프로파일링 툴 사용해보기
problem1
코드
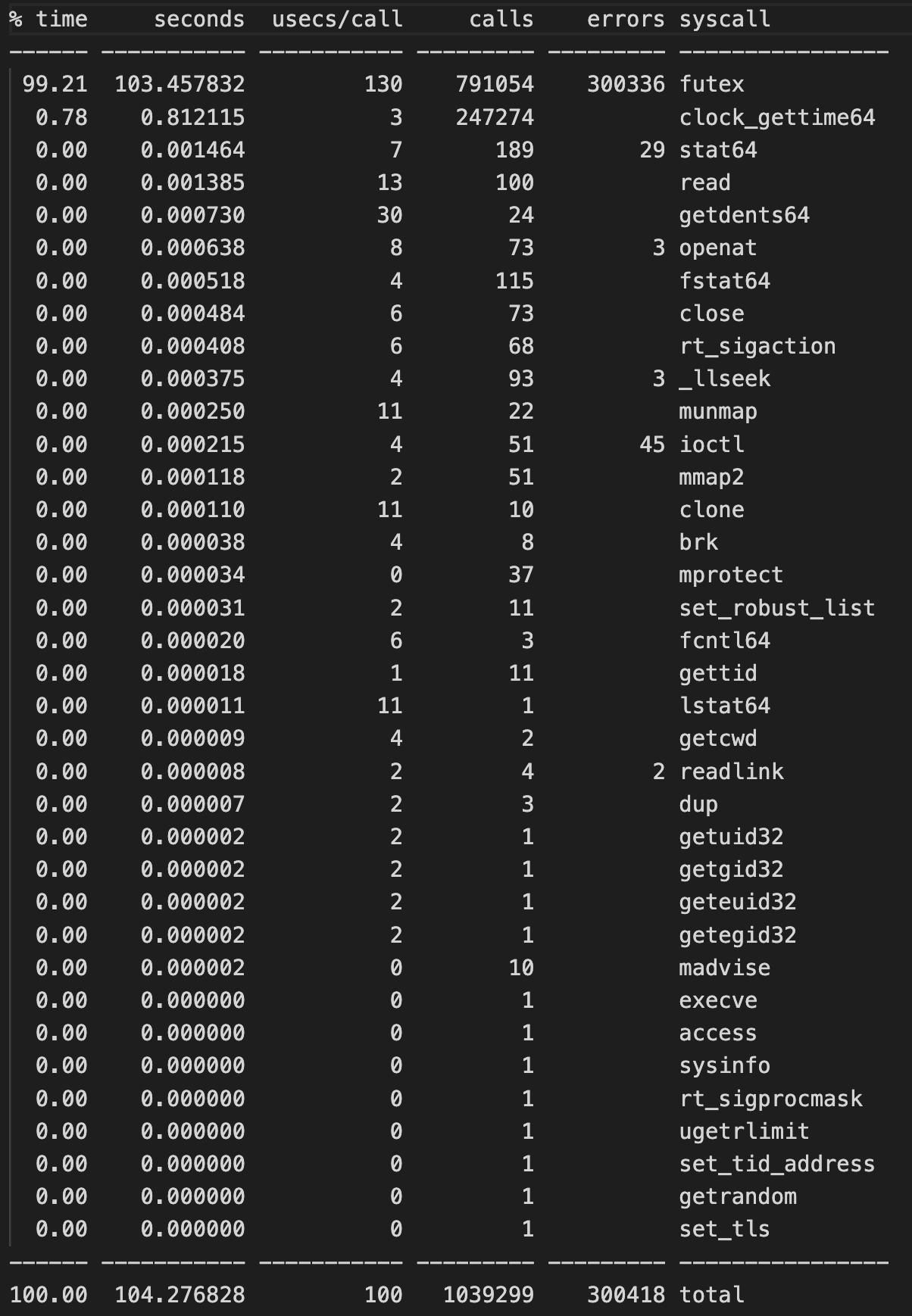
import threading import time def busy_loop(): count = 0 while count < 10**8: count += 1 threads = [] for _ in range(10): t = threading.Thread(target=busy_loop) t.start() threads.append(t) for t in threads: t.join()strace 결과
문제점
최적화 방법
problem 2
코드
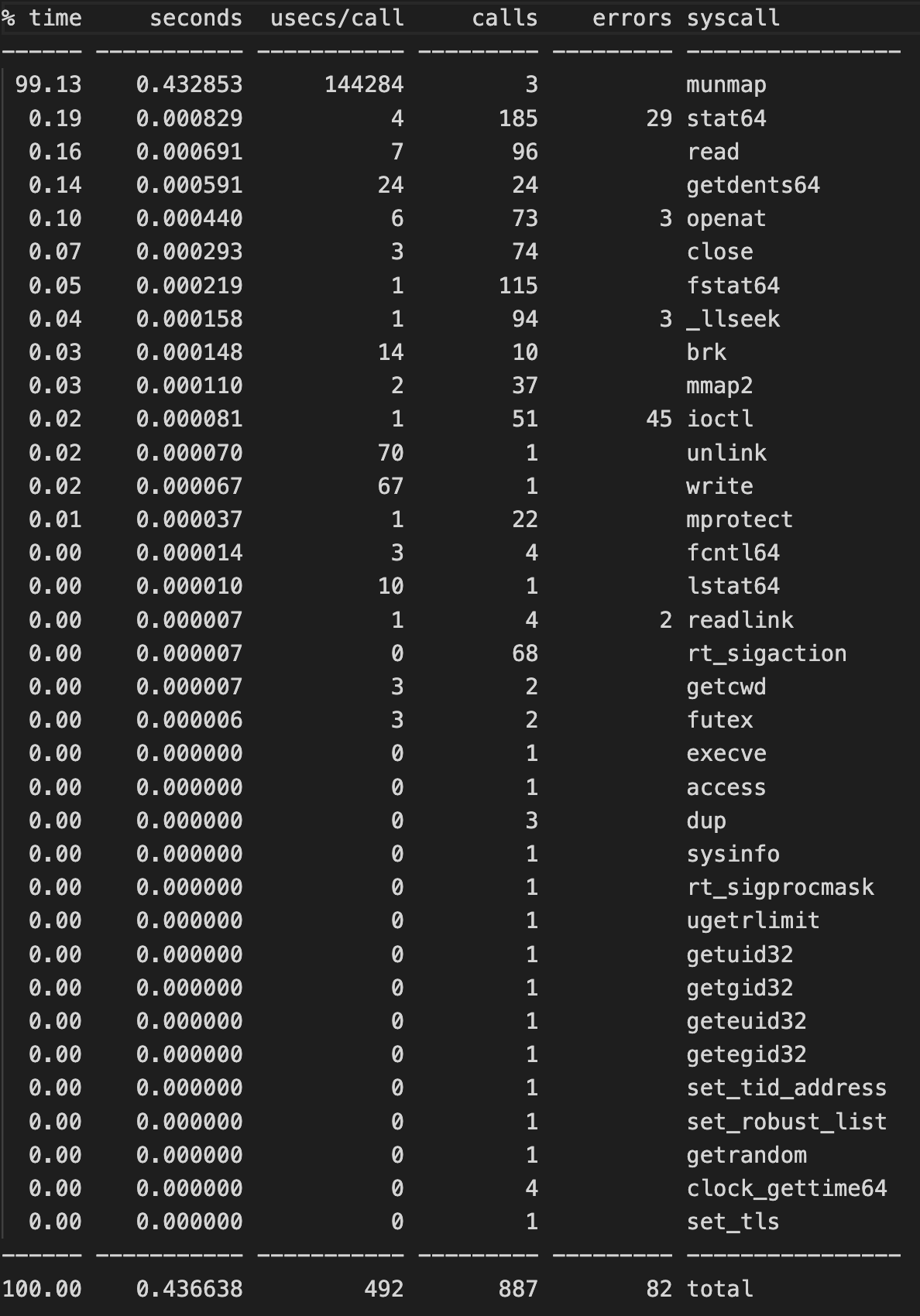
import os import mmap file_size = 10**9 # 1 GB file_name = "large_file.dat" with open(file_name, "wb") as f: f.seek(file_size - 1) f.write(b"\0") with open(file_name, "r+b") as f: mmapped_data = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_WRITE) for i in range(0, file_size, 4096): mmapped_data[i] = 0 os.remove(file_name)strace 결과
문제점
최적화 방법
problem 3
코드
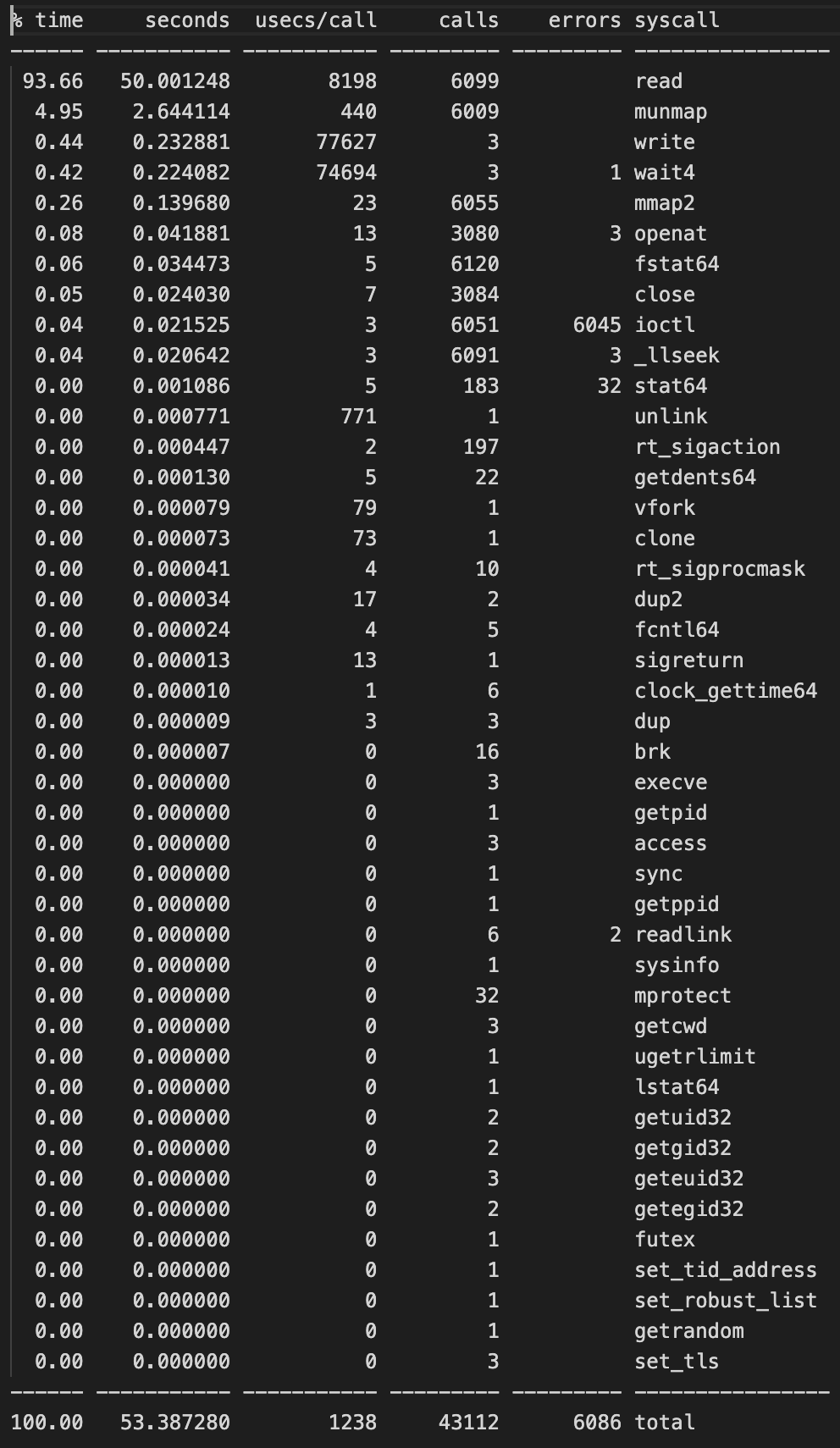
import os import time def main(): num_iterations = 3000 file_name = "test_file.txt" # 파일 생성 with open(file_name, "w") as f: f.write("This is a test file for I/O overhead example.\n" * 100000) # 캐시 삭제 os.system("sync; echo 3 > /proc/sys/vm/drop_caches") # 파일 읽기 반복 start_time = time.time() for _ in range(num_iterations): with open(file_name, "r") as f: f.read() end_time = time.time() print(f"Total time for {num_iterations} iterations: {end_time - start_time:.2f} seconds") # 파일 삭제 os.remove(file_name) if __name__ == "__main__": main()strace 결과
문제점
최적화 방법
problem 4
코드
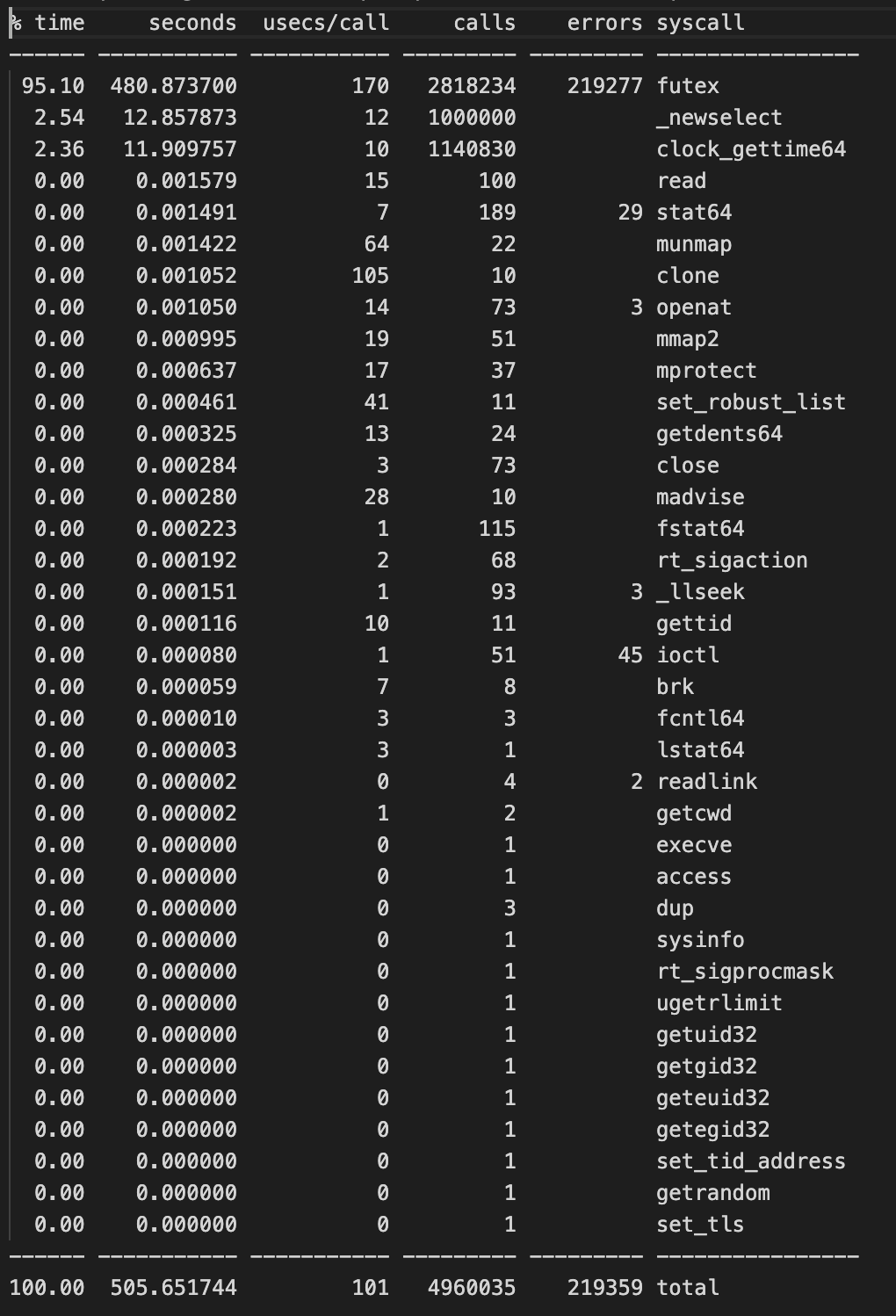
import threading import time lock = threading.Lock() def resource_competing_thread(): for _ in range(100000): with lock: time.sleep(0.0001) threads = [] for _ in range(10): t = threading.Thread(target=resource_competing_thread) t.start() threads.append(t) for t in threads: t.join()strace 결과
문제점
최적화 방법

Dev Ops, "Git, Linux, Docker, Kubernetes, ansible, " .