
주제
(9월21일~25일) 총 3일간 3차 미니프로젝트가 진행되었다!
프로젝트 전 5일동안 시각지능 딥러닝 강의를 수강하였고 이를 바탕으로
저시력자들을 위한 원화 화폐 분류 라는 주제의 미니프로젝트를 수행하였다.
진행과정
- 미션의 key point
- 모델에 맞는 폴더 구조 확인
- 이미지 축소 비율에 맞춰 좌표값 변경
(좌표를 이미지 리사이즈한 비율로 변경)- 모델에 맞는 정보 추출/형식 변경
(json 파일에서 정보 추출 및 모델 형식에 맞게 변경)- 화폐당 하나의 클래스로 변경
(총 8개 클래스)- 모델 선택 필요
데이터 전처리
- 데이터 분할 및 이동
a. 화폐 단위마다 8:2로 데이터를 분할
b. 분할한 데이터 파일 train, val 폴더로 복사
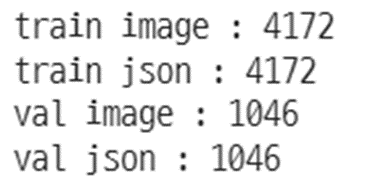
c. train data 4172개, validation data 1046개로 총 5218개의 데이터를 확인했다.
-
json 파일 정보 추출
a. 사용되는 이미지는 원본파일의 1/5 사이즈이므로 위치 정보 추출 시 x,y 값 또한 1/5로 축소
b. Min-Max Normalization을 통해 기존 Bounding Box 좌표 값을 YOLO Style인 이미지 크기에 대한 비율 값으로 변경
c. label 값을 Zero-Indexing 한다.


-
yaml 파일 생성 (가장 대중적으로 이용하는 라이브러리)
a. 데이터 집합에 대한 정보, 클래스 이름, 훈련 및 검증 세트의 경로를 저장하기 위한 yaml 파일 (money.yaml)을 생성

모델링
- YOLOv5 객체 탐지 모델 사용하기
model.train(data='/content/Dataset/money.yaml',
epochs=30,
patience=5,
save=True,
project='trained_money',
name='trained_money_model',
exist_ok=False,
pretrained=True,
optimizer='auto',
verbose=False,
resume=False,
freeze=None,
)- YOLOv5 summary
a. Layers: 262
b. Parameters: 9125288
c. Gradients: 9125272
d. Optimizer: AdamW(lr=0.000833, momentum=0.9)
탐지
-
모델 성능 분석
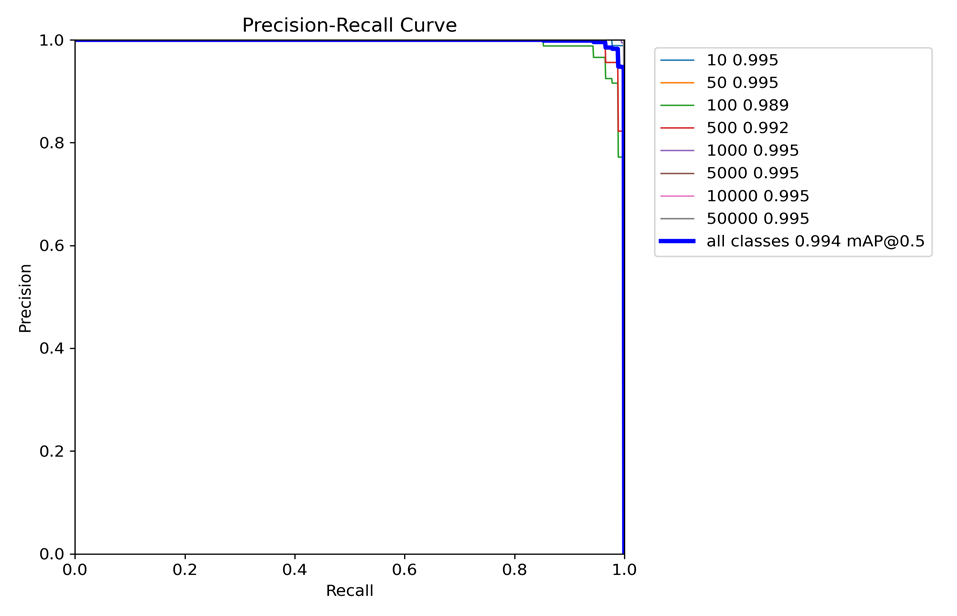
a. PR-curve(mAP)
-
Predict 결과



결론
-
Training Data Set, Validation Data Set을 보았을 때 회전, 접힙 등과 같은 변형이 없는 반듯한 이미지와 객체가 하나만 있는 이미지를 갖고 있는 data set이었다.
-
predict 진행 시, 다양한 각도, 회전 그리고 겹침이 있는 data는 성능이 낮음을 확인하였다.
느낀 점
-
data set을 구성할 때, 다양한 이미지 data set으로 구성하면 더 성능이 좋게 나왔을 것 같았고 모델을 돌릴 때 전처리 과정이 중요하다는 것을 다시 한번 더 느꼈다.
-
시각지능 딥러닝 수업을 다른 일정 때문에 나중에 몰아들었는데 생각보다 많이 어려웠던 것 같다. ಥ_ಥ
몰아듣지 말고 그때그때 제대로 듣자 ^^,, , -
YOLOv5 모델에 대해 알 수 있었다. 추후에 따로 모델에 대해 따로 정리해서 올릴 수 있도록 하겠당.
