Practical advice for using ConvNets

Using open-source implementations
많은 연구자들이 Github와 같이 인터넷에 코드를 공유
기반을 삼고 싶은 논문을 찾게 된다면 온라인에서 오픈 소스를 찾으면 된다.
-> 처음부터 코드를 짜는 것 보다 속도가 빠름
Transfer Learning
이미지넷과 같은 큰 데이터 세트를 학습해 고성능의 연구를 거친 모델의 가중치를 가지고 와서 우리의 신경망에 재구성해 사용하는 것
신경망의 오픈 소스를 다운 받을 때 코드만 받는 것이 아니라 가중치도 함께 받아야 한다.
1. 데이터셋이 작을 때
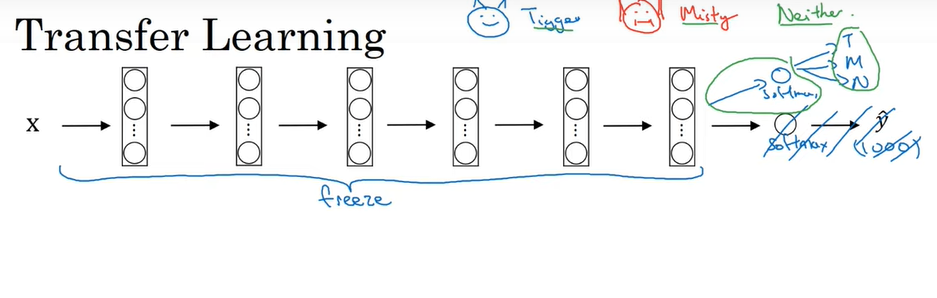
뒷단의 소프트맥스 레이어를 없애고 우리의 문제에 맞는 소프트맥스 유닛을 만든다.
-> 위의 문제의 경우 1000개의 class의 결과를 출력하는 것이 아니라 3개의 class 만 출력
앞단의 층들은 가중치는 고정(freeeze)하고 소프트맥스 층의 가중치만 훈련
빠르게 훈련하는 법:
고정된 레이어는 훈련시키지 않기 때문에 하나의 고정 함수가 발생해서 이미지 X를 특정 활성값으로 전달, 즉 미리 활성값을 계산하여 저장하면 계산 시간을 줄일 수 있음
2. 더 큰 데이터셋이 있을 때
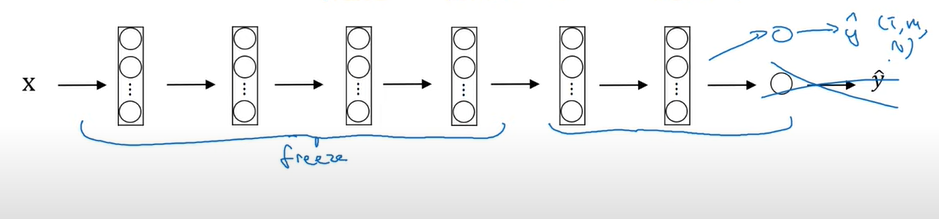
몇개의 레이어만 동결시키고 이후의 층들을 학습
마찬가지로 출력층의 클래스는 다르기 때문에 변경하여 학습
데이터가 많을수록 동결 레이어의 수는 줄고 훈련시킬 레이어의 개수는 늘어나게 됨
3. 아주 큰 데이터셋
무작위 초기화가 아닌 기존 오픈소스 네트워크의 가중치를 초기화 값으로 설정하고 네트워크 전체를 다시 훈련
Data Augmentation
데이터가 부족할 때 데이터 양을 늘리고 성능을 올리는 방법
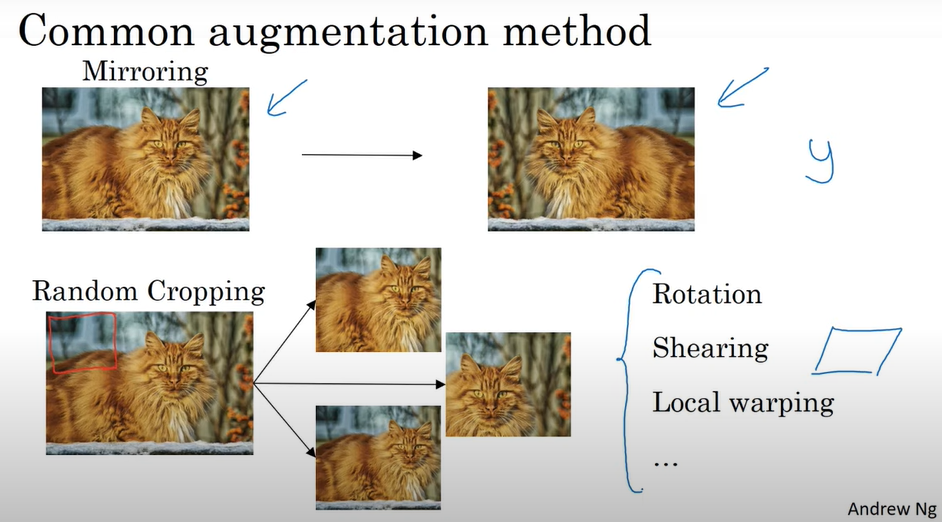
Mirroring
데이터를 대칭시킴
Random Cropping
데이터의 일부분을 자름
이 외에도 Data Augmentation으로 Rotation, Shearing, Local Warping이 있음
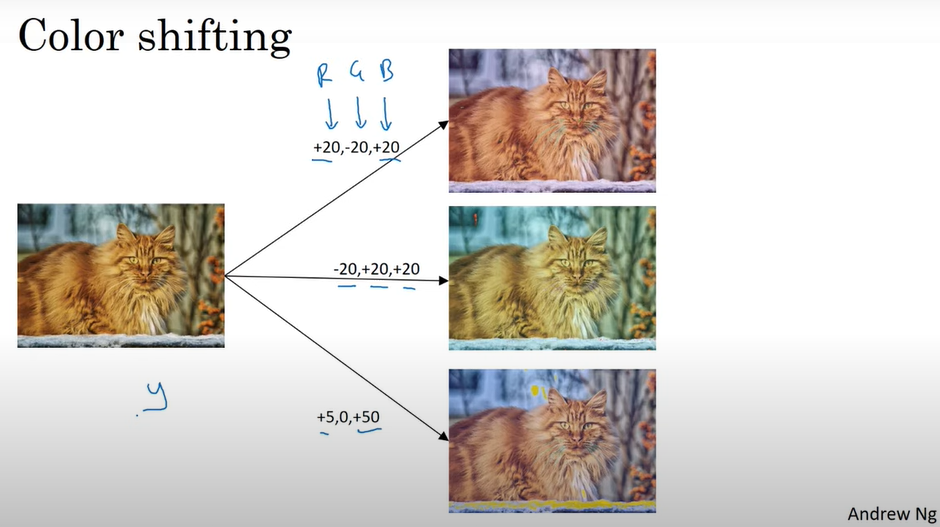
Color shifting
학습 알고리즘이 햇빛 등에 의한 색의 변화에 더 잘 반응할 수 있도록 해줌
RGB 각 채널에 서로 다른 수를 더한다. 예를 들면, 빨강 파랑이 더해지면 이미지가 보라색에 가까워짐
실제로는 위의 예시처럼 큰 변화가 아닌 RGB에 아주 작은 변화만 줌
RGB 표본을 만드는 방법:
색 변형을 하는 방법 중 하나가 PCA -> PCA 색 확대
데이터 변형 구현 방법
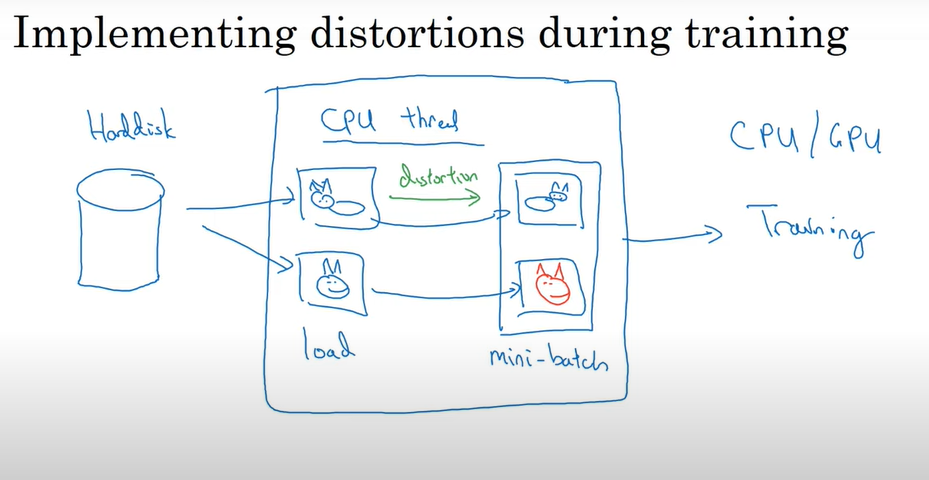
CPU 스레드를 통해 데이터를 디스크에서 불러오는 동시에 데이터를 변형시킴으로써 배치를 형성
참고: Albumentations: library for image augmentation
컴퓨터 비전 시스템을 구축하기 위한 팁 (The state of computer vision)
Data vs. hand-engineering
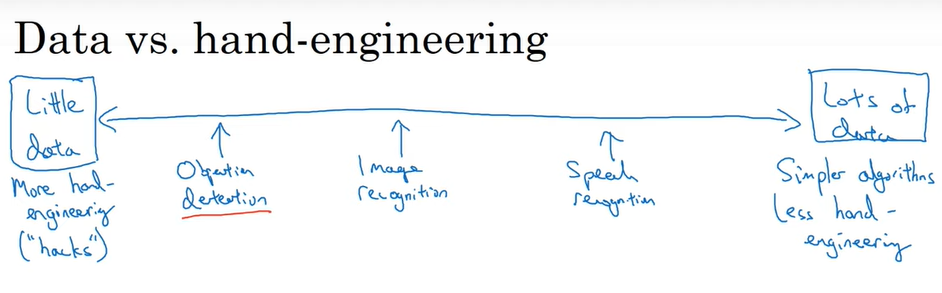
데이터의 양이 많으면 -> 간단한 네트워크 구조 사용 + 수작업이 적음
데이터의 양이 적으면 -> 복잡한 알고리즘 + 수작업이 많음
데이터가 적으면 Hand engineered features, network architecture, other components 등에 집중하며 전이 학습도 많은 도움이 됨.
데이터의 부재로 컴퓨터 비전에서 복잡한 네트워크 구조가 많이 등장함
Tips for doing well on benchmarks/winning competitions
Ensembling
여러개의 신경망을 사용하여 독립적으로 훈련 시킨 후 평균을 내는 것
시간 지연 발생 및 메모리 많이 필요
Multi-crop at test time

테스트 이미지에 적용되는 Data augmentation의 한 종류
테스트 이미지를 여러 버전으로 크로핑하여 classify 후 평균을 내서 결과를 얻는다.
위의 예시의 경우 이미지 원본에서 중간 부분, 모서리 4부분 cropping, 대칭된 이미지에서도 동일하게 중간 부분, 모서리 4부분 cropping
-> 10개의 이미지를 classify 후 평균을 내줌

3개의 댓글

15기 이윤정입니다.
- 전이 학습의 경우 큰 데이터셋을 학습한 고성능의 모델의 가중치를 가져와 사용하고자 하는 task에 대해 재구성하는 방법이다.
- Data Augmentation은 데이터가 부족할 때 데이터 양을 늘리고 성능을 올리는 방법이다.
- Color shifting은 학습 알고리즘이 햇빛 등에 의한 색의 변화에 더 잘 반응할 수 있도록 합니다.
- Multi-crop은 Data augmentation의 한 종류로, 여러 방식으로 crop하여 classify 후 평균을 내서 결과를 얻을 수 있다.

16기 전민진입니다
전이학습 시
- 데이터셋이 작을 때 : 뒷단에 특정 task에 특화된 layer로 수정, 앞단의 가중치는 freeze, 뒷 단만 학습
- 데이터이 클 때 : 몇 개의 레이어만 동결, 이후의 레이어는 학습
데이터가 부족할 경우 data augmentation을 통해 성능을 높일 수 있습니다.
data augmentation의 방법에는 - mirroring : 데이터 대칭
- random cropping : 데이터 일부분을 자름
- color shifting : RGB을 조금씩 수정
16기 김경준입니다.