1. Text Processing
과정
- Cleaning
- HTML 과 같은 웹언어에서 우리가 필요한 문자만 뽑아내는 과정


- Normalization
-
문장 내에서의 대문자를 소문자로 바꾸는 들의 문자를 정규화 하는 과정


- Tokenization
-
문장을 토큰화 하여 나누는 과정


- Stop Word Removal
-
우리에게 필요하지 않은 단어들을 삭제하는 과정


- Tagged
-
단어별로 품사를 붙인다.


이러한 과정을 통해 컴퓨터가 이해하기 쉬운 언어로 바뀌어 진다.
3. Capturing Text Data
이제 문자가 있는 것들을 읽어내야 하는데
방법은 총 3가지가 있다.
-
파일을 직접 읽어드리는 방법

-
판다스로 csv 파일을 읽어드리는 방법

-
온라인에 저장되어 있는 데이터를 읽어오는 방법

4. Normalization
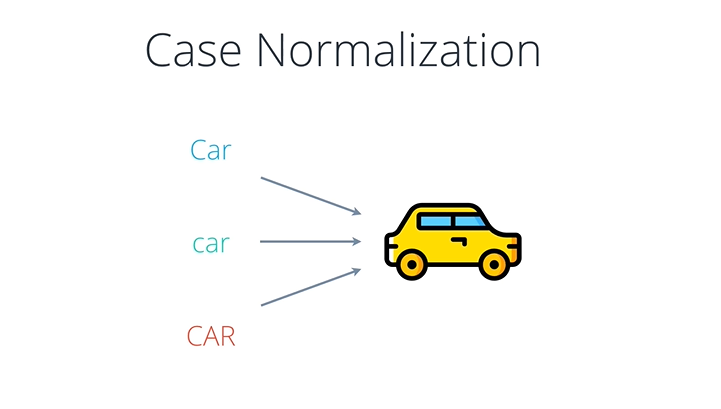
사람이 사용하는 문자는 Car, car, CAR 모두 같은 문자이지만 기계가 느끼기에는 그렇지 못하다.
그렇기 때문에 이것을 정규화 해주는 과정이 필요하게 된다.

그래서 주로 소문자로 모두 바꾸어 버리는 과정을 거치곤 한다.
단계로는
-
문자를 모두 소문자로 바꾸기
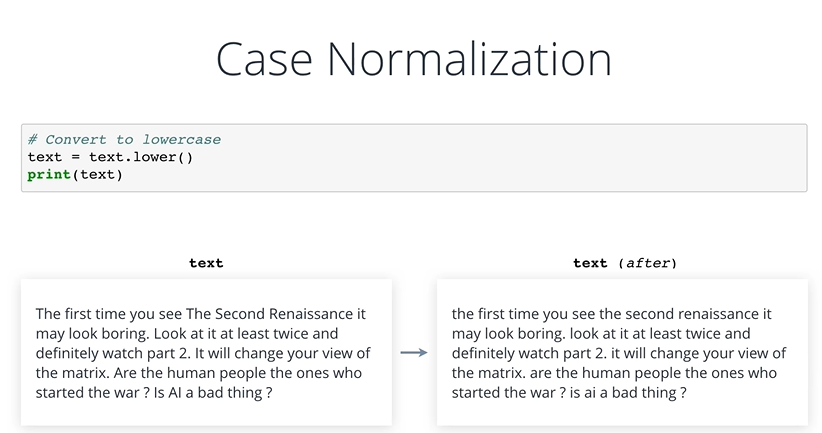
-
Punctuation Removal : 구두점(. ? ! ,) 을 삭제

퀴즈

정답은 삭제
5. Tokenization
토큰은 긴 문자열을 나누어지지 않는 매우 작은 단위로 나눈 문자열 단위를 지칭한다.

이것을 파이썬의 기본 함수인 .split()을 이용하여서 나눌 수도 있지만
NLTK(Natural Language Toolkit)이라는 라이브러리는 이것을 좀 더 쉽게끔 만들어 준다.
NLTK를 이용하여 문자열을 나누는 방법은 총 3가지가 있다.
시작전에 온라인상에 있는 gutenberg 라이브러리 부터 책을 가지고 오자
import nltk
nltk.download("book")
emma_raw = nltk.corpus.gutenberg.raw("austen-emma.txt")1. 문자열을 문장 단위로 나누기
from nltk.tokenize import sent_tokenize
sent_tokenize(emma_raw)
2. Space 와 Comma를 기준으로 문장을 나누기
from nltk.tokenize import word_tokenize
word_tokenize(emma_raw)
3. 정규식을 이용하여서 문장을 나누기
6. Cleaning
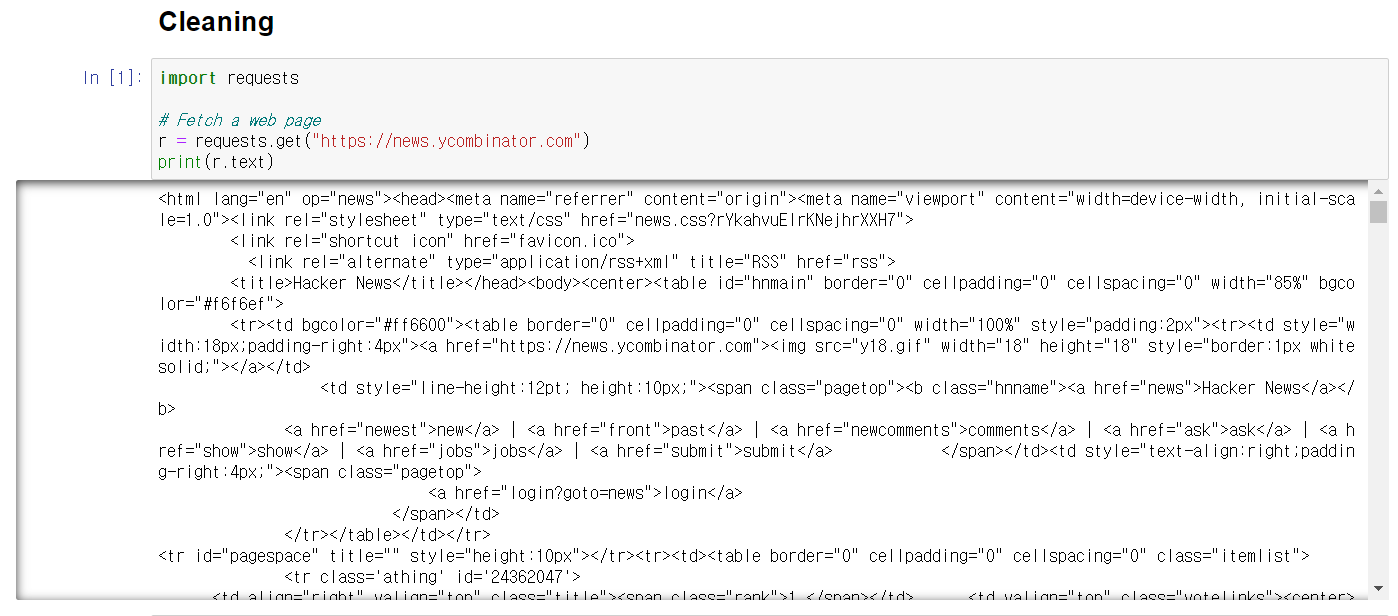
requests.get 함수를 이용해서 홈페이지로 부터 html 파일을 긁어와 보았다.\
그랬더니 html 문법이 그대로 긁어오는 문제가 생기었다.

그래서 re 패키지를 사용하여 필요없는 문제들을 모두 제거하기로 하였다.
그결과 조금 더 깔끔해진 모습을 볼 수 있다.
하지만 여전히 깔끔하지 못하다는 문제가 있다.
그래서 사용하는 라이브러리가 바로 BeautifulSoup 라이브러리이다.
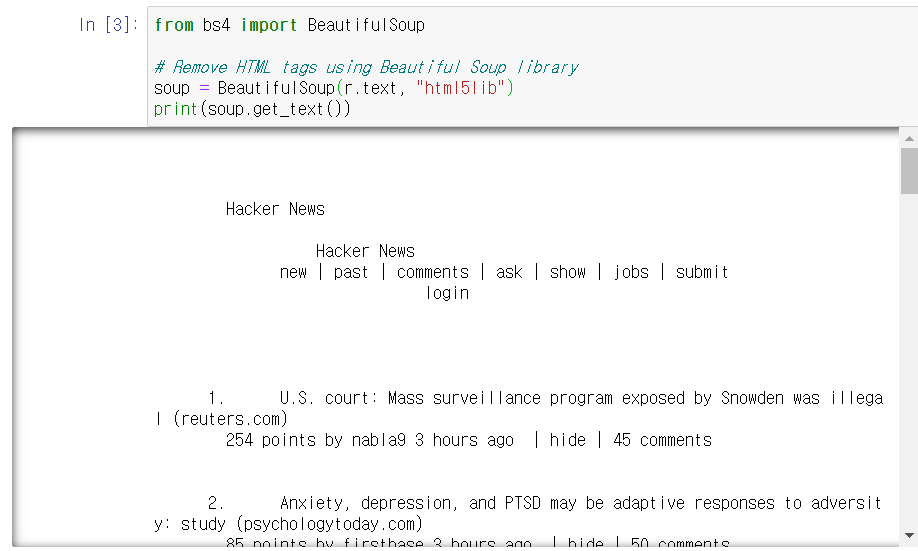
이 라이브러리로 읽어온 html 파일을 해석하니 우리가 원하는 정보가 사후처리 없이도 깔끔해진 것을 확인할 수 있다.
하지만 여전히 JS 와 굉장히 많은 space가 있는 것을 볼 수 있다.
그래서 문서를 다시보니
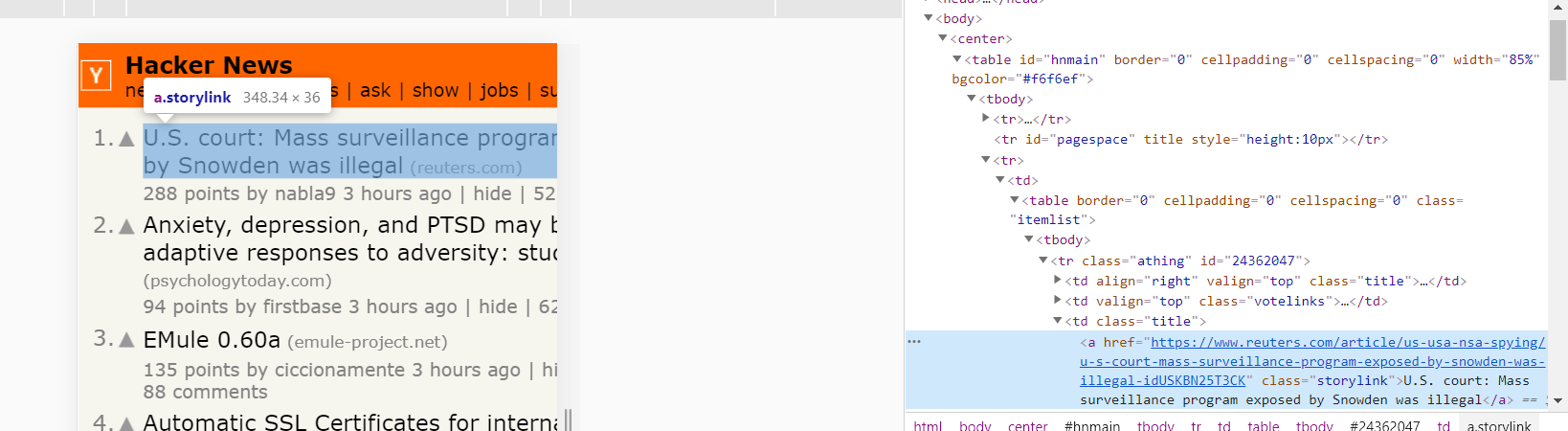
문서 자체가 <tr> 태그에 많이 겹치어져 있는 것을 확인할 수 있다.

그랫 다시금 beautifulsoup 을 이용하여서 해당 태그들을 모두 제거한 내용 만이 존재하도록 가지고 와 보자

이거 이외에도 css와 js로 쓰여진 부분도 함께 제거하여 보자

7. Stop Words Removal
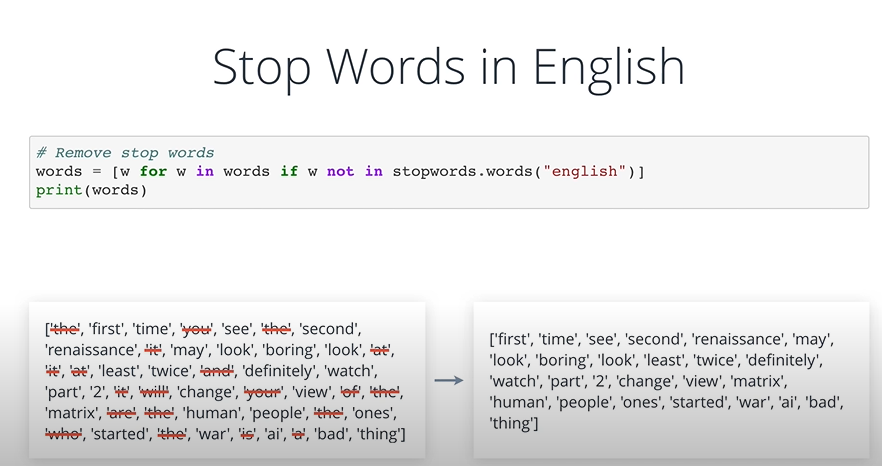
stop word는 문장에서도 반드시 필요하지 않은 부분들을 이야기 한다. 대표적으로 is, are, a, an, the 과 같은 이야기 한다.
nltk 에서는 Stop Words를 제공한다.

from nltk.corpus import stopwords
print(stopwords.words("english")위의 명령어를 통해 nltk에 저장되어 있는 stop words를 확인할 수 있다.
이것을 활용하여서 python을 통해 stop words를 제거한 토큰화된 단어모음을 만들 수 있다.
8. Part-of-Speech Tagging
영어 단어에는 품사라는 개념이 존재한다. 이것은 단어별로 명사 부터 동사까지 각 단어의 쓰임에 따라 제각기 다른 품사가 존재하는 것이다.
- NNP: 단수 고유명사
- VB: 동사
- VBP: 동사 현재형
- TO: to 전치사
- NN: 명사(단수형 혹은 집합형)
- DT: 관형사
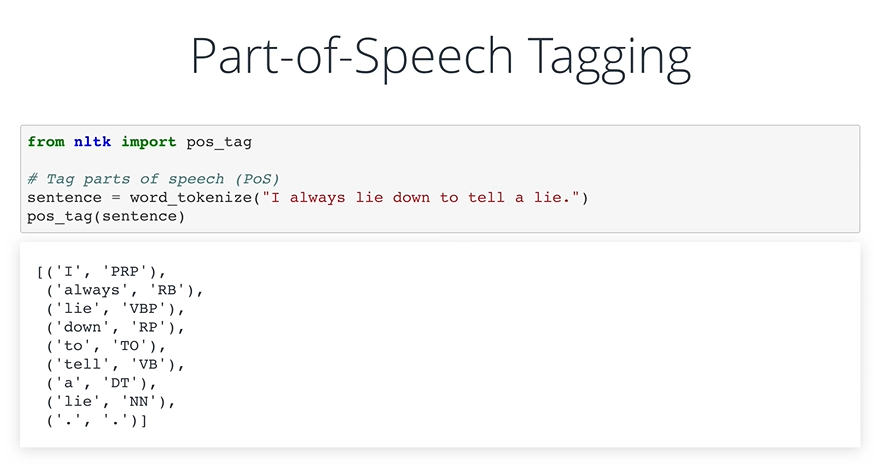
이러한 일을 파이썬에서 해주기 위해서는 nltk 패키지내부에 있는 pos_tag 함수를 사용하면 된다.

혹은 pos_tag함수가 제대로 작동하지 않는다면 우리가 자체적으로 tag를 남기어 주는 것도 좋은 방법이다.
9. Named Entity Recognition
Named Entity는 고유명사를 이야기 한다. 특정한 사람부터 객체까지 그 범위가 나뉘어져 있다.

이를 nltk 라이브러리에 있는 ne_chunk를 이용하여서 표시하면 위와 같이 고유명사가 나뉘어 지는 것을 확인 할 수 있다.
10. Stemming and Lemmatization
단어를 더 표준화하는 방법중에는 Stemming(어간 추출) 과 Lemmatization(원형 복원)이 존재한다. 이를 이용하여서 단어의 가장 기본이 되는 형태를 찾아낼 수 있다.
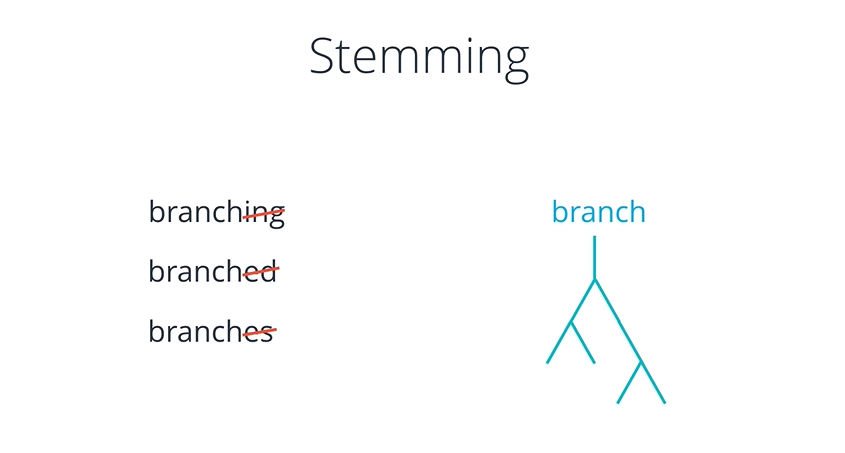
이러한 방식을 통해 기계가 이해하기 복잡한 단어를 좀 더 단순화 시키어 주어 기계의 성능을 높이어 준다.
Steeming

nltk의 steeming 함수를 사용하는 것은 빠르지만 정확도는 떨어지는 분석 결과를 보여준다.
예를 들어 people은 e가 살아지는 것과 같이 말이다.
Lemmatization
은 WordNet에 존재하는 사전을 사용하여 원형을 찾아내는 방법이다. 속도는 느리지만 정확도는 괜찮은 편이다.
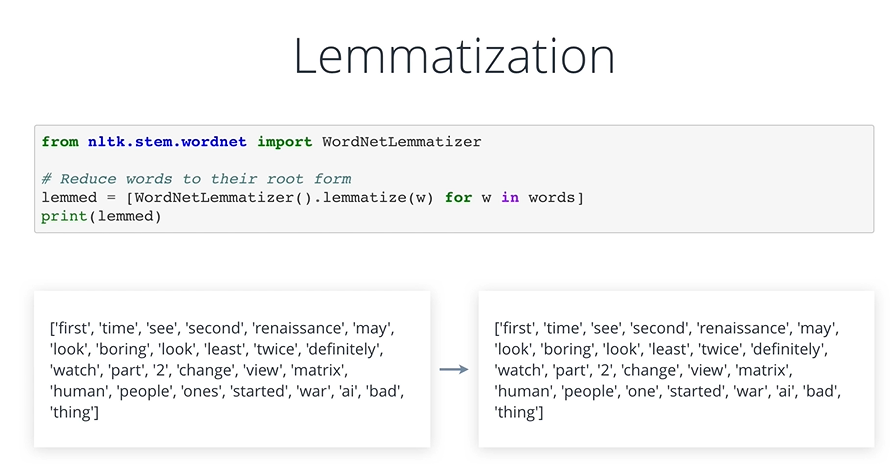
Default상태에서 진행한 Lemmatization의 결과는 큰 변화가 보이지 않는다.

그래서 코드에 직접 pos='v' 라는 인덱스를 통해 동사를 원본 형태로 바꾸어 줄 수 잇는 코드를 구현하였다.
11. Exercise: Process Tweets
12. Text Processing Coding Examples
13. Summary

