[Paper Review]RandAugment: Practical automated data augmentation with a reduced search space
해당 포스트에서는 Data Augmentation 기법 중 하나인 RandAugment에 대해서 다룹니다.
Background
Data Augmentation은 Model Generalization을 위해 필수적인 방법이다. 하지만 Task Domain에서 적절한 Augmentation을 찾기 위해선 사전 지식이 필요할 뿐더러 많은 Cost(time, resource)가 필요하다.
예를 들어 AutoAugment 기법은 Reinforcement Learning을 통해 여러가지 Policy(Augmentation Combination)에 대한 Reward를 받아 Task Domain에 대한 적절한 Policy을 만들어낸다. 하지만 Reward를 통해 Policy를 찾기 위해선 많은 Cost를 필요로한다. 그로 인해 많은 연구를 통해 Cost를 많이 사용하지 않고 적절한 Policy을 사용하여 준수한 학습 성능을 보이는 RadnAugment 기법을 고안했다.
RandAugment
위 방법론을 제안한 논문에서는 14개의 Augment 기법을 2개의 파라미터만 사용하여 Random하게 적용한다. 14개의 Augment는 다음과 같다.

2개의 파라미터는 Augment 적용 개수를 결정하는 N, Augment의 magnitude(강도, 세기라고 이해하면 될 듯)를 결정하는 M으로 이루어져있다. 정리하면 M의 세기로 N개의 Random Augment를 Data에 적용하는 아주 간단한 방법이다.
다음 사진은 N=2이고 M을 9, 17, 28의 결과이다. 2개의 Augment(사진에선 ShearX, AutoContrast 적용)가 M값에 따라 강하게 적용된다.
 코드를 직관적으로 표현하였을때도 매우 간단한 구조로 나타낼 수 있다.
코드를 직관적으로 표현하였을때도 매우 간단한 구조로 나타낼 수 있다.

Experiment
아래의 표를 보면 알 수 있듯이 많은 cost를 사용하는 Augment 기법과 동등하거나 더 나은 성능을 보이고 있다.
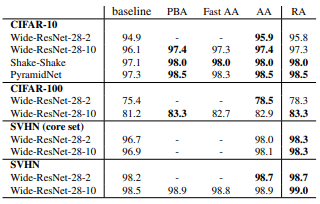
논문에서 주장하는 바로는 모델, 데이터셋의 크기에 따라 파라미터를 다르게 주어야 효과가 있다고 한다.
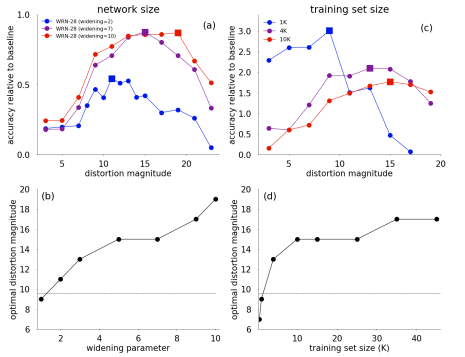 위의 그림 중 (a)를 보면 모델의 사이즈가 클수록 큰 magnitude가 효과적인 것을 보여준다. (c)는 training data가 많을 시 큰 magnitude가 효과적인 것을 보여준다. 대신 적은 data에서는 적당한 magnitude가 효과적이다(그래프를 보면 1K training set에서 magnitude=10에서 제일 성능이 좋음).
위의 그림 중 (a)를 보면 모델의 사이즈가 클수록 큰 magnitude가 효과적인 것을 보여준다. (c)는 training data가 많을 시 큰 magnitude가 효과적인 것을 보여준다. 대신 적은 data에서는 적당한 magnitude가 효과적이다(그래프를 보면 1K training set에서 magnitude=10에서 제일 성능이 좋음).
결론적으로 모델과 데이터셋의 사이즈가 클수록 magnitude를 높게 주어야 좋은 학습 성능을 보여준다.
마무리..
NIPA에서 주최하는 2022 온라인 인공지능 경진대회에 참가하면서 사용한 기법인데 굉장한 성능 향상(Final Rank 4위)을 보여주어서 블로그로 내용을 담아두고 싶었다. 코드로 구현하여도 매우 간단하므로(torchvision transform 모듈에 구현돼있음) 연구를 하시면서 간단하게 성능을 올리고 싶거나 캐글 등 Data Science 대회를 출전하시는 분은 꼭 적용해 보았으면 한다.
Reference
Paper : https://arxiv.org/abs/1909.13719
