💡 ELECTRA?
Efficiently Learning an Encoder that Classifies Token Replacements Accurately
ELECTRA 논문의 원본은 여기에서 확인할 수 있다.
Abstract
BERT에서 사용하는 pre-training 방법인 Masked Language Modeling (MLM)은 입력 토큰의 일부를 [MASK] 토큰으로 치환한 후 원래의 토큰을 복구하는 방향으로 학습이 이루어진다. 하지만 MLM은 좋은 성능을 내기 위해서 많은 계산량을 필요로 한다.
이 논문에서는 그 대안으로 replaced token detection이라는 효율적인 pre-training 방법을 제안한다. 입력 토큰의 일부를 [mask] 토큰으로 치환하는 대신에, 그럴듯하지만 인위적으로 생성된 다른 토큰으로 치환한다. 그 후, 원래의 original 토큰이 무엇이었는지를 예측하는 것이 아니라 입력의 각 토큰이 치환된 토큰인지 아닌지 그 여부를 예측하도록 모델을 학습한다. 이러한 방법은 [MASK]된 부분만을 학습하는 것이 아니라 입력 토큰 전체를 학습하기 때문에, MLM보다 효율적이다.
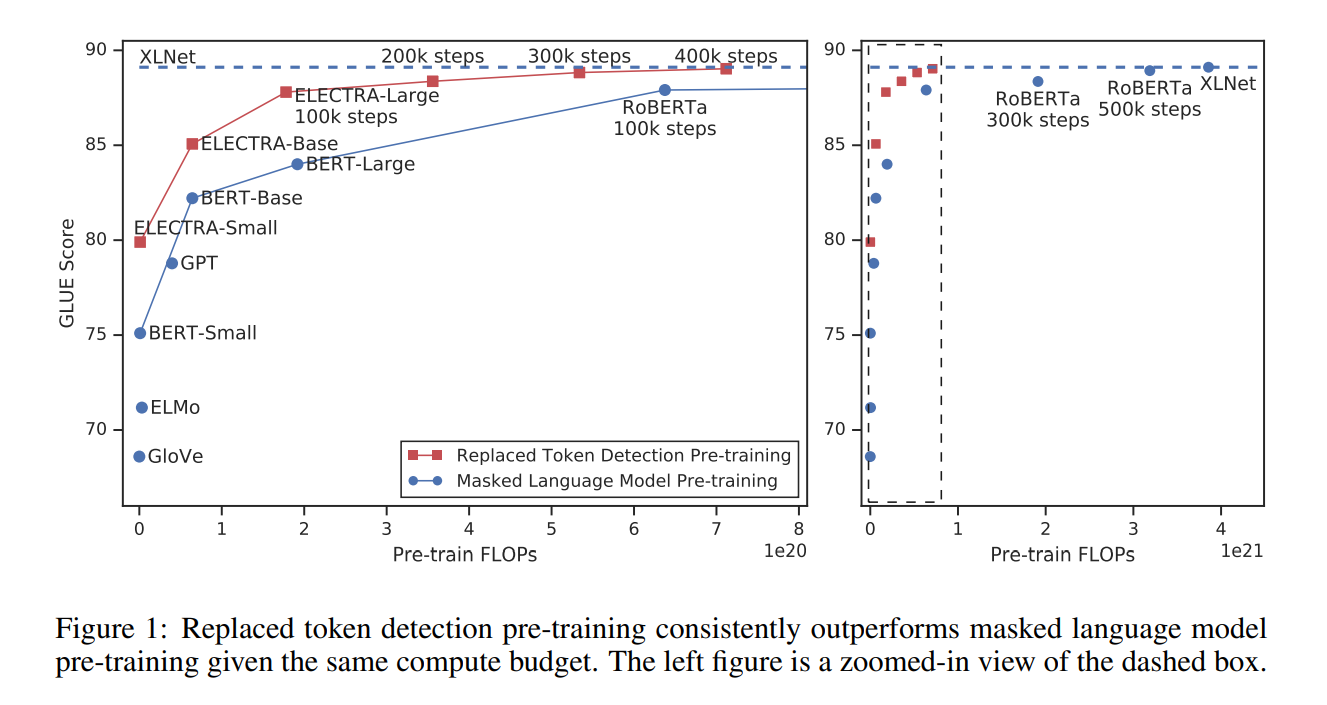
같은 환경 (모델 크기, 데이터, 계산량)에서 모델을 학습했을 때 BERT보다 ELECTRA의 성능이 좋았고, 특히 작은 모델에서 그 성능이 뛰어났다. 하나의 GPU로 4일동안 학습시킨 ELECTRA 모델은 30배 이상의 계산량을 가지는 GPT의 성능을 능가했으며, 1/4의 계산량만으로 RoBERTa, XLNet와 유사한 성능을 보였다.
Introduction
기존의 SOTA 언어 학습 방법은 입력 sequence의 일부 (보통 15%)를 선택한 후, 그 토큰의 identity나 attention을 mask하고 원래의 토큰으로 복구하는 방향으로 이루어진다 (Masked Language Modeling, MLM). 이 방법은 양방향 문맥을 학습한다는 점에서 효율적이긴 하지만 하나의 입력 sequence에서 15%만을 학습하기 때문에 상당한 계산량이 요구된다.
그 대안으로 이 논문에서는, "real" input과 "replaced" input을 구분하는 방향으로 학습하는 replaced token detection이라는 새로운 pre-training 방법론을 제시한다. 입력 토큰의 일부를 [MASK] 토큰 대신 generator의 확률 분포에서 샘플링한 다른 토큰으로 치환하며, 이는 BERT의 mismatch 문제를 해결할 수 있다. 이후 각 입력 토큰에 대해 기존의 토큰인지 치환된 토큰인지를 예측하도록 discriminator를 학습한다. 이 방법은 mask된 부분만을 학습하는 것이 아니라 전체 입력 토큰을 학습한다는 점에서 계산이 훨씬 효율적이다. 전체적인 과정이 GAN과 유사하지만, generator를 adversarial하게 학습하는 것이 아니라 maximum likelihood로 학습한다는 점에서 차이가 있다.
이 방법론을 ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)라고 부르며, BERT와 비교해서 훨씬 빠르면서 높은 정확도를 보이는 것을 확인했다.
pre-training 방법론은 계산 효율적이면서 좋은 성능을 보이는 것이 중요하다. 성능 실험에서 같은 환경 (모델 크기, 데이터, 계산량)을 두고 모델을 학습했을 때, ELECTRA는 MLM 기반의 BERT나 XLNet보다 성능이 좋았다. 하나의 GPU로 4일동안 학습시킨 ELECTRA 모델은 30배 이상의 계산량을 가지는 GPT의 성능을 능가했으며, 1/4의 계산량만으로 RoBERTa, XLNet와 유사한 성능을 보였다.
Method
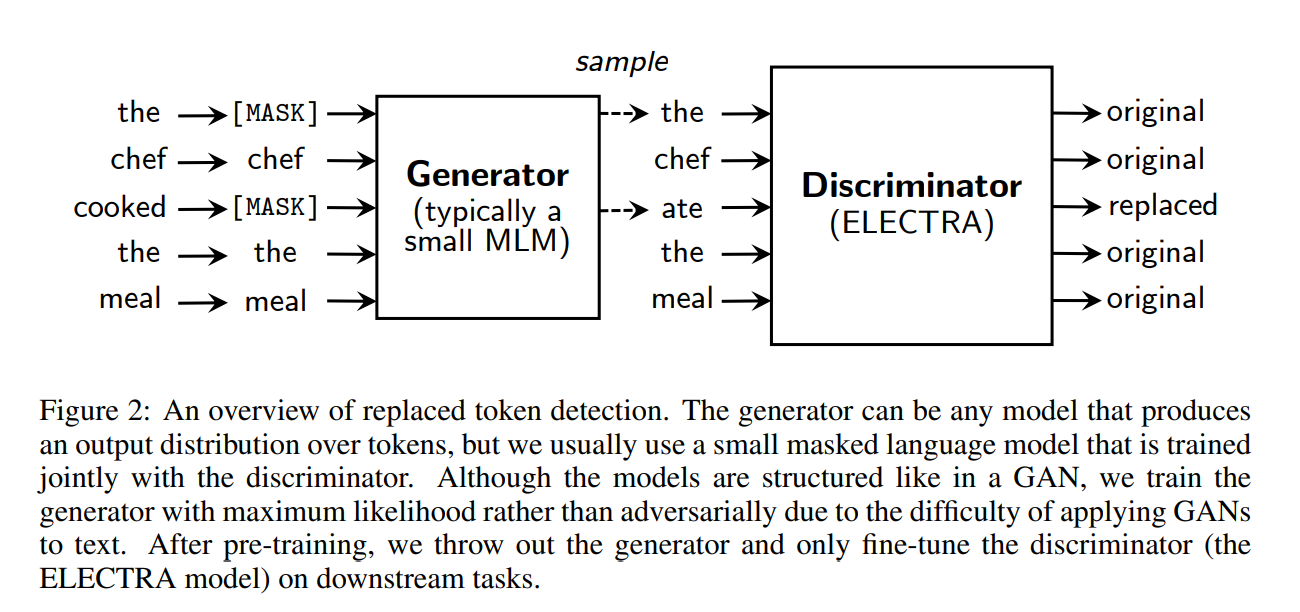
replaced token detection은 generator G와 discriminator D를 학습하며, 각각은 encoder로 구성되어 있다 (encoder: 입력 토큰을 contextualized vector representation으로 매핑). 포지션 t가 주어지면, generator는 softmax를 통해 특정 토큰 x_t가 생성될 확률을 출력한다. 수식은 다음과 같다.
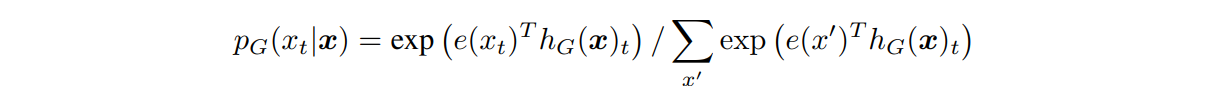
x는 입력 sequence, h(x)는 contextualized vector representation, e(x)는 토큰 임베딩을 의미한다. 이후, discriminator는 토큰 x_t가 'real' 토큰인지 'replaced' 토큰인지 sigmoid를 통해 예측한다. 수식은 다음과 같다.
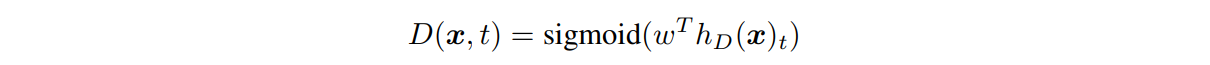
generator의 학습과정은 MLM과 동일하다.
1. 입력 토큰 x에 대해 마스킹할 m개의 포지션을 선택한다. (보통 15% 마스킹)
2. m개의 포지션에 위치한 토큰을 [MASK] 토큰으로 치환한다.
3. [MASK] 토큰에 대해 원래 토큰이 무엇인지 예측한다.

4. 다음 loss를 줄이는 방향으로 학습한다.
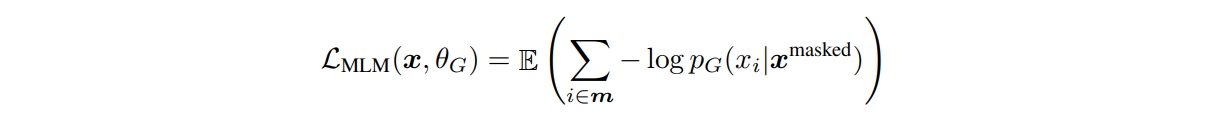
📍 Generator Loss Function : maximum likelihood
generator의 loss를 수식 안의 probability 관점에서 생각해보자.
이 probability는 "mask 토큰을 입력으로 받았을 때 replaced 토큰을 생성하는 확률"이다. generator의 loss를 최소화하는 것은 이 probability가 최대화되는 방향으로 학습하는 것을 의미하므로 (앞에 마이너스가 붙어있기 때문)
→ maximum likelihood
discriminator는 각 토큰이 generator가 생성한 가짜(replaced) 토큰인지 원래 데이터에 있던 진짜(original) 토큰인지 예측한다. 학습과정은 아래와 같다.
1. 마스킹된 포지션 m에 해당하는 토큰 [MASK]를 generator가 생성한 sample 토큰으로 치환한다.
2. 치환된 입력에 대해 discriminator는 각 토큰이 '진짜'인지 판단한다.
3. 다음 loss를 줄이는 방향으로 학습한다.
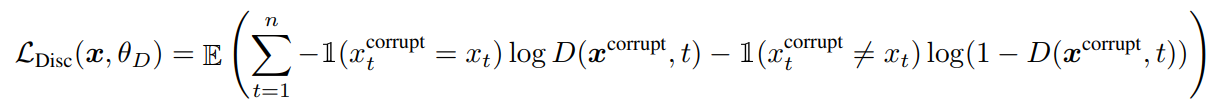
📍 Discriminator Loss Function
loss가 최소가 되는 방향을 생각해보면 수식의 D(x,t)가 1이 되어야 하는지, 0이 되어야 하는지 판단할 수 있다. 치환된 토큰(x_t_corrupt)이 원래 토큰(x_t)과 같은 경우에는 D(x,t) 값이 1이 되어야하고, 치환된 토큰이 원래 토큰과 같지 않은 경우에는 D(x,t) 값이 0이 되어야 loss 값이 최소가 될 수 있다. 즉, 위의 loss function을 최소화하는 것은 original 토큰은 original로, replaced 토큰은 replaced로 예측하도록 학습되는 것을 의미한다.
전체적인 과정에 있어 ELECTRA와 GAN의 유사점이 존재하지만 몇몇 다른 점도 존재한다.
-
GAN은 generator가 얼마나 ‘진짜 같은’ output을 생성하는 지에 상관없이 생성한 output을 ‘fake’로 간주하며, discriminator가 진짜 input인 ‘real’과 generator가 생성한 ‘fake’를 구분하는 방향으로 학습한다. 이와 반대로, ELECTRA는 generator가 original input과 동일한 토큰을 생성하면 그 토큰은 ‘fake’가 아닌 ‘real’로 간주된다.
-
generator의 학습 과정에서, GAN처럼 discriminator를 속이는 방향으로 adversarial하게 학습하는 것이 아니라 maximum likelihood로 학습한다. 사실상, generator에서 샘플링하는 과정 때문에 backpropagation이 불가능하여 adversarial한 학습에 어려움이 있다.
-
generator의 input으로 noise vector를 넣어주지 않는다.
