GraphQL이란?
GraphQL은 트리 구조로 쿼리 결과를 받기 위해 그래프를 탐색하는 쿼리 언어이다. 리소스의 크기와 형태를 서버가 아닌 클라이언트 단에서 결정하고 요청한다.
2016년 페이스북에서 개발된 오픈 소스 쿼리 언어이며 Graph + Query Language의 줄임말로 API를 통해 데이터를 주고받기 위한 쿼리 언어이다.
GraphQL의 특징
-
HTTP를 통해 API 서버로 요청을 보내고 응답을 받는다.
-
응답 데이터는 JSON 형식으로 받는다.
-
서버 개발자가 작성한 각 필드에 대응하는 resolver 함수로 각 필드의 데이터를 조회할 수 있다.
-
GraphQL 라이브러리가 조회 대상 schema가 유효한지 검사한다.
-
Resource에 대한 정보만 정의하고 필요한 크기와 형태는 클라이언트 단에서 요청 시 결정한다.
Graph 자료구조
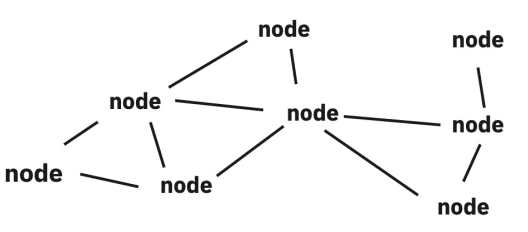
그래프는 여러 개의 점들이 복잡하게 연결되어 있는 관계를 표현한 자료구조이며 하나의 점을 노드 또는 정점, 노드를 연결하는 선은 간선 이라고 한다. 직접적인 관계가 있는 경우 두 점 사이를 이어주는 선이 있으며 간접적인 관계라면 몇 개의 점과 선에 걸쳐 이어진다.
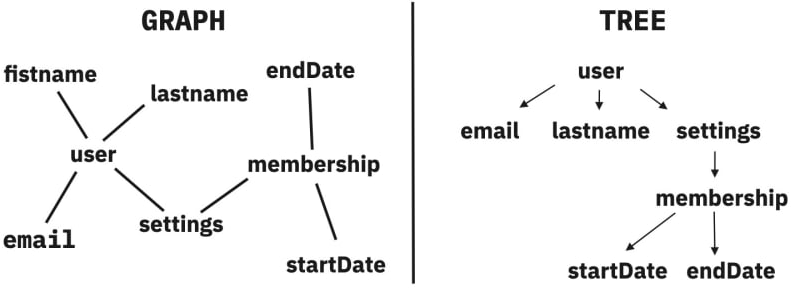
GraphQL에서는 모든 데이터가 그래프 형태로 연결되어 있다고 전제하며 일대일로 연결된 관계, 여러 계층으로 이루어진 관계 모두 그래프이다. 그래프를 누구의 입장에서 정렬하느냐(클라이언트가 필요한 데이터)에 따라 트리 구조를 이룰 수 있으며 GraphQL을 사용해 트리를 추출할 수 있다.

GraphQL은 유연하게 트리 구조의 데이터를 JSON 형식으로 응답할 수 있으며 REST API 처럼 고정된 자원이 아닌 클라이언트 요청에 따라 유연하게 자원을 가져올 수 있다.
GraphQL VS REST API
GraphQL은 API를 위한 쿼리 언어이다. 하지만 REST API가 이미 존재하고 있음에도 GraphQL이 개발된 이유는 무엇일까?
REST API의 한계
1. 필요 없는 데이터까지 제공한다. (Overfetch)
예를 들어 사용자의 아이디만 필요한 상황에서 REST API를 사용한다면 응답 데이터에는 사용자의 이름, 주소, 생년월일 등 클라이언트에게 필요없는 데이터가 포함될 수 있다.
2. endpoint가 필요한 정보를 충분히 제공하지 못한다. (Underfetch)
클라이언트는 필요한 정보를 모두 확보하기 위해서 추가적인 요청을 보내야한다. 사용자의 아이디를 응답받은 후 유저의 팔로워나 게시글 목록 데이터가 필요한 경우 REST API는 각각의 리소스를 endpoint로 구분하기 때문에 다수의 endpoint로 요청을 보내야한다.
3. 클라이언트 구조 변경 시 엔드포인트 변경 또는 데이터 수정이 필요하다.
REST API에서는 자원의 크기와 형태를 서버에서 결정하기 때문에 클라이언트가 직접 데이터의 형태를 결정할 수 없다. 이로 인해 클라이언트에서 필요한 데이터의 내용이 변경될 경우 다른 endpoint를 통해 데이터를 가져오거나 수정을 해야한다.
REST API와 GraphQL의 차이점
-
REST API는 Resource에 대한 형태 정의와 데이터 요청 방법이 연결되어 있지만 GraphQL에서는 Resource에 대한 형태 정의와 데이터 요청이 완전히 분리되어 있다.
-
REST API는 Resource의 크기와 형태를 서버에서 결정하지만 GraphQL에서는 Resource에 대한 정보만 정의하고 필요한 크기와 형태는 클라이언트 단에서 요청 시 결정한다.
-
REST API는 URI가 Resource를 나타내고 Method가 작업의 유형을 나타내지만 GraphQL에서는 GraphQL Schema가 Resource를 나타내고 Query, Mutation 타입이 작업의 유형을 나타낸다.
-
REST API는 여러 Resource에 접근하고자 할 때 여러 번의 요청이 필요하지만 GraphQL에서는 한번의 요청으로 여러 Resource에 접근할 수 있다.
-
REST API에서 각 요청은 해당 엔드포인트에 정의된 핸들링 함수를 호출하여 작업을 처리하지만 GraphQL에서는 요청 받은 각 필드에 대한 resolver를 호출하여 작업을 처리한다.
GraphQL의 장점
1. 하나의 endpoint 요청
하나의 endpoint인 /graphql로 요청을 하고 query와 mutation을 resolver 함수로 전달해서 요청에 응답한다. 모든 요청은 POST 메서드를 사용한다.
2. No under & overfetching
하나의 endpoint에서 쿼리를 이용해 원하는 데이터를 API에 요청하고 응답받을 수 있다. 이로 인해 필요 이상의 데이터를 응답받거나 추가적인 endpoint 요청이 필요하지 않다.
3. 강력한 playground
graphql 서버를 실행하면 playground라는 GUI를 이용해 resolver와 schema를 한눈에 보고 테스트해 볼 수 있다. (POSTMAN 과 비슷)
4. 클라이언트 구조 변경에도 지장이 없음
클라이언트 구조가 바뀌어도 필요한 데이터를 결정하고 받는 주체가 클라이언트이기 때문에 서버에 지장이 없다. 클라이언트에서는 어떤 데이터가 필요한 지에 대해서만 요구사항을 쿼리로 작성하면 된다.
GraphQL의 단점
-
REST API에 친숙한 개발자의 경우 GraphQL를 학습하는 데 시간이 필요하다.
-
고정된 요청과 응답만 필요할 경우 Query로 인해 요청의 크기가 REST API보다 더 커진다.
-
캐싱이 REST API보다 훨씬 복잡하다. HTTP에선 각 메소드에 따라 캐싱이 구현되어 있지만 GraphQL에선 POST 메소드만을 이용해 요청을 보내기 때문에 각 메소드에 따른 캐싱을 지원받을 수 없다. 이를 보완하기 위해 Apollo 엔진의 캐싱과 영속 쿼리 등이 등장하게 되었다.
GraphQL 사용하기
-
Query - 저장된 데이터 가져오기 (REST API의 GET과 비슷)
-
Mutation - 저장된 데이터 수정하기
Create - 새로운 데이터 생성
Update - 기존의 데이터 수정
Delete - 기존의 데이터 삭제 -
Subscription - 특정 이벤트 발생 시 서버가 대응하는 데이터를 실시간으로 클라이언트에게 전송
Subscription은 실시간 업데이트를 구현할 수 있는데 전통적인 Client(요청)-Server(응답) 모델을 따르는 Query 와 Mutation과 달리 발행/구독(pub/sub) 모델을 따른다.
클라이언트가 어떤 이벤트를 구독하면 서버와 WebSocket을 기반으로 지속적인 연결을 형성하고 유지하게 되며 이후 특정 이벤트가 발생하면 서버는 대응하는 데이터를 클라이언트에 push 해준다.
query(데이터 조회)
field(필드)
# cat의 name을 쿼리
{
cat {
name
}
}
# 결과
{
"data": {
"cat": {
"name": "navi"
}
}
}필드의 name은 String 타입을 반환한다. 위의 예시에서 쿼리와 결과는 같은 모양을 하고있는데 이 부분은 GraphQL에서 필수적인 부분이다. 서버에 요청했을 때 예상했던 대로 돌려받고 서버는 GraphQL을 통해 클라이언트가 요구하는 필드를 정확히 알고있기 때문이다.
# cat의 name과 friends의 name을 쿼리
{
cat {
name
# 주석 작성 가능
friends {
name
}
}
}
# 결과
{
"data": {
"cat": {
"name": "navi",
"friends": [
{
"name": "coco"
},
{
"name": "luna"
},
{
"name": "momo"
}
]
}
}
}원하는 필드를 중첩하여 쿼리하는 것도 가능하다. 위 예시에서 friends 필드는 배열을 반환한다. GraphQL 쿼리는 관련 객체 및 필드를 순회할 수 있기 때문에 여러 endpoint를 만들어 요청을 보내는 것이 아닌 클라이언트에서 하나의 요청을 보내 관련 데이터를 가져온다.
Arguments(전달인자)
# id가 10인 cat의 name과 age를 쿼리
{
cat(id: "10") {
name
age
}
}
# 결과
{
"data": {
"cat": {
"name": "momo",
"age": 5
}
}
}필드에 인수를 전달하는 부분을 추가하면 쿼리의 필드 및 중첩된 객체들에 전달하여 원하는 데이터만 받아올 수 있다.
REST API의 ?id=1000 또는 /1000(/:id) 요청과 동일하다.
Aliases(별명)
# 잘못된 쿼리
{
cat(from: AMERICAN) {
name
}
cat(from: KOREAN) {
name
}
}
# 올바른 쿼리
{
americanCat: cat(from: AMERICAN) {
name
}
KoreanCat: cat(from: KOREAN) {
name
}
}
# 결과
{
"data": {
"americanCat": {
"name": "navi"
},
"KoreanCat": {
"name": "coco"
}
}
}
필드 이름을 중복해서 쿼리할 수 없기 때문에 필드 이름을 중복으로 사용해야할 경우 별명을 붙여서 쿼리한다.
위와 같이 다른 이름으로 별명을 지정하면 별명이 key의 이름으로 쓰이고 한 번의 요청으로 두 개의 결과를 얻어낼 수 있다.
Operation name(작업 이름)
# 쿼리
query CatNameAndFriends {
cat {
name
friends {
name
}
}
}
# 결과
{
"data": {
"cat": {
"name": "navi",
"friends": [
{
"name": "coco"
},
{
"name": "luna"
},
{
"name": "momo"
}
]
}
}
}여태껏 쿼리와 쿼리 네임을 모두 생략하는 축약형 구문을 사용했으나 코드를 모호하지 않게 작성하는 것이 중요하다.
앞의 query는 오퍼레이션 타입이며 오퍼레이션 타입에는 query, mutation, subscription, describes 등이 있다. 쿼리를 약식으로 작성하지 않는 한 오퍼레이션 타입은 반드시 필요하다. 오퍼레이션 네임을 작성할 때는 오퍼레이션 타입에 맞는 이름으로 작성하는 것이 가독성이 좋다.
Variables(변수)
# 변수를 작성하여 쿼리
query CatNameAndFriends($from: From) {
cat(from: $from) {
name
friends {
name
}
}
}변수는 동적으로 인수를 받아 쿼리할 경우 사용한다.
오퍼레이션 네임 옆에 변수를 $변수 이름: 타입 형태로 정의한다.
위 예시처럼 $from: From일때 타입 뒤에 !가 붙는다면 $from은 반드시 From이어야 한다.
mutation(데이터 수정)
mutation CreateReviewForEpisode($ep: Episode!, $review: ReviewInput!) {
createReview(episode: $ep, review: $review) {
stars
commentary
}
}REST API에서 GET 요청을 사용하여 데이터를 수정하지 않고 POST, PUT 요청을 사용하는 것처럼 GraphQL도 유사하다. GraphQL에서는 mutation이라는 키워드를 사용하여 서버 측 데이터를 수정한다.
Schema/Type(스키마/타입)
type Character {
name: String!
appearsIn: [Episode!]!
}GraphQL 스키마의 가장 기본적인 구성 요소는 서비스에서 가져올 수 있는 객체의 종류, 포함하는 필드를 나타내는 객체 유형이다.
-
Character는 GraphQL 객체 타입이며 필드가 있는 타입임을 의미한다. 스키마에 있는 대부분의 타입은 객체 타입이다.
-
name과 appearIn은 Character 타입의 필드 이다. 즉 name과 appearIn은 GraphQL 쿼리의 Character 타입 어디서든 사용할 수 있는 필드이다.
-
String은 내장된 스칼라 타입 중 하나이다. 단일 스칼라 객체로 확인되는 유형이며 쿼리에서 하위 선택을 가질 수 없다. 스칼라 타입에는 ID, Int도 있다.
-
!가 붙는다면 이 필드는 nullable하지 않고 반드시 값이 들어온다는 의미이다. 이것을 붙여 쿼리한다면 반드시 값을 받을 수 있을 것이란 예상을 할 수 있다.
-
[ ]는 배열을 의미하며 배열에도 !가 붙을 수 있다. 여기서는 !가 뒤에 붙어 있어 null 값을 허용하지 않으므로 항상 0개 이상의 요소를 포함한 배열을 기대할 수 있게 된다.
Resolver(리졸버)
데이터를 가져오는 구체적인 과정 구현을 담당하며 요청에 대한 응답을 결정해주는 함수로써 GraphQL의 여러 가지 타입 중 Query, Mutation, Subscription과 같은 타입의 실제 일하는 방식인 로직을 작성한다.
위와 같이 스키마를 정의하면 스키마 필드에 사용되는 함수의 실제 행동을 Resolver에서 정의하며 이러한 함수들이 모여 있기 때문에 보통 Resolvers라 부른다.
const db = require("./../db")
const resolvers = {
Query: { // Query - 저장된 데이터 가져오기(REST API의 GET과 비슷)
getUser: async (_, { email, pw }) => {
db.findOne({
where: { email, pw }
}) ... // 실제 디비에서 데이터를 가져오는 로직
...
}
},
Mutation: { // Mutation - 저장된 데이터 수정하기(Create, Update, Delete)
createUser: async (_, { email, pw, name }) => {
...
}
}
Subscription: { // Subscription - 실시간 업데이트
newUser: async () => {
...
}
}
};GraphQL에서는 데이터를 가져오는 구체적인 과정을 직접 구현해야 하는데 이와 같은 작업(데이터베이스 쿼리, 원격 API 요청)을 Resolver가 담당한다.
