논문은 여기에서 확인할 수 있다.
Background
GPT의 역사
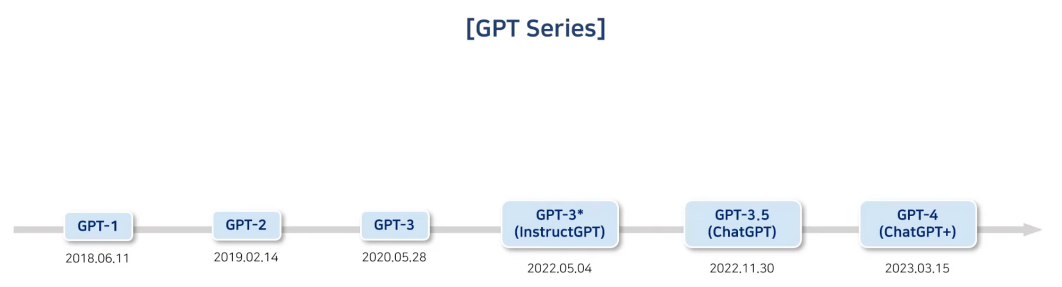
InstructGPT는 기존의 GPT-3의 문제점을 해결하고자 GPT-3가 세상에 나온지 2년 후 출시되었다.
GPT-3의 문제점
GPT-3의 근본적인 문제점은 다음과 같다.
- 문맥적으로는 맞는 말일지 모르나, 사실과는 다른 말을 지어낼 수 있다.
- 편향적이거나 유해한 텍스트를 생성한다.
- 사용자의 지시를 따르지 않은 경우가 발생한다.
이는 LM의 목표와 사용자가 원하는 목표가 다르기 때문에 발생하는 것이다.
- LM의 목표: 주어진 텍스트 sequence를 바탕으로 다음에 올 토큰 맞추기
- 사용자의 목표: 사용자의 지시를 안전하고 유용하게 따르기
즉, 사용자는 다음의 올 토큰을 잘 맞추는 형태로 LM이 동작하길 원하지 않는다. 단지 본인이 원하는 바를 잘 수행하길 바랄 뿐이다. 따라서 LM과 사용자 목표 간의 간극을 줄이기 위해서는 'Alignment'라는 과정이 필요하다. 인간의 의도에 맞게 동작하도록 LM을 조정하는 것이다.
이러한 Alignment 과정을 수행하여 LM이 사용자의 의도에 맞게 동작하도록 학습하는 것이 InstructGPT의 목표이다.
Methodology
InstructGPT의 방법론은 크게 3단계로 나눌 수 있다.
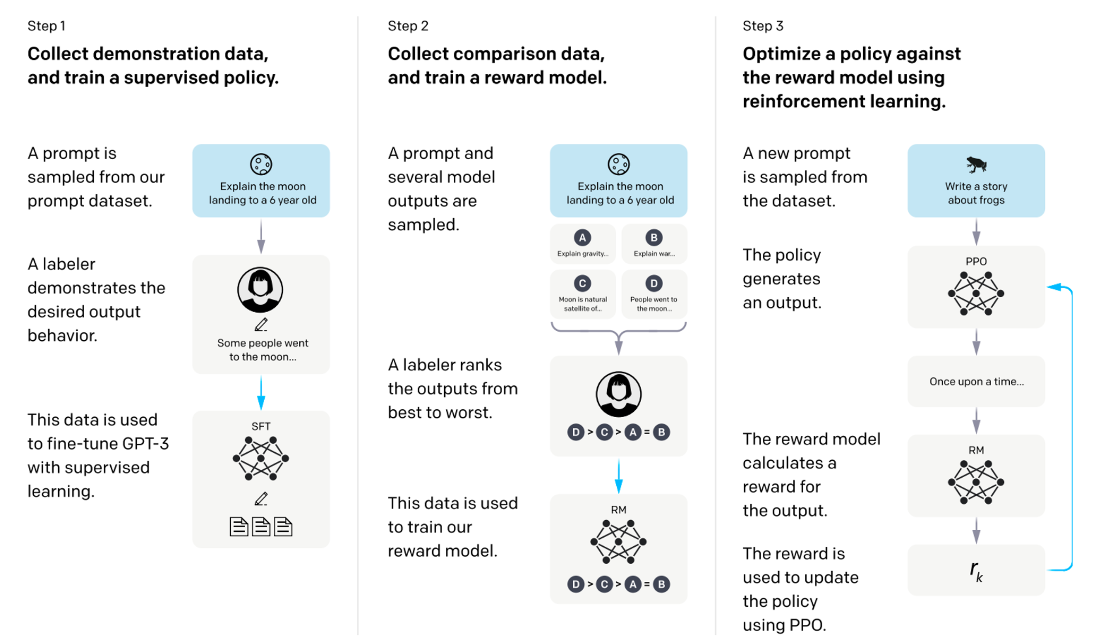
Supervised Fine-Tuning (SFT)
Demonstration Data
labeler는 입력 프롬프트에 맞는 적절한 동작(generation, brainstorming, rewrite 등)을 시연한다. 13k개의 훈련 프롬프트가 존재하며, OpenAI API와 label-written 프롬프트가 포함되어 있다.
❓ Prompts 데이터셋
generation, question answering, dialog, summarization, extraction과 기타 등등 다른 자연어 task를 포함하고 있으며 96% 이상이 영어 데이터셋이다.
ex1) Write a story about a wise frog
ex2) providing the start of a story about a frog
❓ Labeler
task의 영역이 광범위하고 때때로는 논란의 여지가 있으며 민감한 주제를 포함할 수 있기 때문에, 다양한 선호도에 민감하고 잠재적으로 유해한 출력을 식별하는 데 능숙한 labeler 그룹을 선택하고자 했다.
-> screening test를 통해 좋은 성적을 거둔 labeler를 선택
Fine-tuning GPT-3
지도학습을 통해 pre-trained GPT-3 모델을 demonstration data에 fine-tuning 한다.
- 16 epochs
- cosine learing rate decay
- residual dropout of 0.2
validation set의 RM score를 통해 최종 SFT 모델을 선택한다.
(1 epoch 이후에 validation loss에서 과적합이 발생하지만, 더 많은 epoch를 학습하는 것이 RM score와 human preference rating에서 좋은 결과를 가져오기 때문에 16 epochs 학습)
Reward Modeling (RM)
Comparison Data
labeler는 prompt에 대한 여러 모델의 output을 선호도에 따라 순위를 매긴다. 같은 input에 대하여 두 개의 모델 output를 비교하는 방식으로 전체 output을 비교하기 때문에, 각 prompt에 대해 만큼의 비교작업이 필요하다. (K : response의 개수로 4개 ~ 9개 사이)
- 33k training prompts (API + labeler-written)
Training a Reward Model
human-preferred output을 예측하기 위해 comparision data를 기반으로 RM을 학습한다. RM은 [promt-response]를 input으로 받아 scalar reward 값을 출력한다. 각 prompt에 대한 모든 comparison을 하나의 batch 로서 학습한다.
Reward Model의 loss function은 다음과 같다.
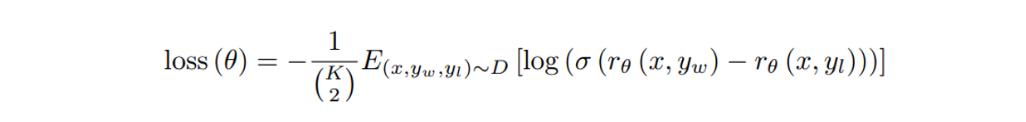
- : RM의 scalar reward output (prompt x, completion y)
- : pair에서 preferred completion
- : comparison dataset
최종적으로 reinforcement learning을 하기 전에, labeler demonstration 평균 점수가 0이 되도록 bias를 사용하여 RM을 정규화한다.
