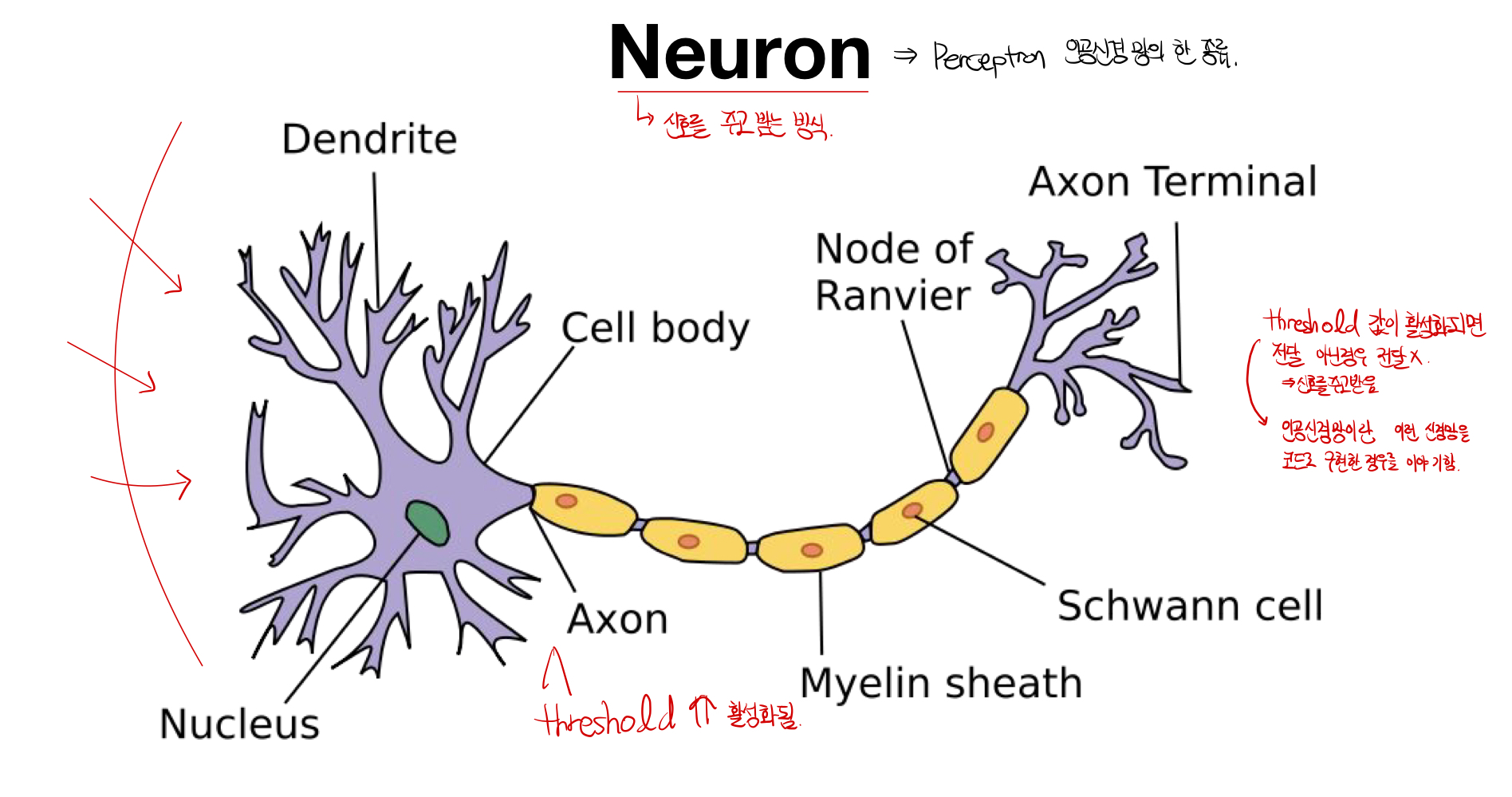
Neuron의 동작 원리: 신경망이라고 불리우며, threshold의 값이 일정 값 이상 전달되면 활성화되어 전달이 되고, 이외의 경우는 신호가 전달되지 않는다. 이러한 원리를 통해서 뉴런끼리 신호를 주고 받는다.
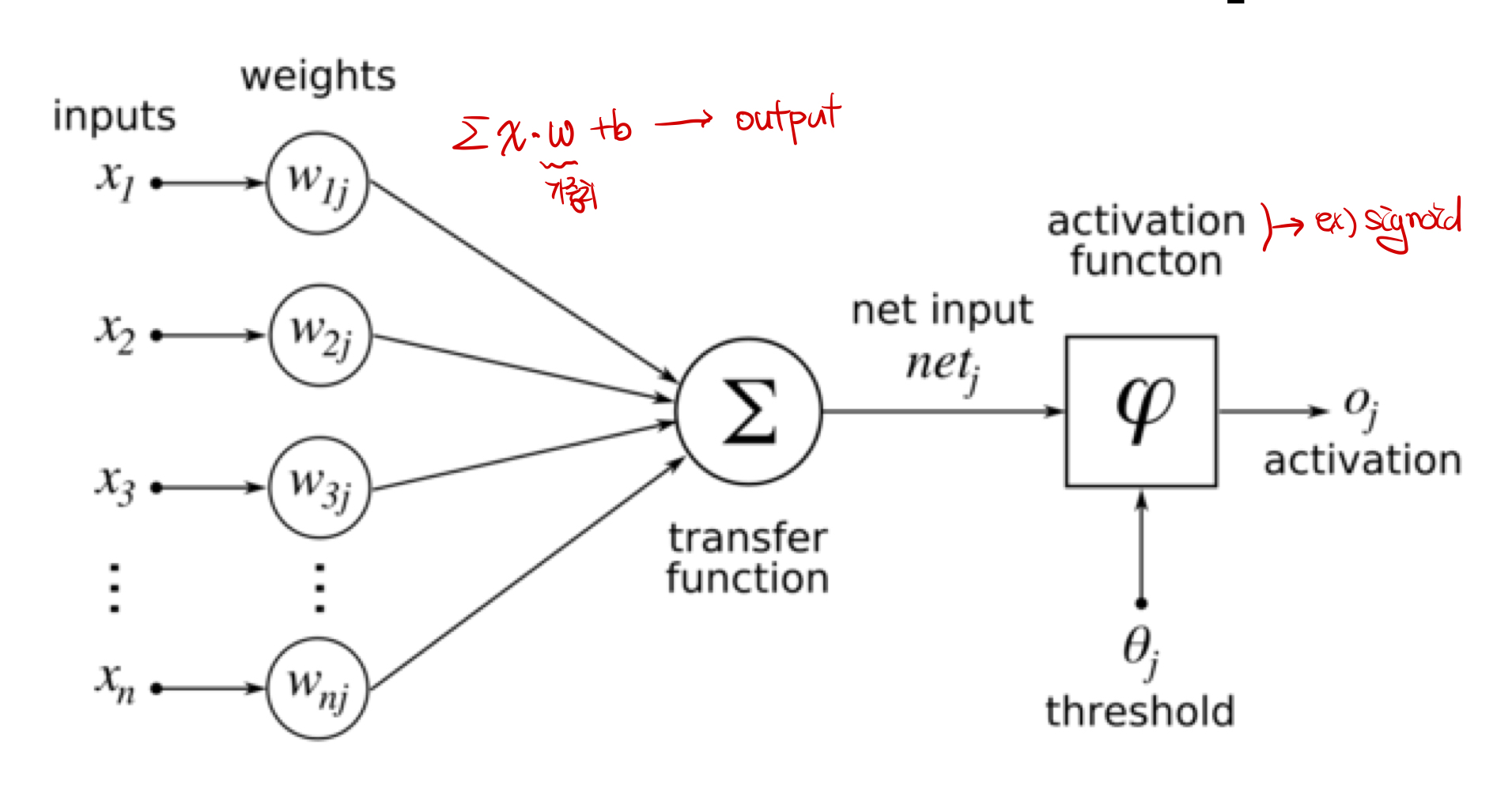
Perceptron : Perception은 인공신경망의 한 종류로 주로 Linear Classifier을 위해 쓰이며, 1950년도 AND, OR과 같은 논리 연산자 문제를 풀기 위해 고안되었다. 인공신경망 처럼, x와 가중치의 곱과 b의 값이 threshold로 전달이 되고, activation function을 거쳐 신호가 전달되는 원리를 갖는다.
역사
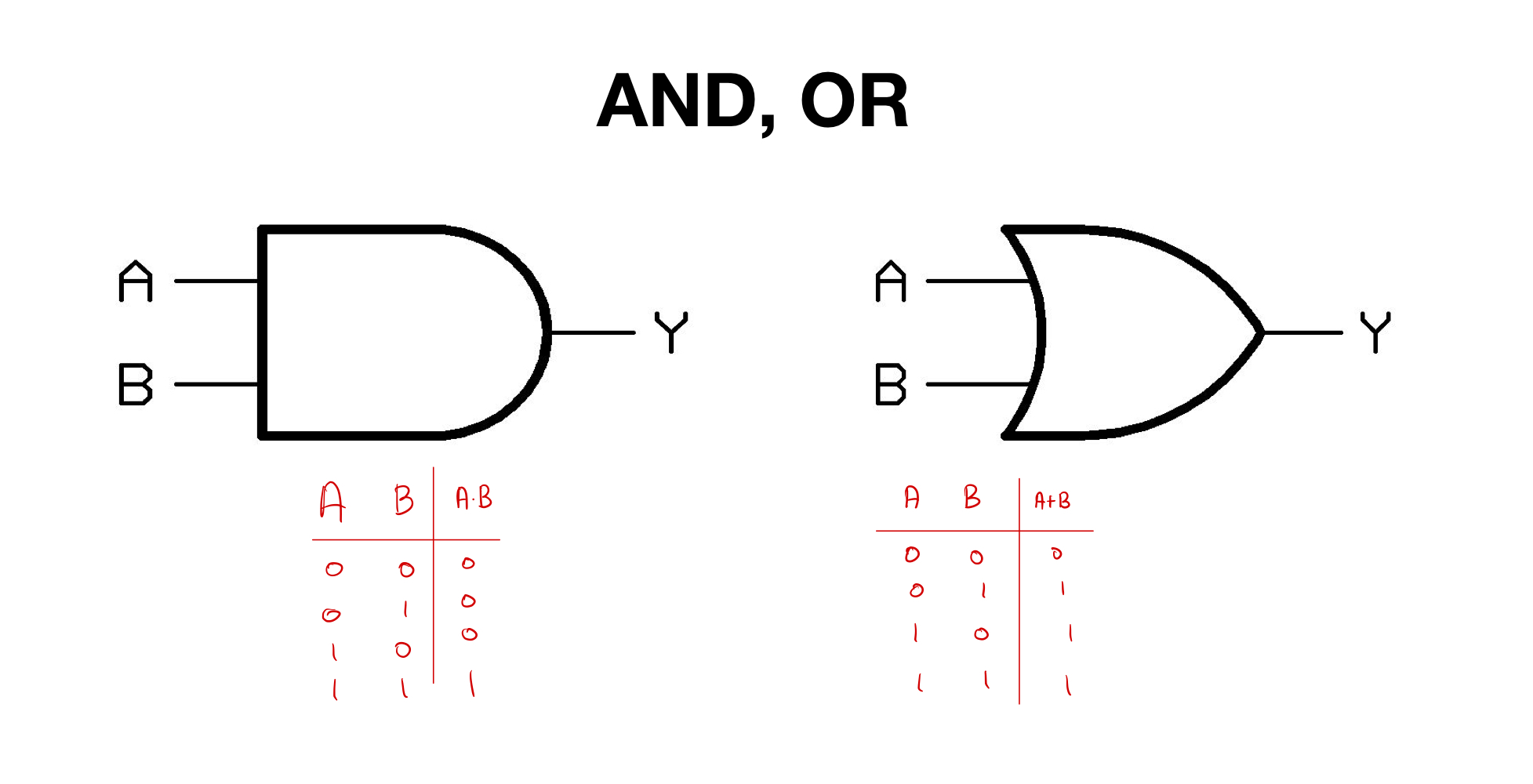
AND, OR
1950년도에 Single Layer을 통해 AND, OR을 Linear Classification에 성공한다.

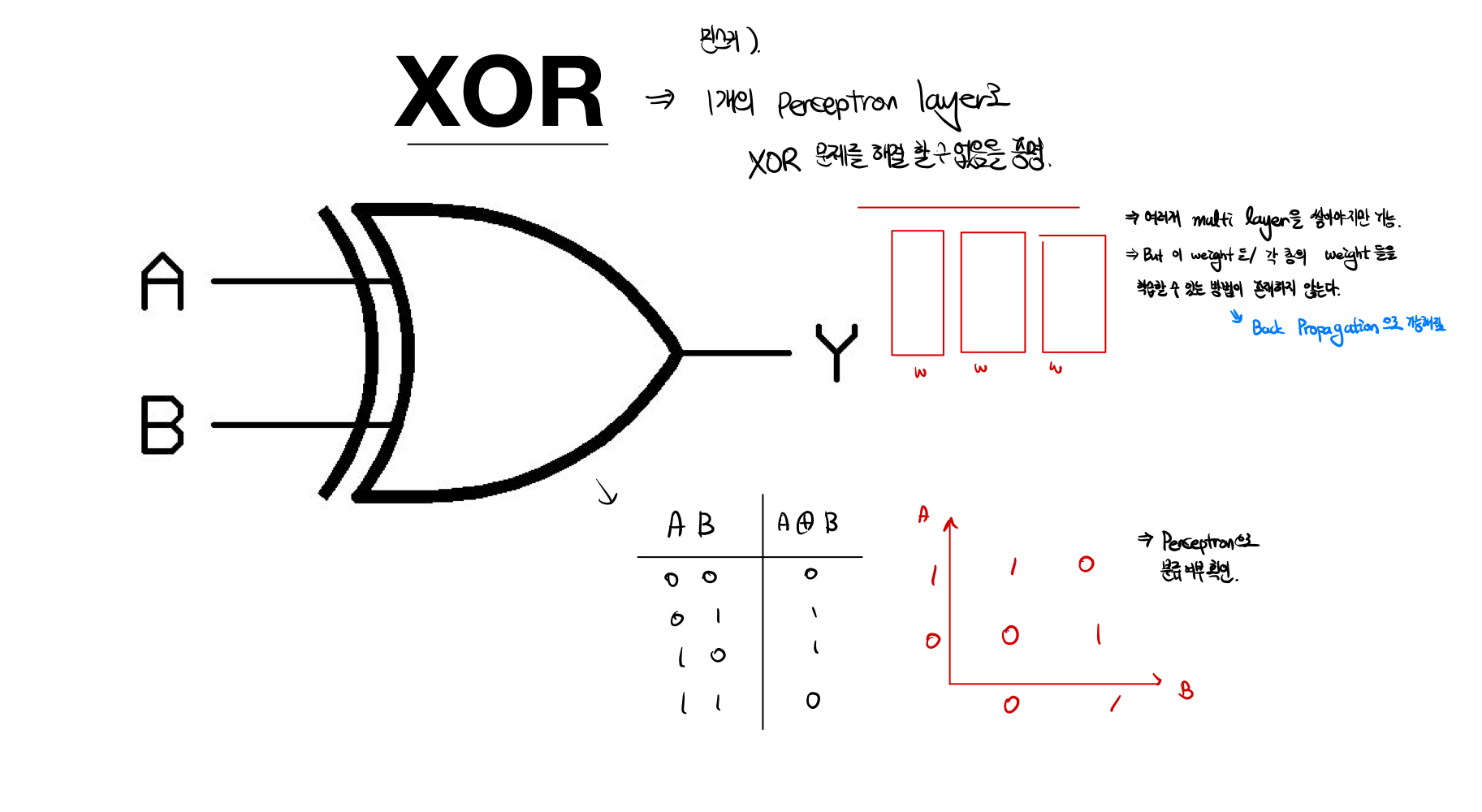
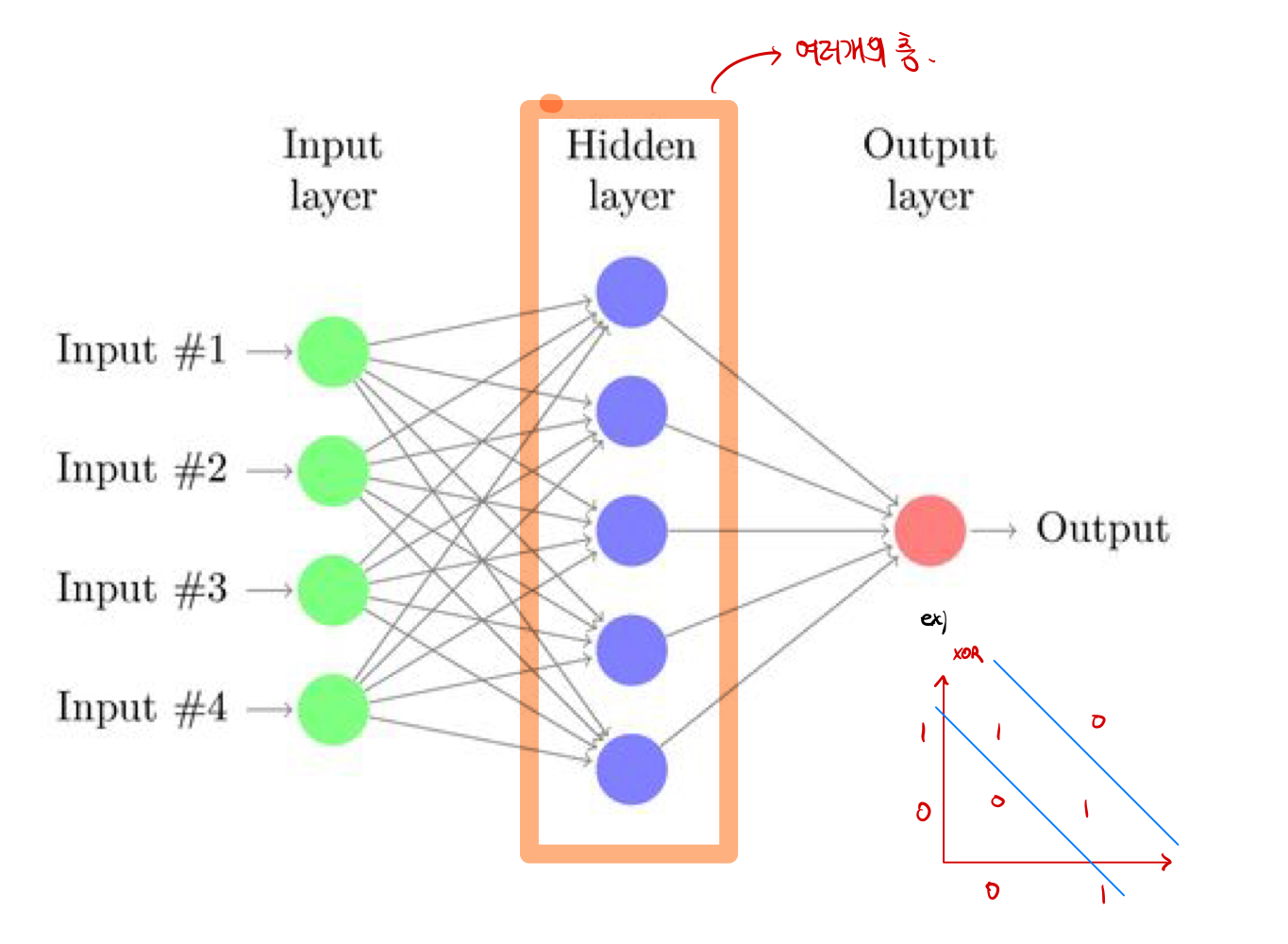
XOR
Marvin Minsky가 XOR과 같은 논리연산은 Single Layer로 문제를 풀 수 없음을 증명하는 동시에, Multi layer로 구현해야한다는 내용을 알렸다. 하지만 당시에 기술로는 문제를 해결할 수 없었고, 기술의 암흑기가 도래했다. 하지만, 나중에 Back Propagation 을 통해서 문제를 해결할 수 있게 되었다.
- 코드 : 아래 코드를 통해, train이 지속되어도 전혀 개선되지 않음을 보여준다.
# Lab 9 XOR
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
X = torch.FloatTensor([[0, 0], [0, 1], [1, 0], [1, 1]]).to(device)
Y = torch.FloatTensor([[0], [1], [1], [0]]).to(device)
# nn layers
linear = torch.nn.Linear(2, 1, bias=True)
sigmoid = torch.nn.Sigmoid()
# model
model = torch.nn.Sequential(linear, sigmoid).to(device)
# define cost/loss & optimizer
criterion = torch.nn.BCELoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1)
for step in range(10001):
optimizer.zero_grad()
hypothesis = model(X)
# cost/loss function
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
if step % 100 == 0:
print(step, cost.item())
# Accuracy computation
# True if hypothesis>0.5 else False
with torch.no_grad():
hypothesis = model(X)
predicted = (hypothesis > 0.5).float()
accuracy = (predicted == Y).float().mean()
print('\nHypothesis: ', hypothesis.detach().cpu().numpy(), '\nCorrect: ', predicted.detach().cpu().numpy(), '\nAccuracy: ', accuracy.item())Multi Layer Perception
- Back Propagation을 통해서 문제를 해결
# Lab 9 XOR
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
X = torch.FloatTensor([[0, 0], [0, 1], [1, 0], [1, 1]]).to(device)
Y = torch.FloatTensor([[0], [1], [1], [0]]).to(device)
# nn layers
linear1 = torch.nn.Linear(2, 2, bias=True)
linear2 = torch.nn.Linear(2, 1, bias=True)
sigmoid = torch.nn.Sigmoid()
# model
model = torch.nn.Sequential(linear1, sigmoid, linear2, sigmoid).to(device)
# define cost/loss & optimizer
criterion = torch.nn.BCELoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1) # modified learning rate from 0.1 to 1
for step in range(10001):
optimizer.zero_grad()
hypothesis = model(X)
# cost/loss function
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
if step % 100 == 0:
print(step, cost.item())
# Accuracy computation
# True if hypothesis>0.5 else False
with torch.no_grad():
hypothesis = model(X)
predicted = (hypothesis > 0.5).float()
accuracy = (predicted == Y).float().mean()
print('\nHypothesis: ', hypothesis.detach().cpu().numpy(), '\nCorrect: ', predicted.detach().cpu().numpy(), '\nAccuracy: ', accuracy.item())
사회적 가치를 실현하는 프로그래머
오랜만에 보는 뉴런을 이곳에서 보다니 감회가 새롭습니다 :)