
미니프로젝트 구성
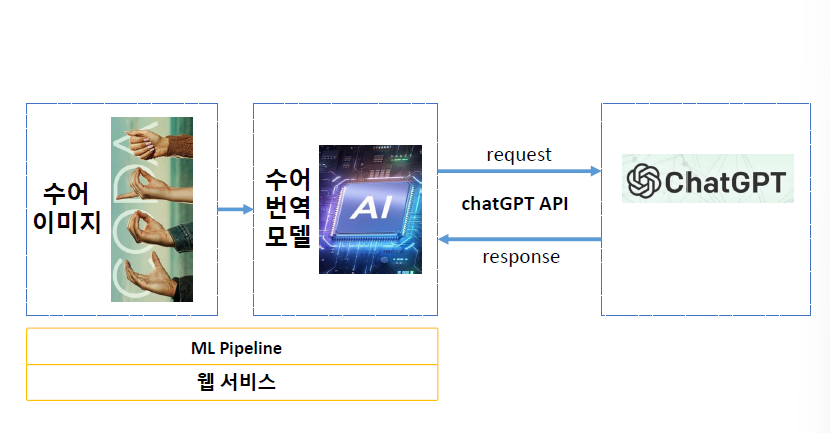
✅ChatGPT API를 이용한 수어 이미지 번역 모델을 제작하여 웹 서비스를 구성해 보는 프로젝트를 진행하였다.
진행 순서
프로젝트는 이와 같은 순서로 진행하였다.
1. ML Pipeline 구축
2. 서버 세팅
3. 웹서비스 데모 구현
ML Pipeline 구축
DataPipeline 구축
MLOps 설정하기
✅가상환경 설정하기
-> ml_pipeline을 만들어보자.
🔹가상환경 생성
conda create -n ml_pipeline python=3.10🔹가상환경 접속
conda activate ml_pipeline🔹필요한 라이브러리 설치
requirements.txt 파일에 설치가 필요한 라이브러리를 작성해둠.
mlflow
opencv-python
Pillow
Django
tensorflow-cpu
openai
pip install -r requirements.txtCRISP-DM Review
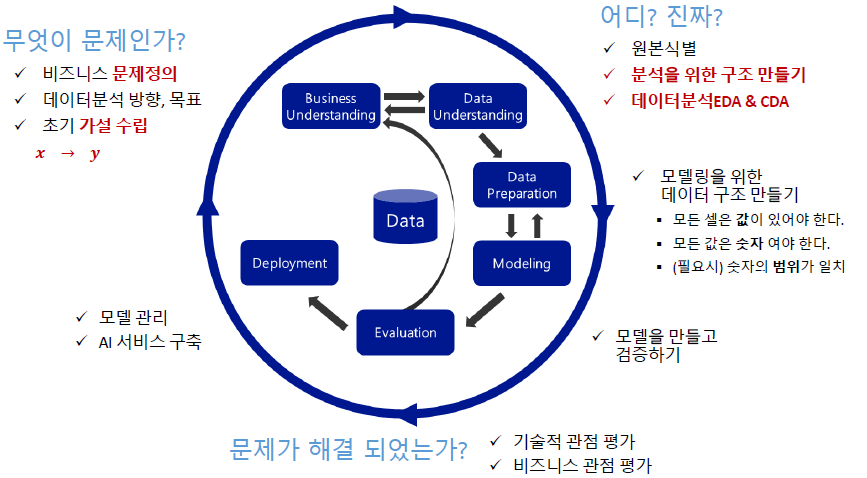
Pipeline과 MLOps
💡MLOps란?
Machine Learning + Dev + Ops
기계학습 운영을 위한 프로세스, 도구 및 방법론을 뜻한다.
기계학습 모델을 개발, 배포, 관리 및 유지 보수하는 전체 생명주기를 지원하는 자동화된 프로세스이다.
✅MLOps 구성요소
데이터 관리, 모델 개발, 모델 배포, 모니터링 및 유지보수
✅Pipeline의 필요
운영시스템을 상상해 보았을 때, 운영시스템에서는 데이터 발생부터 예측 결과까지는 물 흐르듯이 흘러가야 한다.
이런 구성을 pipeline이라고 부른다.
데이터 전처리 for Pipeline
✅Data Pipeline에서 가장 중요한 초점
모델이 생성된 이후, 새로운 데이터(raw data)로 예측할 때에 그 데이터는 모델이 학습 될때의 구조와, 값의 의미가 동일해야한다.
그래서 pipeline은 새로운 데이터가 흘러 들어가서 학습될 때의 구조와 의미로 만들어야 한다.
✅데이터 분할
데이터를 분할하는 이유는 일반화된 성능을 얻기 위함이다.
test 데이터는 처음부터 떼어놔야 한다.(raw data)
✅train과 validation의 비율
train과 validation 비율을 정하는데 정답은 없지만 train의 size는 중요하다. trainin set의 크기가 커지면(데이터가 많으면) 모델 성능이 향상된다.
다만 더이상 성능이 향상되지 않는 지점을(가성비가 좋은 지점) 찾아 적절한 train size를 구하는 것이 중요하다.
✅가변수화
범주의 종류는 데이터를 보고 파악하기 보다는 사전에 결정된다.
(범주의 갯수는 이미 정해둠, 데이터를 보고 파악하는게 아니다.)
데이터 이해 단계에서 범주형 변수에 대해서는 범주의 종류를 사전에 정리해야한다. 카테고리를 지정!
✅Scaling
값의 범위를 맞춰 주기 위해서 변수 값 조정
방법 1: Normalization(정규화)
-> 모든 값의 범위를 0~1로 변환
방법 2: Standardization(표준화)
-> 모든 값을 평균=0, 표준편차=1로 변환
이상치가 극단적으로 존재하는 경우에는 표준화를 사용한다.
실제에서는 둘 다 test 해 볼 필요가 있다.
스케일링하면 분포는 변하지 않고 범위를 맞추게 된다.
✅NaN이란?
💡사용할 수 없는 값, 잘못 들어간 값, 빈값을 뜻함.
-
제거
행 삭제 -> 운영에서 다시 NaN이 발생되지 않을 때!
열 삭제 -> 중요하지 않은 feature일 때 ! -
채우기
범주형 -> 최빈값, 기본값, fillna
숫자형 -> 평균, 중앙값, fillna, sklearn.impute(선형 보간법) -
분리하기
✅Data Pipeline 정리
데이터 분할 후 스케일링
train set만 fit_transform!
val이랑 새로 들어온 데이터들은 transform 해주기
- 데이터 상관없이 미리 정의되어야하는 코드 정리하기
- 새로운 데이터가 들어 왔을 때, 처리되는 절차 코드 정리하기
