참고: 퀀트 투자를 위한 머신러닝, 딥러닝 알고리즘 트레이딩
https://opentutorials.org/module/3653/22071
모델을 설계하는 목적은 오차를 최소화 하기 위해서지만, 오차 중에서도 축소가 가능한 부분과 불가능한 부분이 있다.
축소가 안되는 건 1. 설명 가능 변수의 부재 2. 자연적 변이 3. 측정 오차에 기인한 랜덤 변이
축소가 되는 건 1. 편향(bias) 기인 오차 2. 분산 기인 오차.
정답과 예측이 멀리 떨어졌으면 편향이 큰 것이고, 예측값들끼리 떨어져 있으면 분산이 큰 것. 과녁을 이용해서 보통 설명한다. 한 가운데가 정답이면, 평균은 가운데 근천데 서로 많이 떨어져 있으면 분산이 큰 거고, 평균치 자체가 과녁의 한 끝쪽이면 편향이 큰 것.
출처: https://opentutorials.org/module/3653/22071
식으로는, 
이게 편향

이게 분산이다. 식을 보면 명확하다.
편향은 모델이 실제에 비해 너무 단순할 때, 분산은 너무 복잡할 때 커지게 된다. 모델이 복잡할 수록 좋은게 아닌가 싶을수도 있지만, 그러면 주어진 데이터에 대해 너무 최적화를 하기 때문에 데이터에서 조금만 달라져도 오차가 커지게 된다.
따라서 이 둘은 서로 트레이드 오프 관계가 된다.
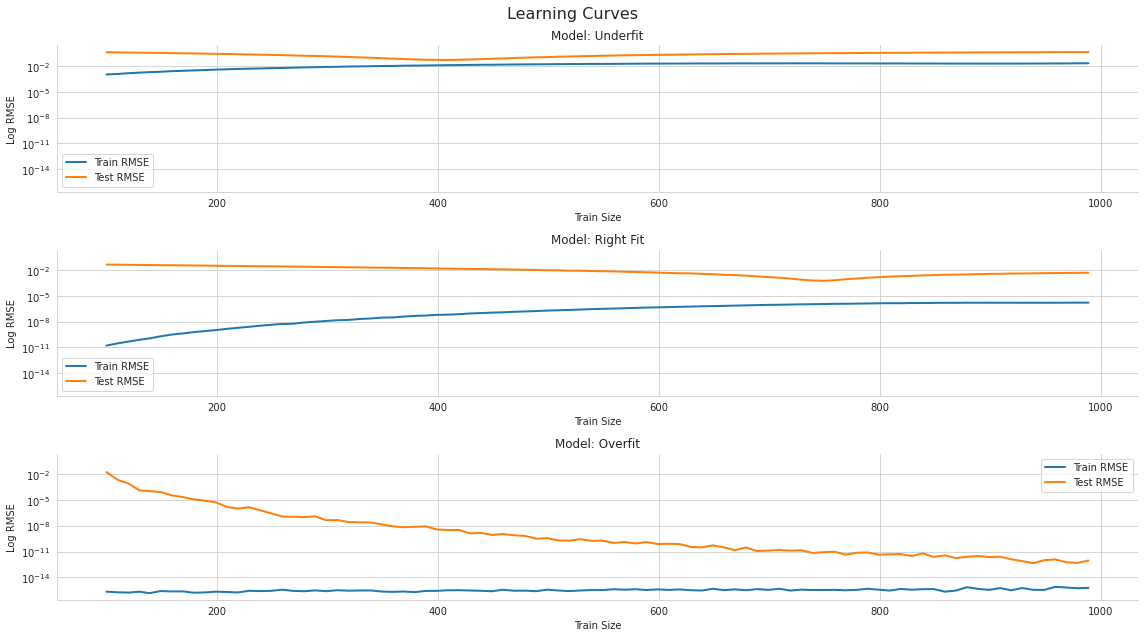
데이터 크기에 따른 학습 곡선은 위와 같이 나왔으며, 꽤 일반적인 케이스이다.
모델이 단순한 경우는 데이터가 많아져도 유의미한 변화를 가져오지 못한다. 반면 모델이 복잡한 경우, 테스트 오차가 유의미하게 감소하는 것을 확인할 수 있다.
여러 모델 중에 제일 나은 모델을 선택할 때 가장 중요한 목적은 가장 예측의 오차가 낮은 모델을 선택하는 것이다. 따라서, 모델 훈련의 부분이 아니었던 데이터에 대한 테스트가 필요하다.
하나의 훈련 데이터에 대해 여러 테스트 데이터를 사용하는 대신 흔히 사용되는 것은 전체 데이터중에서 검증 데이터로 쓰는 부분을 다르게 하면서 검증을 진행하는 것이다. 이게 cross validation이다. 처음 데이터에서 테스트 세트는 분리해 놓고, 나머지에 대해 훈련세트와 검증 세트를 바꿔가면서 검증을 진행한다.
다만 중요한 점은 데이터가 IID(독립적으로 동일한 분포)를 따른다고 가정하므로, 주식 같은 시계열 데이터에는 이것이 가능하지 않다. MNIST등의 데이터는 가능하다. 시계열 데이터에서 불가능한 이유는, lookahead bias을 피해야 하기 때문이다. 예측하고자 하는 미래의 정보를 과거 훈련 세트에 포함시키면 이런 편향이 생기게 된다.
CV를 시행할 때, 하이퍼 파라미터를 조정해가면서 시행하게 된다.
파이썬의 sklearn.model_selection에 관련 함수가 들어 있다.
from sklearn.model_selection import (train_test_split,
KFold,
LeaveOneOut,
LeavePOut,
ShuffleSplit,
TimeSeriesSplit)
들이다.
train,test=train_test_split(data, train_size=.8)
kf = KFold(n_splits=5)
for train, validate in kf.split(data):
: 데이터셋을 중복되지 않게 분할. 여기에 random_state값을 주면 동일한 결과를 재생산 가능하다.
loo = LeaveOneOut()
for train, validate in loo.split(data):
하나의 데이터만 검증 세트로 사용. 모든 데이터에 대해 검증 데이터로 사용해 보게 되며, 이로 인해 학습되는 모델의 수가 극대화 된다. 대신 비용도 커진다. 또한 훈련세트 자체가 매우 중첩되므로, 모델의 수와 예측 오차 간의 상관관계가 증가된다.
lpo = LeavePOut(p=2)
for train, validate in lpo.split(data):
위에서 한개 대신 p개를 검증 데이터로 사용.
ss = ShuffleSplit(n_splits=3, test_size=2, random_state=0)
for train, validate in ss.split(data):
매 검증 세트를 랜덤으로 만든다. 위의 코드들은 검증 데이터 셋이 각각 겹치지 않도록 만들어지는 데 반해 이는 랜덤으로 생성해 주므로 중첩이 가능하다.
시계열 데이터는 위의 방법을 어느 하나 사용할 수 없다. 미래 데이터를 사용해 과거 데이터를 예측한다는 것은 데이터 스누핑에 해당될 만큼 가정을 위반하는 모델을 만들게 된다. 따라서 다른 방식으로 세트를 만들게 되는데, 예를 들어 0~9까지의 숫자 데이터를 상대로 아래 코드를 사용하면
tscv = TimeSeriesSplit(n_splits=5)
for train, validate in tscv.split(data):
01234 5
012345 6
0123456 7
01234567 8
012345678 9
처럼, 시간 순서를 위배하지 않으면서 데이터를 분할해 준다. 여기에 max_train_size를 이용해 훈련세트의 크기를 유지시키는 방법도 있다.
시계열 데이터의 경우, 추가 제약을 부과하는 경우도 있다. 예를 들어, 재무 공시가 특정 기간에 대한 언급을 하더라도 발표되는 그 날까지는 데이터에 포함시키지 않는 것이다. 이에 대한 몇 가지 방법은
1. 제거: 검증 세트에서 선견 편향을 일으킬 수 있는 데이터를 제거
2. 엠바고: 테스트 기간을 따르는 훈련 표본 제거
3. 조합적 교차 검증: T개의 관측치가 주어질 때, 순서를 유지하는 N<T 개의 데이터에 대해 가능한 모든 훈련/테스트 분할 계산
