1. Camera module 이용해보기
1. OpenCV, Numpy 설치하기
1. Cpu 일하고 있는지 확인하기
sudo apt-get install htop
2. OpenCV, Numpy 설치하기
sudo apt-get install libcblas-dev sudo apt-get install libhdf5-dev sudo apt-get install libhdf5-serial-dev sudo apt-get install libatlas-base-dev sudo apt-get install libjasper-dev sudo apt-get install libqtgui4 sudo apt-get install libqt4-test sudo apt install python3-opencv pip3 install -U numpy #Optional : sudo apt-get install byobu
2. 카메라 사용해보기
1. 카메라 하드웨어 장착하기
2. 라즈베리파이에서 카메라 활성화하기
1. 라즈베리파이 설정 진입
sudo raspi-config
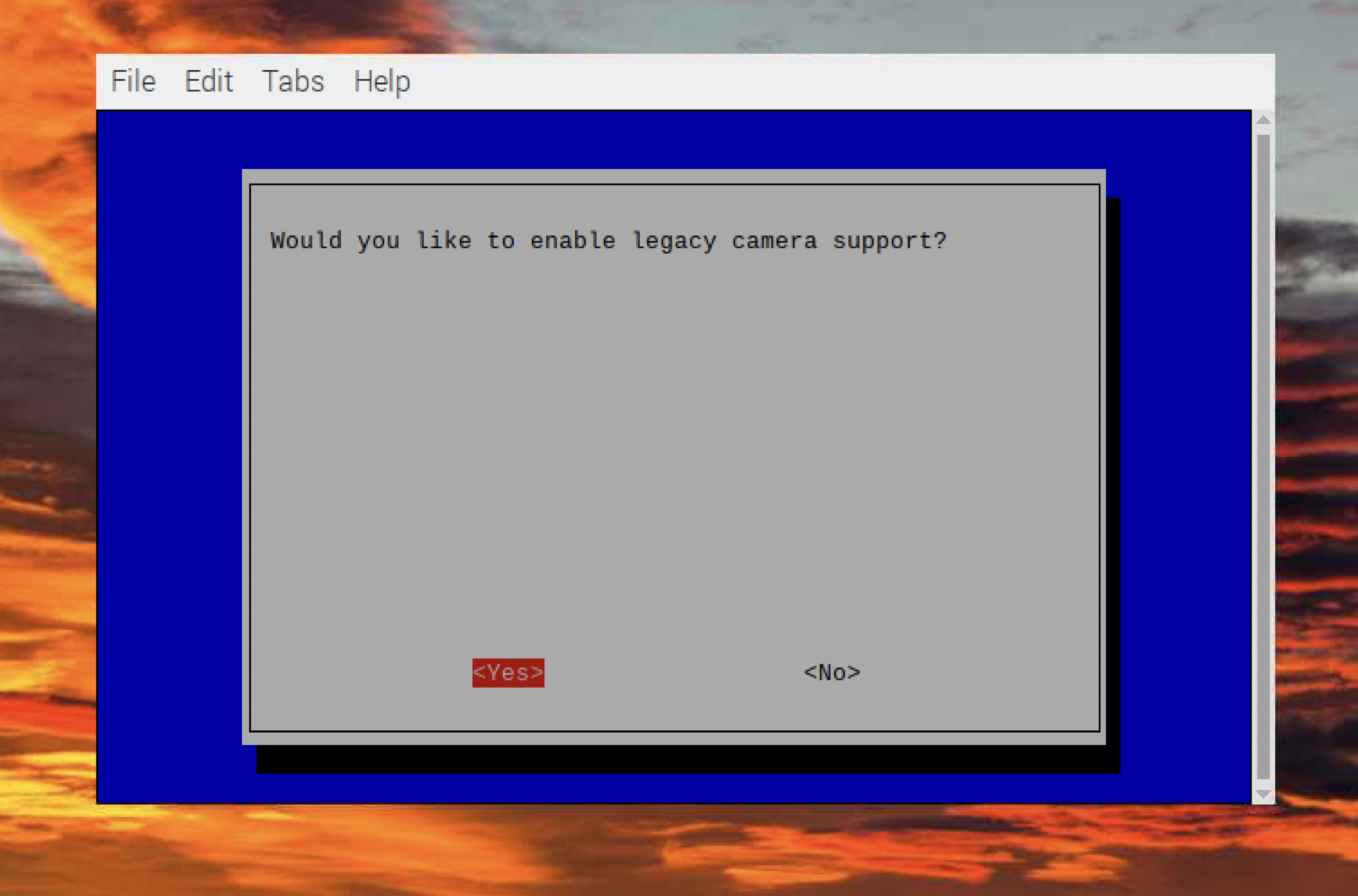
2. Legacy camera -> enable
3. 카메라 정상 작동하는지 확인하기
1. 사진 찍기
raspistill -o Desktop/image.jpg바탕화면에 image.jpg 가 생성되면 성공
2. 비디오 찍기
raspivid -o Desktop/video.h264바탕화면에 video.h264 가 생기면 성공
4. 카메라 모듈을 이용한 프로그래밍
1. 카메라 작동 확인
from picamera import PiCamera from time import sleep camera = PiCamera() camera.start_preview() sleep(5) camera.stop_preview()
2. OpenCV + Python 을 이용해 카메라 모듈 사용해보기
1. OpenCV란?
- OpenCV -> Open Sourve Computer Vision
- 컴퓨터 비전 하시는 분들이 같이 만든 Vision 관련 패키지
2. OpenCV import 해보고 패키지에 이상이 없는지 확인해보기
import cv2
cap=cv2.VideoCapture(0,cv2.CAP_V4L)
ret, frame = cap.read()
if ret:
cv2.imwrite('image2.jpg', frame)
cap.release() 3. 카메라 모듈로 원 색출하기
import cv2 as cv
videoCapture = cv.VideoCapture(0)
while True:
ret, frame = videoCapture.read()
#하드웨어 오류 검출
if not ret: break
gray = cv.cvtColor(frame, cv.Color_BGR2GRAY)
blur = cv.GaussianBlur(gray, (15,15),0)
circles = cv.HoughCircles(blur, cv.HOUGH_GRADIENT, 2, 100, param1 = 100, param2 = 100, minRadius=35, maxRadius = 500)
if circles is not None:
print(circles)
videoCapture.release() 4. 카메라 모듈로 원 색출해서 원이 나타나면, GPIO 를 이용해 LED 깜빡이기
코드
import cv2 as cv
import RPi.GPIO as rg
import time
rg.setmode(rg.BCM)
ledPlusPin1 = 27
rg.setup(ledPlusPin1, rg.OUT)
videoCapture = cv.VideoCapture(0)
try:
while True:
ret, frame = videoCapture.read()
#하드웨어 오류처리
if not ret: break
rg.output(ledPlusPin1, rg.LOW)
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
blur = cv.GaussianBlur(gray, (15,15),0)
circles = cv.HoughCircles(blur, cv.HOUGH_GRADIENT, 2, 100, param1 = 100, param2 = 100, minRadius=35, maxRadius = 500)
if circles is not None:
rg.output(ledPlusPin1, rg.HIGH)
#순간 빤짝이면 보기가 힘들어 3초 sleep
time.sleep(3)
print(circles)
except KeyboardInterrupt:
videoCapture.release()
rg.cleanup()
2. 임베디드 시스템의 특성, 최적화 해보기
1. Embedded System 이란?
- 특별한 용도가 있는 효율적인 시스템
- 용도에 맞는 최적화된 시스템
-> 특별한 용도에 맞게 다각도록 최적화된 시스템
2. 최적화란?
- 특정한 목적을 가지고, 계획을 세우고 계획을 코드로 실현하는 일
- 분야마다, 프로젝트마다 할 수 있는, 하고자 하는 최적화가 다르다
- 최적화의 방향 (최대 성능, 최소 리소스/최대 효율 또는 둘 다)
고려할 사항
- 우리가 이용가능한 리소스(하드웨어)는?
- 우리의 타겟 어플리케이션은?
- 최적화의 목표는?
3. 리눅스 운영체제에서 관리하는 자원들
1. CPU(Core Process Unit, 중앙 처리 장치)
2. DRAM(Dynamic random access memory, 메모리)
4. 코드로 확인해보기
1. Process 만들어보기
process.c
#include<stdio.h>
#include<time.h>
int main(){
int i = 0;
int ret = 0;
for(i=0;i<100000000000000;i++)
ret += 1;
return 0;
}C코드 컴파일 하고 실행해서 htop 명령어로 CPU 사용량 보기
gcc -o process process.c
./process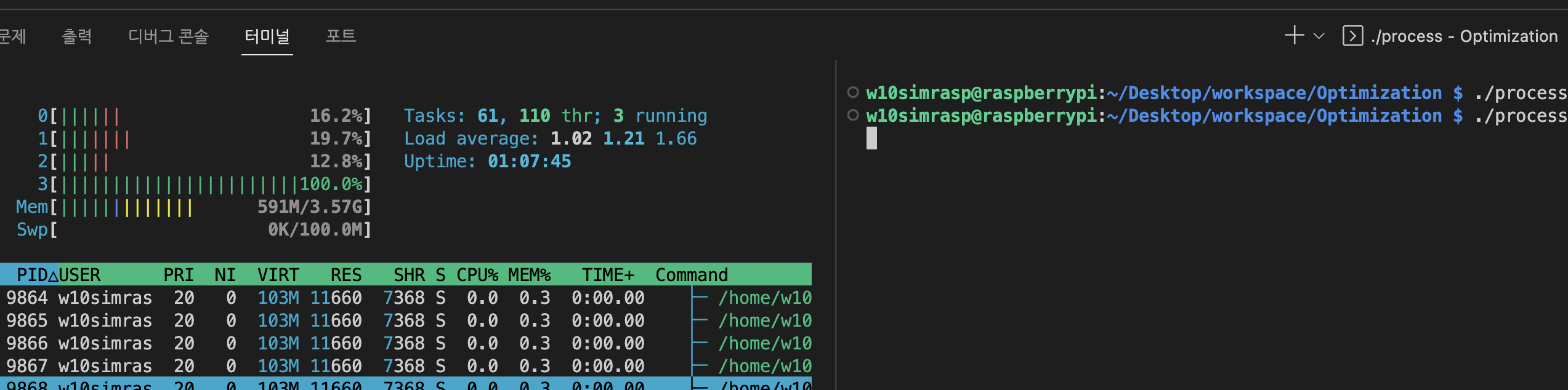
time 명령어 통해 프로세스가 종료될때까지 걸리는 시간 측정하기

5. 최적화 해보기
최적화의 3가지 방법
- 하드웨어를 바꾸기
- 애플리케이션 레벨 최적화 ex) Multi-Threading
- OS 레벨 최적화 ex) cpu frequency
1. SU(Super User) 권한 얻기
exit 명령어를 통해 다시 내 계정으로 돌아 갈 수 있음
sudo su
2. cpu 확인하기
ls /sys/devices/system/cpu3. CPU governor
1. CPU governor란?
디바이스가 전력소비를 어떻게 할지 결정해서 정책을 만들어 놓는 것
2. CPU governor의 powersave 사용해보기
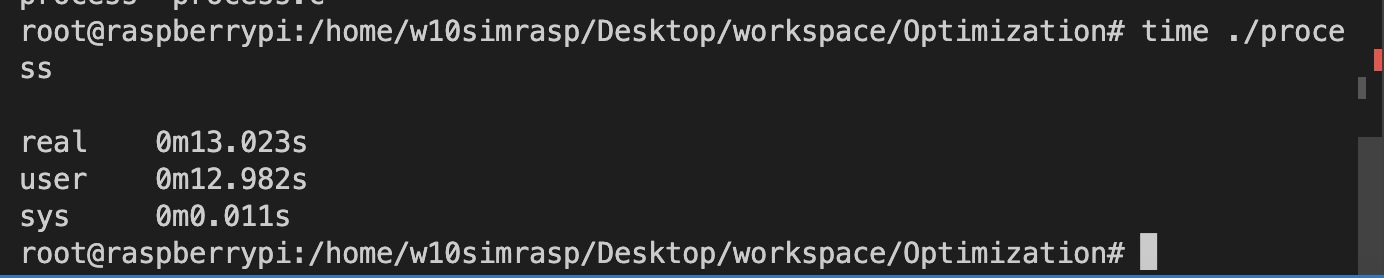
//라즈베리파이에는 cpu0, cpu1, cpu2, cpu3이 있으므로 echo powersave > /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor echo powersave > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor echo powersave > /sys/devices/system/cpu/cpu3/cpufreq/scaling_governor아래와 같이 프로세스가 종료되기까지 더 오랜 시간이 걸렸음을 확인
4. Multi-thread 이용해보기
Multi-thread 란?
- 우리가 실행하는 흐름은 보통 한 줄기의 흐름의 코드
- 하지만 여러개의 worker(cpu)가 있다면
- 동시에 실행해도 괜찮은 작업은 여러개의 Worker에서 처리해도 괜찮지 않을까?
1. Multi-thread를 이용해보기 위한 코드
process_thread.c
간단한 멀티 스레드 프로그래밍
1. 2개의 thread를 이용해서 실행하는 코드
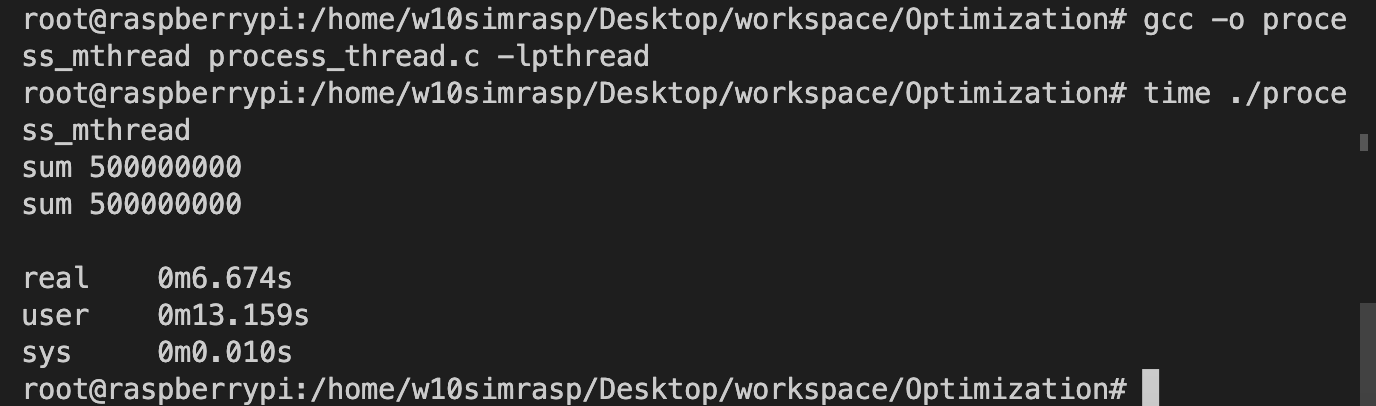
2. gcc -o process_mthread process_thread.c -lpthread
-lpthread : pthread 라는 라이브러리를 사용할 것이라고 gcc 컴파일러에게 명시
3. time ./process_mthread
#include <stdio.h>
#include <pthread.h>
#define NUM_THREADS 2
#define MAX_NUM 1000000000
void *summing(void *arg) {
int start = 0;
int end = start + MAX_NUM/NUM_THREADS;
int sum = 0;
for (int i = start; i < end; i++) {
sum += 1;
}
printf("sum %d\n",sum);
pthread_exit(NULL);
}
int main() {
pthread_t threads[NUM_THREADS];
int thread_args[NUM_THREADS];
int i;
for (i = 0; i < NUM_THREADS; i++) {
pthread_create(&threads[i], NULL, summing, &thread_args[i]);
}
for (i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
return 0;
}
5.리눅스에서 DRAM 을 관리하는 방법
- DRAM 의 크기는 비교적 작고 한정됨
- 우리는 한번에 수백~수천 개의 애플리케이션을 동시에 동작시키고 싶음
1. 리눅스에서는 Demand Paging 기법을 사용
- Page Fault -> 내가 가지고 있다고 생각한 메모리에 접근했는데 데이터가 없음
- OS -> 너가 가지고 있다고 생각한 가상 메모리와 실제 물리 메모리 연결
2. Demand Paging 실습해보기
demand_paging.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/mman.h>
#define PAGE_SIZE 4096
#define MEM_SIZE (1ul << 30) //1GB
#define STEP_SIZE (100ul << 20) //100MB
int main() {
char *mem = mmap(NULL, MEM_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (mem == MAP_FAILED) {
perror("mmap failed");
exit(EXIT_FAILURE);
}
size_t step_offset = 0;
size_t touched_size = 0;
while (touched_size < MEM_SIZE) {
memset(mem + step_offset, 0, STEP_SIZE);
touched_size += STEP_SIZE;
printf("Touched %lu MB\n", touched_size >> 20);
if (touched_size < MEM_SIZE) {
printf("Press enter to continue to next step...");
getchar();
}
step_offset += STEP_SIZE;
}
if (munmap(mem, MEM_SIZE) == -1) {
perror("munmap failed");
exit(EXIT_FAILURE);
}
return 0;
}6. 터미널이 종료되어도 현재 작업 상태를 남겨놓고 싶을때
sudo apt-get install byobu7. 파이썬을 이용한 Multi-thread, Multi-process
파이썬 멀티 쓰레드(thread)와 멀티 프로세스(process)
1. Multi-thread
코드
import threading import time NUM_THREADS = 4 MAX_NUM = 1000000000 def summing(): sum = 0 for i in range(int(MAX_NUM/NUM_THREADS)): sum += 1 print(sum) #쓰레드 목록 threads = [] #쓰레드 생성, 시작 for i in range(NUM_THREADS): t = threading.Thread(target=summing) t.start() threads.append(t) # 먼저 시작된 쓰레드가 종료되고 프로그램이 종료되는 것을 막기 위해 각 쓰레드에 # join()을 사용하여 threading이 끝날때까지 기다린다. for thread in threads: thread.join()
파이썬을 이용한 Multi-Threading 결과
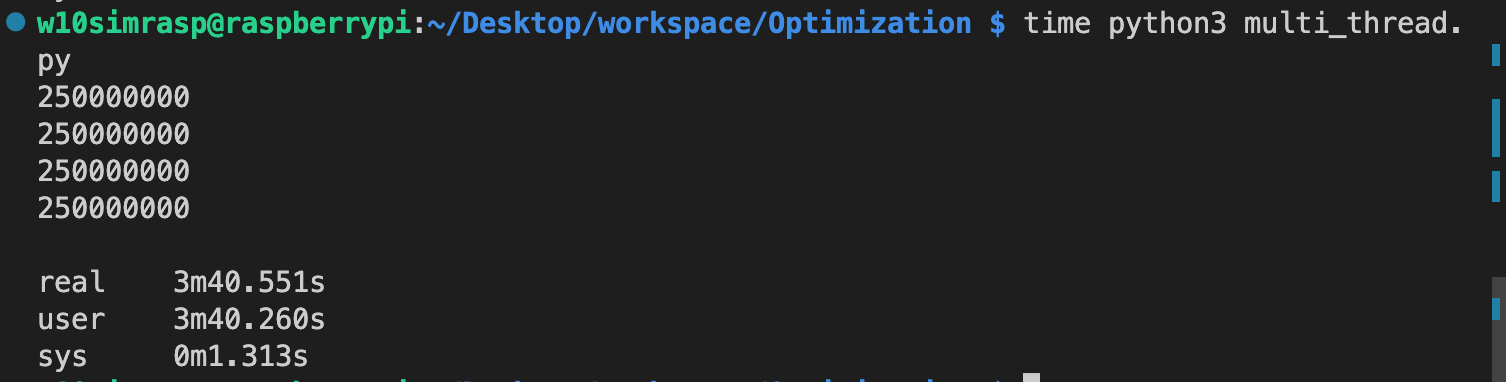
4개의 멀티쓰레드를 이용하였을떄
4개의 멀티쓰레드를 이용하여도 realtime이 user time 과 같은 모습이다
1개의 쓰레드를 이용하였을때
1개의 쓰레드를 이용하였을때 오히려 real time 과 user time이 감소하였다

그 이유는?
1.C언어로 구현한 Multi-thread 프로그램에서는 n개의 쓰레드를 사용한 경우 real time 은 user time의 1/n 의 결과를 보여주었다.
2. 파이썬에서는 n개의 쓰레드를 이용할 경우에도 real time 과 user time 이 동일하였다.
3. 심지어 Multi-thread를 사용하지 않는 경우에 더 짧은 실행시간을 보였다.
4. 그 이유는 파이썬의 GIL(Global Interpreter Lock) 정책 때문파이썬의 GIL(Global Interpreter Lock) 이란?
언어에서 자원을 보호하기 위해 락(Lock) 정책을 사용하고 그 방법 또한 다양하다. 파이썬에서는 하나의 프로세스 안에 모든 자원의 락(Lock)을 글로벌(Global)하게 관리함으로써 한번에 하나의 쓰레드만 자원을 컨트롤하여 동작하도록 한다.
위의 코드에서 sum 이라는 자원을 공유하는 두 개의 쓰레드를 동시에 실행시키지만, 결국 GIL 때문에 한번에 하나의 쓰레드만 계산을 실행하여 실행 시간이 비슷한 것이다.
GIL 덕분에 자원 관리(예를 들어 가비지 컬렉팅)를 더 쉽게 구현할 수 있었지만, 지금처럼 멀티 코어가 당연한 시대에서는 조금 아쉬운 것이 사실이다. 그렇다고 파이썬의 쓰레드가 쓸모 없는 것은 아니다. GIL이 적용되는 것은 cpu 동작에서이고 쓰레드가 cpu 동작을 마치고 I/O 작업을 실행하는 동안에는 다른 쓰레드가 cpu 동작을 동시에 실행할 수 있다. 따라서 cpu 동작이 많지 않고 I/O동작이 더 많은 프로그램에서는 멀티 쓰레드만으로 성능적으로 큰 효과를 얻을 수 있다.
2. Multi-process
코드
import multiprocessing NUM_PROCESS= 4 MAX_NUM = 1000000000 def summing(): sum = 0 for i in range(int(MAX_NUM/NUM_PROCESS)): sum += 1 print(sum) #프로세스 목록 processes = [] #쓰레드 생성, 시작 for i in range(NUM_PROCESS): p = multiprocessing.Process(target=summing) p.start() processes.append(p) # 먼저 시작된 프로세스가 종료되고 프로그램이 종료되는 것을 막기 위해 각 프로세스에 # join()을 사용하여 processing이 끝날때까지 기다린다. for process in processes: process.join()
파이썬을 이용한 Multi-processing 결과
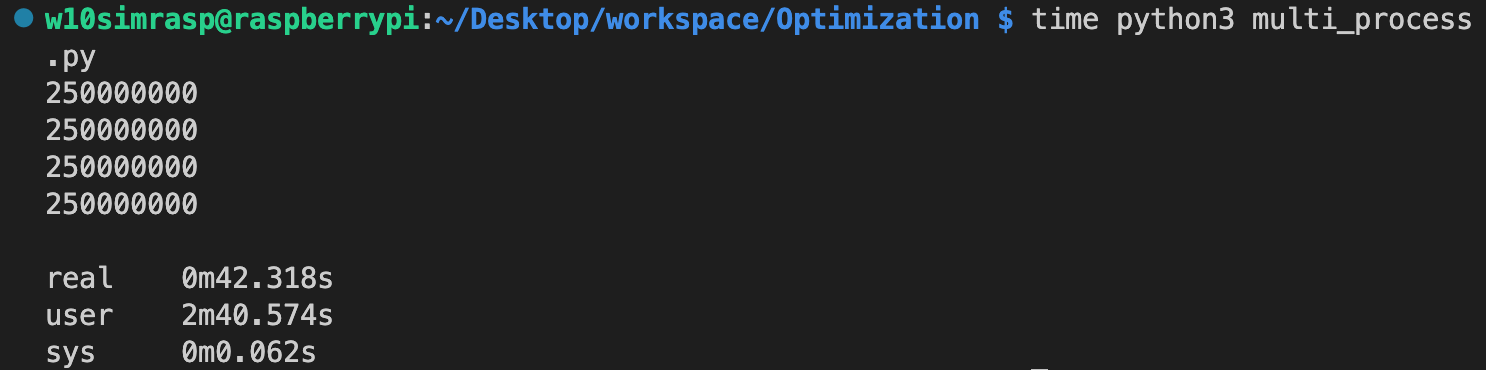
4개의 멀티프로세스를 이용하였을떄
4개의 멀티프로세스를 이용하였을때 real time 은 user time 의 1/4의 시간을 보여준다
1개의 프로세스를 이용하였을때
1개의 프로세스를 이용하였을떄 real time 은 user time 과 동일한 시간을 보여준다

3. 결론
Thread Vs Process
결론적으로 말하자면, 파이썬에서 병렬처리를 구현하는 방식은 두가지로 멀티 쓰레드를 사용하거나 멀티 프로세스를 사용하는 것이다. 쓰레드는 가볍지만 GIL로 인해 계산 처리를 하는 작업은 한번에 하나의 쓰레드에서만 작동하여 cpu 작업이 적고 I/O 작업이 많은 병렬 처리 프로그램에서 효과를 볼 수 있다.
프로세스는 각자가 고유한 메모리 영역을 가지기 때문에 더 많은 메모리를 필요로 하지만, 각각 프로세스에서 병렬로 cpu 작업을 할 수 있고 이를 이용해 여러 머신에서 동작하는 분산 처리 프로그래밍도 구현할 수 있다.
각자의 장단점을 고려하여 자신의 프로그램에 잘 맞는 방식을 사용해야 한다.
