3. 머신러닝 on 라즈베리 파이
1. 머신러닝이란?
- 컴퓨터가 데이터를 통해서 스스로 학습하고 판단하는 기술
- 사람이 프로그램을 작성하지 않아도, 데이터로부터 패턴과 규칙을 발견하고 문제를 해결하는 것
임베디드 시스템에서의 머신러닝?
Training
- 모델을 학습 시키는 과정
- 데이터를 수집, 전처리
- 모델의 구조와 파라미터 정의
- 예측값과 정답 간의 차이를 최소화
- 최적화 과정이 끝나면 가중치 저장
Interfacing/Servicing
- 새로운 입력에 대해 예측값 생성
- 모델의 어떤것도 수정하지 않음
4. 내 애플리케이션 최적화 해보기
1. 애플리케이션을 만드는 법
- 용도에 맞는 하드웨어, 운영체제, 프레임 워크, 언어를 정하고, 그 뒤는 프로그래머의 몫
- 그러므로, 최적화의 방향을 정하면, 그 또한 프로그래머의 몫
2. Python으로 만든 애플리케이션을 최적화 하는 방법
1. 코드 최적화
- 간결하고 효율적으로 작성하면, 프로그램의 실행시간이 줄어들고 메모리 사용량이 적음
- 중복 코드 제거, 알고지름 및 자료구조 선택, 불필요한 변수/ 함수 제거 등이 포함
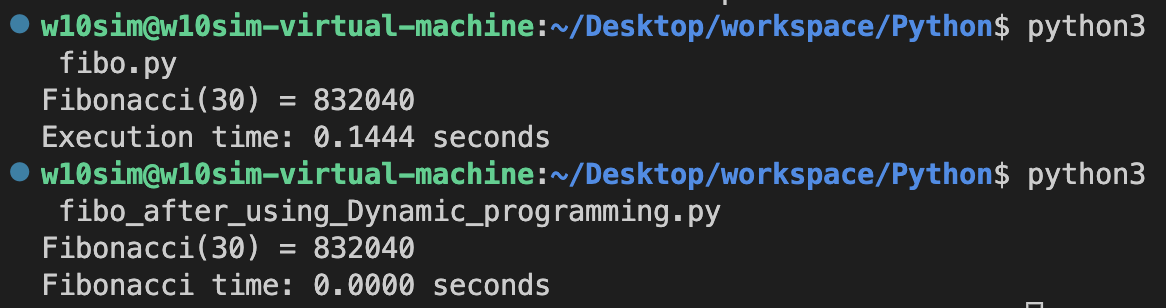
예시) 피보나치 수열 계산하기
0,1 로 시작하는 수열
이전 두 수의 합으로 다음 수가 결정되는 수열
1. 알고리즘 최적화 이전 : 재귀함수 사용
import time def fibonacci(n): if n <= 1: return n; else: return fibonacci(n-1) + fibonacci(n-2) strart_time = time.time() n = 30; fib = fibonacci(n) end_time = time.time() print(f"Fibonacci({n}) = {fib}") print(f"Execution time: {end_time - start_time:.4f} seconds")
2. 알고리즘 최적화 후 : 동적 프로그래밍(한 문제를 여러개의 문제로 나누어 푸는 방법) 이용
import time def fibonacci(n): fib_values = [0,1] for i in range(2, n+1): fib_values.append(fib_values[i-1] + fib_values[i-2]) return fib_values[n] start_time = time.time() n=30 fib = fibonacci(n) end_time = time.time() print(f"Fibonacci({n}) = {fib}") print(f"Fibonacci time: {end_time - start_time:.4f} seconds")
3. 메모리 사용량 확인
import time import tracemalloc # 최적화하지 않은 버전 def fibonacci(n): if n <= 1: return n else: return fibonacci(n-1) + fibonacci(n-2) # 최적화한 버전 def fibonacci_optimized(n): if n <= 1: return n prev1 = 0 prev2 = 1 for i in range(2, n+1): current = prev1 + prev2 prev1 = prev2 prev2 = current return current # 성능 측정 함수 def measure_performance(func, arg): start_time = time.time() result = func(arg) end_time = time.time() return result, end_time - start_time # 메모리 사용량 측정 함수 def measure_memory_usage(func, arg): tracemalloc.start() func(arg) peak_memory = tracemalloc.get_traced_memory()[1] tracemalloc.stop() return peak_memory if __name__ == "__main__": n = 35 # 최적화하지 않은 버전 mem_usage = measure_memory_usage(fibonacci, n) fib, time_elapsed = measure_performance(fibonacci, n) print(f"Non-optimized: Time elapsed={time_elapsed:.6f} seconds, Peak memory usage={mem_usage/1024/1024:.6f} MB") # 최적화한 버전 mem_usage = measure_memory_usage(fibonacci_optimized, n) fib, time_elapsed = measure_performance(fibonacci_optimized, n) print(f"Optimized: Time elapsed={time_elapsed:.6f} seconds, Peak memory usage={mem_usage/1024/1024:.6f} MB")
4. 결과
- 동적 프로그래밍을 사용하면 훨씬 더 빠른 실행속도를 보여준다.
- 배열을 사용하지 않고 지역 변수로만 피보나치를 구현하면 재귀함수를 이용하는 것 보다 스택 메모리를 덜 사용하게 되어 더 적은 메모리 사용량을 보여준다

2. 최신 Python 버전 사용
- 최신 버전, 특시 X.Y.Z 기준에서 X나 Y의 버전이 바뀐 경우, 성능 또는 기능의 차이가 클 수 있다.
-> ex) 3.8 이상부터 math.dist 함수가 들어감
1. 예시) math.dist
두 점 사이를 구하는 함수로, python 버전 3.8 이상부터 사용 가능
2. 사용하지 않았을때
import time import math import random def euclidean_distance(p1, p2): return math.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2) start_time = time.time() points = [(random.random(), random.random()) for _ in range(10**4)] distances = [euclidean_distance(points[i], points[j]) for i in range(len(points)) for j in range(i + 1, len(points))] end_time = time.time() print(f"Execution time: {end_time - start_time:.4f} seconds")
3. 사용하였을때
import time import math import random start_time = time.time() points = [(random.random(), random.random()) for _ in range(10**4)] distances = [math.dist(points[i], points[j]) for i in range(len(points)) for j in range(i + 1, len(points))] end_time = time.time() print(f"Execution time: {end_time - start_time:.4f} seconds")
4. 결과
python 버전 3.8 이상에서 지원하는 math.dist() 함수를 사용하였을때 더 빠른 실행시간을 보여준다

3. 프로파일링 및 벤치마킹
- 프로파일링 도구를 사용하면, 애플리케이션의 성능 병목을 찾아 유저레벨에서 개선이 가능
- cProfile, Py-Spy, Pyflame 등 다양한 프로파일링 도구가 있음
- 하드웨어/ 운영체제의 성능이 궁금할떄는 벤치마킹을 통해서 미리 성능을 확인해 볼 수 있다
1. cProfile
- 성능 병목 현상을 분석하기 위한 라이브러리
- 함수별 호출 횟수, 실행시간, 메모리 사용량 등
- 어떤 함수가 병목인지 파악할때 용이하다
2. timeit
- 소스코드 실행시간 측정
- 함수 작성하면, 그 함수를 쉽게 테스트 가능
3. memory_profiler
- 메모리 사용량 측정
- 코드 블록 단위, 각 줄마다 사용되는 메모리양, 대신 느림..
- 설치 방법
pip3 install memory-profiler
4. 병렬처리 및 동시성
- 애플리케이션에서 여러 작업을 동시에 수행하도록 구현
- Threading, multiprcessing, asyncio 등을 사용할 수 있음
1. Threading/asyncio
- GIL(Globlal Interpreter Lock)
- I/O 바운드 작업에 용이함
Threading
1.각 스레드마다 별도 실행 흐름
2. 데이터 동기화asyncio
1.이벤트 loop 기반, 메모리 사용량 줄음
2. 비동기 I/O에 최적화
2. Multiprocessing
- I/O 및 CPU 바운드 작업에 모두 적합
- GIL 영향 X
- 컨트롤이 비교적 어려움
5. JIT 컴파일러 사용
1.JIT(Just in Time) 컴파일러
2. PyPy, Numba 등등
3. 인터프리터 기반이지만 바이트 코드 -> 네이티브 코드로 변환해서 속도를 높임
4. Numba는 숫자계산을 위한 컴파일러
5. 사용법pip3 install numba
JIT 컴파일러 사용하기
1. 함수의 위에 다음과 같이 선언
@jit(nopython=True)
2. 코드
import numpy as np import time from numba import jit # 성능 향상 전 함수 def dot_product_no_jit(a, b): result = 0 for i in range(len(a)): result += a[i] * b[i] return result # 성능 향상 후 함수 @jit(nopython=True) def dot_product_jit(a, b): result = 0 for i in range(len(a)): result += a[i] * b[i] return result a = np.random.rand(100000) b = np.random.rand(100000) iterations = 100 # 성능 향상 전 함수 실행 시간 측정 start_time = time.time() for _ in range(iterations): result_no_jit = dot_product_no_jit(a, b) elapsed_time_no_jit = time.time() - start_time print(f"Result (no JIT): {result_no_jit:.4f}, Time: {elapsed_time_no_jit:.4f} seconds") # 성능 향상 후 함수 실행 시간 측정 start_time = time.time() for _ in range(iterations): result_jit = dot_product_jit(a, b) elapsed_time_jit = time.time() - start_time print(f"Result (JIT): {result_jit:.4f}, Time: {elapsed_time_jit:.4f} seconds")
3. 결과
jit를 사용한 경우 매우 빠른 실행시간을 보여준다

6. C/C++ 확장 사용
1. Cython
- C로 변환 가능한 python 모듈을 작성하기 위한 언어
- Python 코드를 c로 변환하고 Cpython 을 사용해서 C코드를 Python 모듈로 빌드
- Python 코드의 실행속도를 높일 수 있음
2. ctypes
- C 함수를 호출하고, C 함수 라이브러리를 사용하는 파이썬 코드를 작성하는데 사용되는 인터페이스
- Python 코드에서 c 함수와 변수 호출 가능
7. 외부 라이브러리의 활용
1. Numpy
- 숫자 관련된 python library
8. I/O 작업 최적화
- 네트워크 / 디스크 입출력 관련 최적화
- 기본적으로 disk 나 network는 느리다
- 다양한 최적화가 이미 운영체제에 적용되어 있음
- Normal read / mmap / asyncI/O
5. 운영체제 레벨 최적화
- 운영체제를 이용하는 입장에서 우리가 할 수 있는 최적화는 운영체제가 현재 어떻게 움직이고, 어떤 것이 root cause인지 확인하는 것
- 한 단계 더 나아가면, 디바이스 드라이버를 추가하거나, 커널을 고칠 수 있다
1. 프로파일링 툴들 구경해보기
1. Htop / top
- 설치
sudo apt-get install htop
- 터미널에서 실행중인 프로세스(애플리케이션)와 시스템 리소스 사용율을 실시간으로 표시
- Htop -> top의 향상된 버전
2. Mpstat
- 설치
sudo apt-get install sysstat
- 다중 프로세서 시스템의 CPU 사용률을 표시
- CPU 코어의 활동 및 유휴 상태 모니터링 가능
- ex) mpstat -n 1 -> 1초마다 해당 상태를 업데이트 해서 보여줌
3. Perf
- 설치(실패)
sudo apt-get install perf-tools다른 설치 방법(실패)
2. 내 운영체제가 어떻게 돌아가는지 거의 모든것 확인 가능
3. 하드웨어 이벤트 및 소프트웨어 이벤트를 수집하고 분석 가능
4. 많은 하위 명령어가 존재, ex) perf record, report, annotate ...주요기능
- 하드웨어 성능 카운터를 사용해서 CPU 이벤트(ex. Cache miss, branch miss)를 모니터링 가능
- 애플리케이션 / 커널의 성능 프로파일을 수집 가능, 시간이 긴 함수, 자주 호출되는 함수 등 성능에 문제가 있는 코드를 식별 가능
- 유저 / 커널 공간에서 발생하는 성능 데이터를 수집하고 파일에 저장 가능함,어떤 것을 수집할지, 샘플링 빈도등 정의 가능
- 프로그램의 성능 관련 통계를 수집하고 출력 가능, 성능 특성을 이해하고 개선방향 찾는게 가능해짐
확인해볼만한 포인트
- Context switching Overhead (CPU)
- Page fault Overhead (CPU, Memory)
- File I/O Overhead (Disk)
- Scheduling Overhead (CPU)
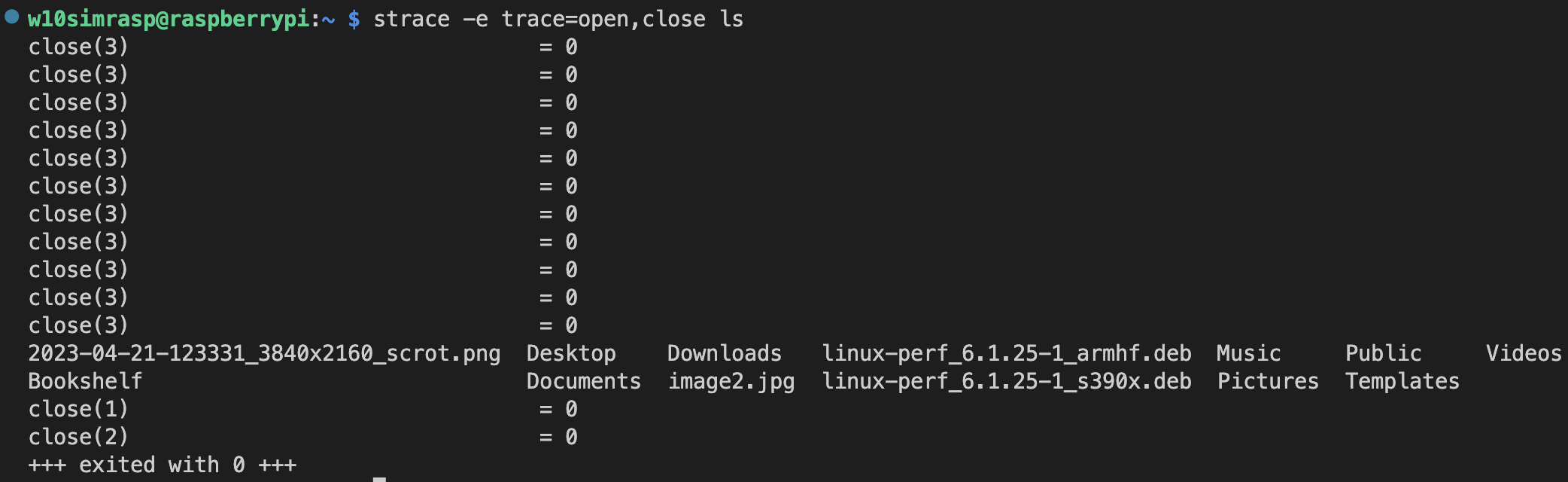
4. strace
- user 레벨 애플리케이션과 system call 관련된 이벤트를 추적하고 기록하는 도구
- System call -> user 와 kernal 간의 인터페이스
- 호출에 실행되는 순서, 전달되는 인자, 반환값 등을 확인 가능
- Syscall 의 이름, 호출 시점, 전달되는 parameters, 반환 값, 오류코드
- Signal과 관련된 이벤트(시그널 발생 및 처리)
몇가지 예제들
- strace -p 1234 -> htop에서 볼 수 있는 pid로 추적
- strace -e trace=open,close ls -> open, close 이벤트만 추적
- strace -o trace_output.txt ls -> trace의 output 을 파일로 저장

5. ftrace
- 커널 내부에서 발생하는 이벤트를 추적하고 분석하는 기능
- 시스템 관리자(sudo or root)만 볼 수 있음
- 커널 함수 호출, 컨텍스트 스위칭, 인터럽트 처리, 스케줄링, 타이머 등등 다양한 이벤트 추적 가능
- 하지만 무겁다
예제
cd /sys/kernel/debug/tracing echo function > current_tracer echo schedule > set_ftrace_filter echo 1 > tracing_on ehco 0 > tracing_on
6. lsof
- 리눅스에서 열린 파일, 디렉토리, 소켓, 파이프 등을 나열해줌
- 리눅스는 모든 것을 파일로 관리하기 때문에 유용
- 프로세스 별로 제공 -lsof
7. eBPF(Extended Brekeley Packet Filter)
- 원래는 packet filtering 을 위해서 개발됨
- 기능이 확장되어서 성능 모니터링 등 다양한 분야에서 사용 가능
- 사용자가 작성한 eBPF 프로그램을 커널 공간에서 안전하게 실행 할 수 있는 구조를 만들어 놓음
- 매우 엄격한 검증 과정을 거치며, 안전하지 않은 프로그램이 실행되는 것을 방지
- 메모리 접근, 무한 루프, 시스템 호출 등을 검사
- 커널에서 발생하는 다양한 이벤트를 추적하고 분석하는 기능을 제공
- 사용자가 커널 기능을 확장하거나 추가 할 수 있는 프레임워크
- 보통 C로 작성되나 python 으로 확장 가능
- 코드를 작성 후, eBPF compiler 를 사용해서 바이트코드로 변환 후, 커널에서 실행 됨
- BCC(BPF Compiler Collection)
2. 디바이스 드라이버를 통한 LED 컨트롤 해보기
1. 디바이스 드라이버란?
- 커널과 하드웨어 디바이스 간의 인터페이스 역할
- 하드웨어의 동작을 관리
- 유저 레벨 어플리케이션과 커널 사이 데이터를 전달하는 역할
- 모듈화 되어 있어 동적으로 삽입 및 제거 가능
2. 디바이스 드라이버의 목적
추상화
- 하드웨어와 소프트웨어 간의 추상화 제공
- 애플리케이션 개발자는 하드웨어에 대한 이해가 부족해도 하드웨어 사용 가능
표준화
- 하드웨어에 대한 표준 인터페이스 정의
- 애플리케이션 개발자는 다양한 하드웨어에 대한 일관된 방식으로 접근 가능
하드웨어 지원
- 디바이스를 사용하기 위한 필요 기능 구현
- 커널이 다양한 하드웨어를 지원한느 것에 큰 도움이 된다
3. 디바이스 드라이버의 종류
문자 다비이스 드라이버
- 순차적으로 접근할 수 있는 디바이스(ex. 시리얼 포트, 키보드)와 통신
- 이 디바이스 드라이버를 통해 데이터를 바이트 단위로 읽고 쓰기가 가능
블록디바이스 드라이버
- 블록 기반의 무작위 접근이 가능한 디바이스(ex. 하드디스크, 플래쉬 메모리)와 통신
- 데이터를 블록 단위로 읽고 쓰기가 가능
네트워크 다바이스 드라이버
- 네트워크 인터페이스 카드(NIC) 같은 네트워크 하드웨어와 통신하는데 사용됨
- 데이터 패킷을 송 수신함
4. 디바이스 드라이버의 예제
- C로 코드를 작성
- 컴파일 후 삽입 또는 제거가 가능
- Make
sudo make install sudo modprobe <module_name> sudo modprobe -r <module_name>

Dev Ops, "Git, Linux, Docker, Kubernetes, ansible, " .