)(오히려 느려짐)
실행 계획 : 처음 가져오는 data 수 109982 row(총 data 1000000 row)
큰 차이는 없지만 비용을 들였는데 오히려 느려진 상황이라 Index 적용을 하지 않는 것이 낫다.
Full Scan(160ms)을 하며 salary 같이 조회 vs Index Scan을 하고 salary 조회(201ms)의 차이로 보인다.
[결론]
Index는 만능 열쇠가 아니고, 오히려 병목이 될 수 있다.(필요한 경우만 추가)
튜닝의 방법은 Index 추가 뿐 아니라 쿼리의 실행순서를 고려하여 쿼리 자체를 수정하는 것도 고려해야 한다.
- HAVING 절이 불가피한 경우가 아니면 미리 WHERE 절로 data를 한번 거르고 GROUP BY 하자
- GROUP BY가 있는 SQL에서는 Index가 오히려 병목이 될 수 있다(결국 2번 조회)
다른 SQL에서 사용되는 것이 아니라면 Index 추가를 한번 더 검토!
