상호정보량을 이용해 사용할 특성 선택하기.
sklearn에 들어 있다.
from sklearn.feature_selection import mutual_info_classif
pd.get_dummies를 이용해 column들을 dummy 변수로 바꾼뒤 사용한다. 예를 들어
month라면
dummy_df= pd.get_dummies(data, columns=['month'],prefix=['month'],prefix_sep=['_'])또한 pd.factorize를 통해 string데이터를 class 별로 나눠 놓을 수도 있다.
mutual_info = pd.DataFrame()
for label in target_labels:
mi = mutual_info_classif(X=features,
y=(targets[label]> 0).astype(int),
discrete_features=discrete_features,
random_state=42
)
mutual_info[label] = pd.Series(mi, index=features.columns)
이런식으로 column별 상호정보량을 얻을 수 있다.
위 식을 해석하면, 각 feature에 대해 target에서 0을 기준으로 수익률을 1혹은 0으로 바꾼뒤, month나 year같이 dummy로 바꿔서 써야 되는 discrete feature의 col숫자를 전달한다.
sns.heatmap(mutual_info.div(mutual_info.sum()).T, ax=ax, cmap='Blues');
그러나 discrete 데이터를 그냥 전달하는 대신, dummy화 해서 전달하는 것이 훨씬 좋은데, 아래 그래프를 보면 알 수 있다.
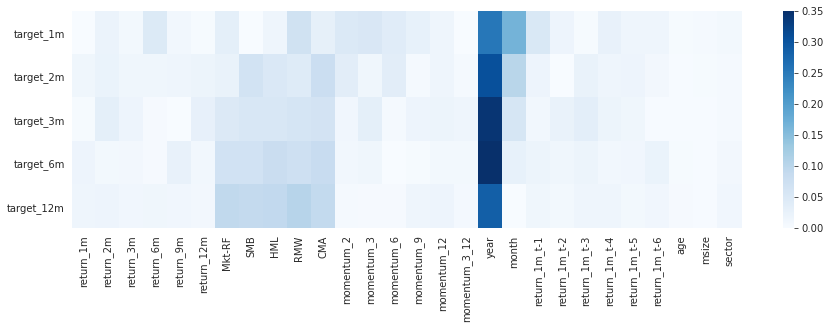
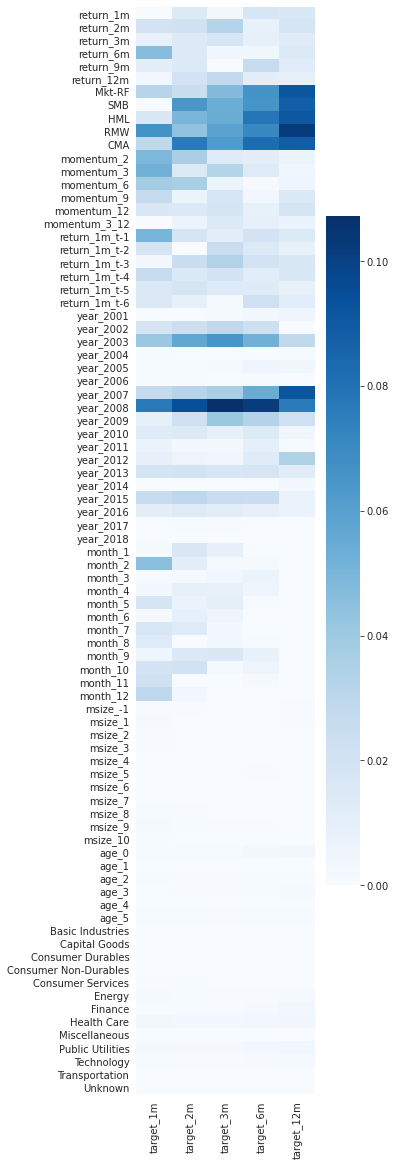
위를 보면, year가 너무 영향이 커서, 다른 요소는 잘 드러나지 않는다. 하지만 이를 세부적으로 쪼개보면 저 결과가 2008년, 그리고 그 직전에 의해 크게 왜곡된 것을 알 수 있다. 이것이 분산되므로 다른 요소들이 영향을 끼치는지를 좀 더 알 수 있게 된다. 섹터에 비해, risk factor들이 좀 더 영향을 줬던 것을 확인할 수 있고, 이런 식으로 먼저 feature를 선택해서 분석할 수 있게 된다.
