[VATT 논문 리뷰](VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text)
Alethio-Intern_2023
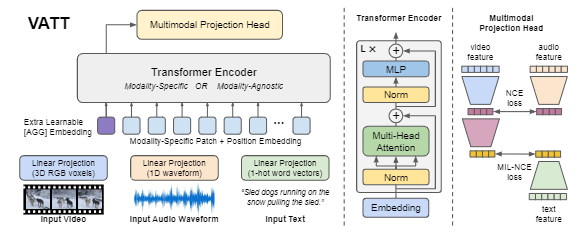
[VATT](VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text)
1. 논문이 다루는 Task
Task: Image,Video,Audio Classificaion
- Input: Video, Audio, Text
- Output: Class
2. 기존 연구 한계
2-1. Transformers requireLarge-scale supervised trainging data
NLP 분야에서 Transformer의 시대가 열렸다. 컴퓨터 비전의 분야에서도 이러한 Transformer를 성공적으로 적용시킨 대표적인 모델 ViT가 존재한다. 하지만 Transformer는 대규모 훈련 데이터 셋을 필요로 하며 NLP에서는 다음 토큰을 예측하거나 마스킹 기법을 이용하여 Self- Supervised Pre-Traning을 진행시켜 우수한 성능을 나타내었다. 하지만 비전 분야에서는 이미지 회전을 원래대로 돌린다든지 뚜렷한 Self- Supervised Pre-Traning 기법이 존재 하지않아 대규모의 Superviesd에 기반한 사람이 만들어 비용과 시간이 많이 드는 데이터셋이 필요로함을 강조하였다.
그래서 위 논문은 어떻게 하면 비전 분야에서의 Self- Supervised Pre-Traning 기법을 적용 시키는지 풀어나가는데 중점을 두고 있다.
3. 제안 방법론
3-1. Self-Supervised Learning
위 논문에서는 Self-Supervised Learning을 위해 Multimodal Video를 사용하게 된다.
Multimodal Video는 영상,소리,자막으로 구성되며 각각이 이미지,오디오,텍스트의 입력으로 들어가게 된다. 최근들어 Contrastive Learning의 성공적인 방법으로 인해 위 이미지,오디오,텍스트를 이용해 Contrastive Learning을 수행하여 Pretraining을 진행시킨다.
3-2. Tokenization and Positional Encoding
기존의 ViT 혹은 NLP에서의 Transformer의 Positional Encoding을 확장시킨 개념이라고 볼 수 있다.
- Video
비디오의 경우 입력이 xxx로 구성되며 각각 시간,가로,세로,채널 축이다. 이를 특정 패치의 갯수만큼 나누어 준다. x x 로 나누어 주게되며 각 패치는 결국 x x x 으로 구성이 된다. 이를 선형으로 한번 투영시켜 벡터 표현을 얻어낸 후 아래와 같은 포지셔널 인코딩을 적용시킨다.
간단히 각 축에 대하여 학습 가능한 매트릭스를 만들어 이후 다 더해주는 방식을 취한다.
- Audio
오디오의 경우 의 input이 들어오게 된다. 이를 세그먼트로 분할 시킨 후 로 선형 변환 시킨다.
추후 학습 가능한 임베딩을 사용하여 각각의 (세그먼트)마다 적용시킨다.
- Text
전체 단어 집합에서 사이즈의 어휘 사전을 구성하고 이를 임베딩 시킨다. 추후 포지셔널 임베딩 대신 다른 방법을 적용시킨다.
3-3. DropToken
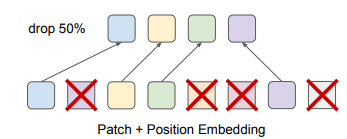
비디오와 오디오에 대해서만 단순히 전체 토큰을 사용하는 것이 아닌 일부의 토큰만 샘플링하여 Transformer의 입력으로 사용한다. 이때 논문은 Transformer의 계산 복잡도는 이 input sequence 일떄 인데 이 기법으로 FLOP을 줄였다.
또한 만약 입력 길이가 길면 메모리적인 문제가 발생하는데 이때 이미지를 resize하는 방법보다 이러한 방법이 더 효과적이라고 주장한다.
Drop Token은 비디오의 경우 기존의 다른 데이터와 달리 중복성이 매우 높으므로 이러한 방법이 효과적이라고 주장한다.
3-4. The Transformer Architecture
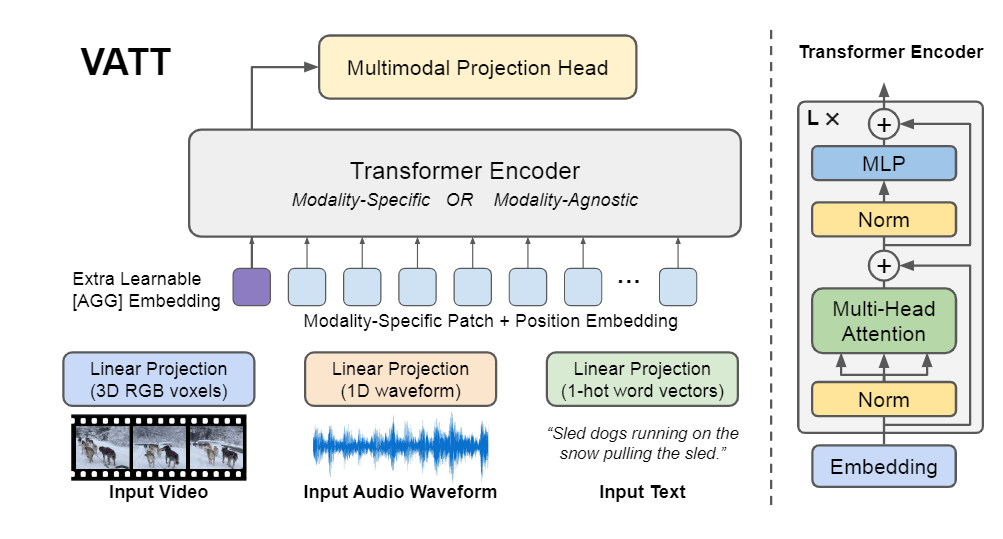
VATT는 NLP에서 사용하는 Transformer 구조를 그대로 사용하였으며 ViT와 매우 유사하다. 추후 확장성을 고려하여 그대로 사용하였다고 한다.
Transformer의 입력되는 input은 위와 같이 구성된다. AGG는 일종의 Class Token 처럼 추후 분류에 사용되는 스페셜 토큰이다.
여기서 중요한것이 인데 전체적인 VATT의 모델은 아키텍처는 총 2가지의 버전이 있다.
-
Video Transformer, Audio Transformer, Text Transformer을 각각 구성하여 각각의 Transformer의 출력을 Contrastive Learning을 수행하는 modality-specific 방법
-
Video Transformer, Audio Transformer, Text Transformer을 각각 구성하지만 가중치를 공유하는 modality-agnostic 방법이 존재한다.
그럼 위에서의 Text Transformer에 사용되는 의 경우 포지셔널 임베딩 대신 Multi Head Attention 모듈의 첫번째 레이어에 학습 가능한 relative bias를 추가하여 학습을 진행하였다고 한다.
이러한 변환을 통해 Text Transformer는 T5로 가중치를 바로 전달이 가능하게끔 만들었다고 한다.
3-5. Common Space Projection
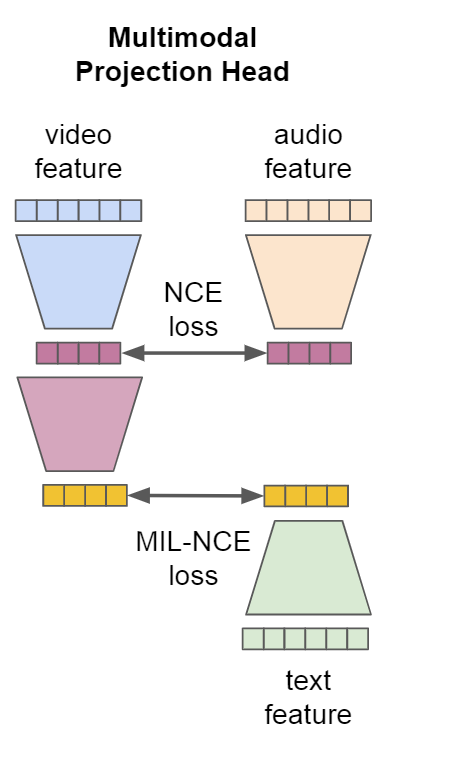
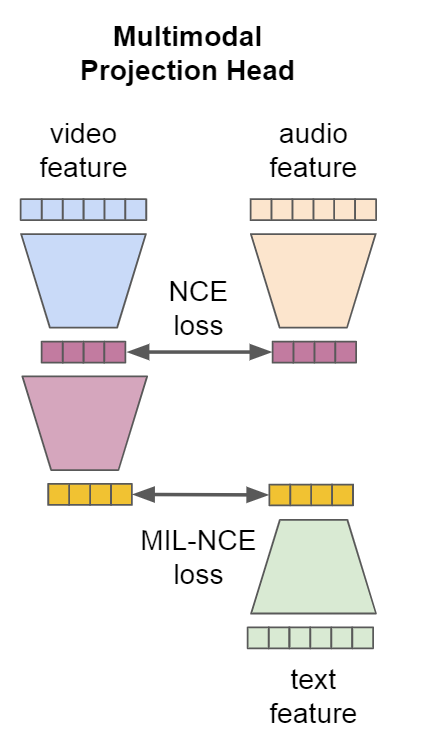
각각의 Transformer 마다의 나온 출력을 Pretrain을 위해 Contrastive Learning 시킨다. 이를 위해 학습을 수행 할 대상끼리 동일한 차원으로 전송시켜야한다.
위 논문에서는 비디오를 중간 매개로 Video-Audio, Video-Text끼리 Contrastive Learning을 진행시키는데 이를 위해 아래와 같이 같은 차원으로 전송시킨다.
와 는 모두 Video와 Audio를 같은 차원인 로 프로젝션 시키는 것이다.
주요 아이디어는 서로 다른 모달리티는 서로 다른 수준의 semantic granularity을 갖게 되는데 이러한 점을 multi-level common space projection에서 inductive bias로 작용시켜야한다는 점이다.
이때 의 경우 Linear Layer을 적용 시키며
의 경우 2개의 Linear Layer와 함께 ReLU를 적용시켰다.
각 레이어마다 훈련을 쉽게하기 위해 BachNorm을 적용시켰다.
3-6. Multimodal Contrastive Learning
위 논문에서는 video-audio pair에 대해서는 Noise Contrastive Estimation (NCE)를 사용하고 video-text pair에 대해서는 Multiple Instance Learning NCE (MIL-NCE)를 사용하였다.
이때 Positive Sample과 Negative Sample은 Video를 기준으로 Video와 비슷한 시간대의 경우에 대한 pair에 대해선 Positive Sample로 정의하고 다른 시간대의 경우 Negative Sample로 정의하였다.
MIL-NCE에서 은 배치에서 Negative pair인 부분이며. 의 경우 비디오에서 가장 가까운 시간대에 맞는 5개의 텍스트 Clip이다. 둘다 수식을 보게 되면 Video-Text의 기준에서 보게 된다. 는 positive와 negative 분리하는 목적함수에 softness을 부여하는 파라미터이다.
최종적인 Loss는 위와 같으며 Back-prop시 각 배치의 평균으로 계산된다고 한다.
4. 실험 및 결과
4-1. Fine-tuning for video action recognition
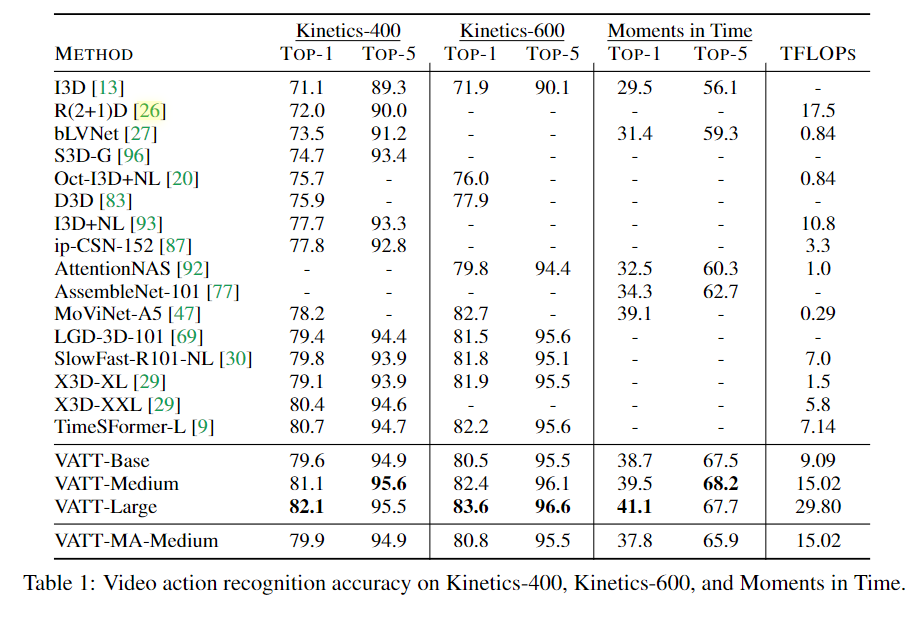
비디오에 대한 성능을 측정하기 위해 Kinetics-400,600, Moments im Time에 대해서 Video Transformer에 대해 Fine tuning을 진행한 후에 성능을 측정하였다.
3가지 데이터 모두 기존 모델들 보다 높은 성능을 달성하였으며 특히
VATT-MA-Medinum은 모달리티별 Transformer 모델들이 가중치를 공유한 모델인데 이때 VAT-Base와 비슷한 성능을 나타내었다. 이러한 결결과는 단일 Transformer backbone으로 여러가지의 모달리티를 통합 할수 있는 가능성을 내비쳤다.
TimeSFormer같은 경우 ViT로 초기화된 백본 모델을 사용하였지만 이보다 높은 성능을 달성하여 ViT가 지도학습으로만 초기화된거에 비해 Self-Supervised Learning만으로도 좀더 높은 성능을 달성 하였다.
4-2. Fine-tuning for audio event classification
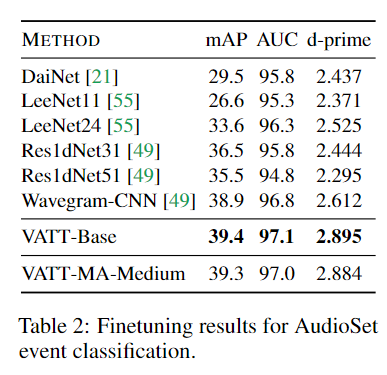
오디오 또한 Audio Transformer와 VATT-MA를 fine-tuning시켰다.
기존 CNN 기반 모델들보다 높은 성능을 달성하였으며 특이점으로 Transformer기반 모든 모델들중 CNN을 이긴 최초의 모델이 되었다.
비디오 분류와 마찬가지로 VATT-MA 모델은 Base와 비슷한 수준의 성능을 나타냈다.
4-3. Fine-tuning for image classification

이미지 분류의 경우 ViT 및 다른 모델들은 이미지에 대해 사전 훈련을 진행하였고 VATT는 비디오로 사전 훈련을 진행시켰다. 그럼에도 불구하고 ViT와 유사한 성능을 발휘하였으며 이는 컴퓨터 비전에서의 논문에서 주장한 Self-Supervised Learning이 많은 가능성이 존재하고 있다. 이때 네트워크 아키텍처를 수정하지 않아 voxel-to-patch layer를 만족시키기 위해 동일 이미지를 4번 입력시키도록 만들었다.
4-4. Zero-shot text-to-video retrieval
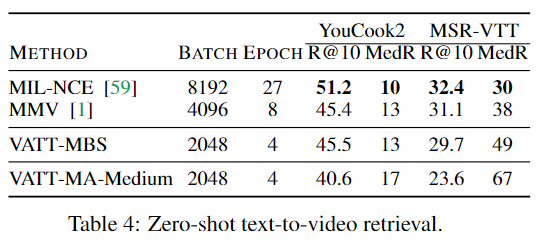
VATT-MBS 모델을 사용하고 공간 표현을 추출하여 진행하였다. 당연히 Constrative Learning으로 훈련된 만큼 retrieval이 가능하다. Text를 Query로 사용하여 Top 10의 코사인 유사도가 높은 비디오를 가져오게 된다.
이때 MMV와 마찬가지로 배치사이즈와 에포크 수에 따라 정확도가 크게 차이나는 현상을 발견하였다.
추가적으로 표에는 없지만 기존보다 큰 8192의 배치사이즈로 6에포크동안 훈련시킬경우 VATT의 성능은 YouCook2에서MIL-NCE와 완전히 동일하였으며 MSRVTT에서 R@10 29.2 / MedR 42의 성능을 기록하였다.
또한 비교적 텍스트 데이터에 노이즈가 많이 끼여 단순한 Linear만으로도 텍스트가 잘 작동한것을 보아 보다 고품질 텍스트를 탐구할 가치가 있다고 주장한다.
4-5. Feature visualization
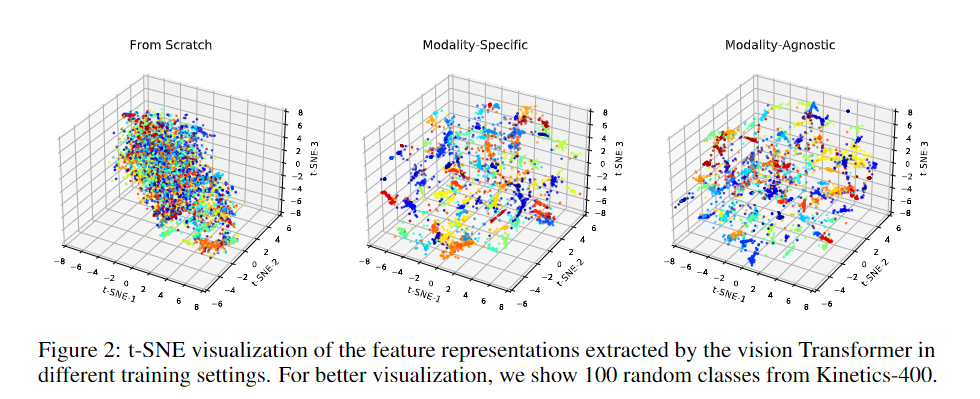
Kinentics-400 데이터셋으로 VATT를 훈련시켰을때 Pretraning이 없는 처음부터, 모달리티 별 Transformer, 가중치 공유 Transformer에 대해 t-SNE로 출력을 표현했다. 확실히 pretrain이 보다 유의미하게 공간이 나누어진것이 보였고 Modailty-Agnostic이 Modailty-Specific과 크게 차이가 없는 점에 대해 주목할 수 있다.
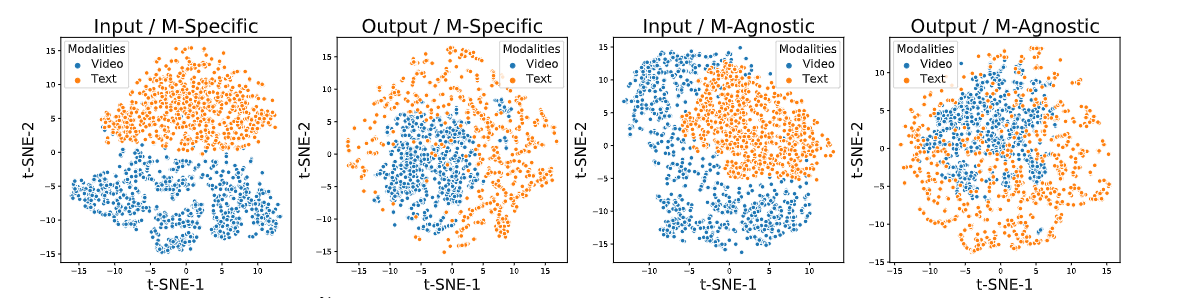
또한 추가적으로 Modailty-Specific과 Modailty-Agnostic이 배우는 표현에 대해 조사하였다. YouCook2 데이터셋에서 무작위로 선정된 1k개의 비디오를 대상으로 사용하였으며 두개의 지점에 대해 선정 하였다.
- Transformer의 Input space
- Transformer의 output space
위 두가지를 각각 시각화하였을때 Specific보다 가중치를 공유한 Agnostic이 좀 더 섞여 있는 현상을 볼 수 있다. 이는 모델이 다른 기호로 입력이 들어와도 같은 객체(개념)를 볼수 있다라고 논문에서 주장하며 이와 같은 현상은 NLP의 다국어 모델들인 multilingual 모델들과 유사하다고 나타난다.

랜덤하게 샘플링된 video-text pairs와 Positive pair를 얼마나 잘 구분하는지 확인하기 위해 pair-wise similarities를 계산하고 이를 KDE를 실행시켰다. 확인 결과 모두 다 잘 분리하는 결과를 확인하였으며 이는 Transformer 모델들끼리 가중치를 공유하더라도 공통된 space를 다양한 양식으로 학습을 진행하더라도 잘 학습이되는 VATT의 효율성을 검증하였다.
4-6. Model Activations
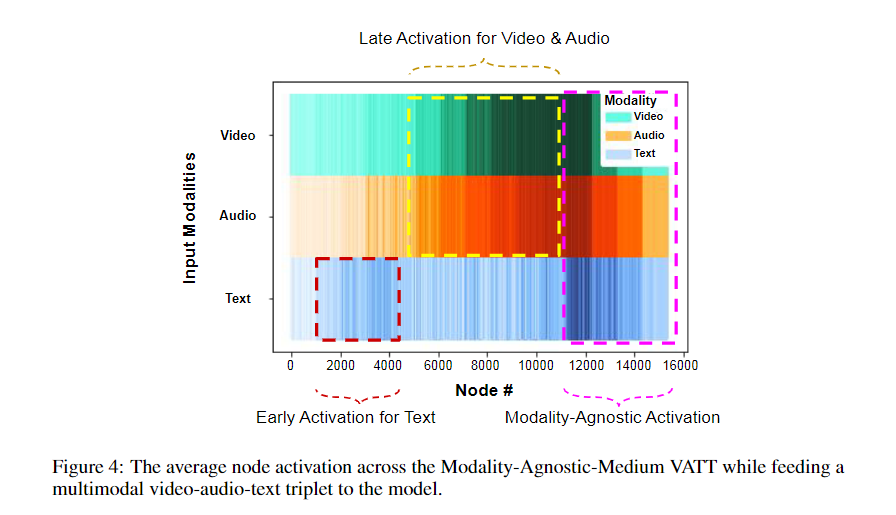
HowTo100M의 테스트 데이터셋을 100k의 비디오 클립을 사용하여 비디오와 오디오를 모델에 입력하였다. 이때 residual되기 전의 각각의 MLP 모듈에 대해 평균 활성화를 계산하였다.
그림으로 보았을때 Text는 초기에 활성화가 되고 Video와 Audio는 중간에 활성화가 되며 최종적으로는 마지막에 모두 활성화 되었다. 이는 모델별로 다르게 활성화를 시키지만 최종적으로는 같은 의미에 도달한다고 주장한다. 추가적으로 모델의 용량 증가를 위해 Mixture-of-Experts을 사용할 수 있다고 향후 연구로 남겨두었다.
4-7. Effect of DropToken
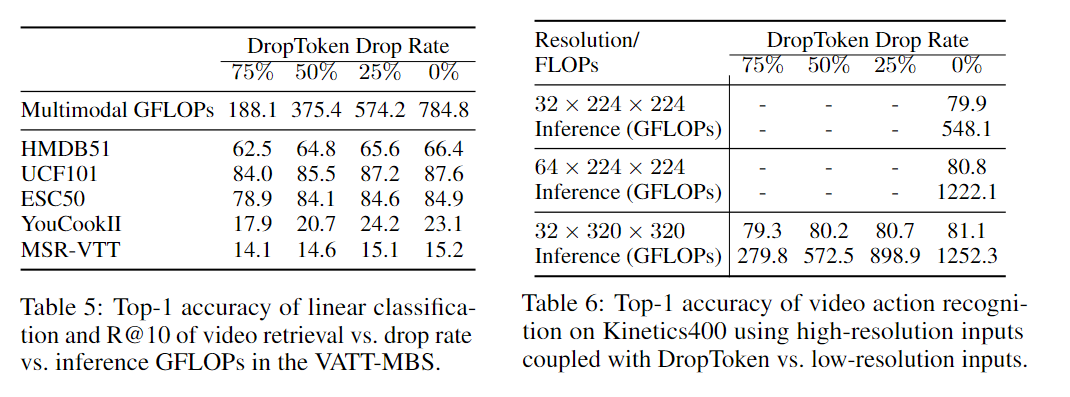
Drop Token의 %별 성능과 이미지 사이즈에 대해 Drop Token의 성능을 나타내었다. 이 실험에서는 Table 6)의 고해상도의 경우 64x224x224의 0%가 80.8%의 정확도와 1222.1의 인퍼런스 속도를 가지고 있는 반면 32x320x320의 겨우 80.7의 정확도에 898.9의 인퍼런스 속도를 지닌만큼 Drop Token이 이미지 사이즈를 줄이는 것보다 높은 효율성을 가지고 있다고 주장한다.
5. Conclusion
-
transformer 기반의 self-supervise multimodal representation learning을 제안하였다.
-
Transformer 기반의 모델이 여러 다중 모달리티를 학습하여도 통합하는데 효과적이며 multimodal self-supervised pretraining은 labeled large scale dataset에 대한 의존도를 줄인다고 주장한다.
-
Drop Token 기법은 pre-training complexity를 크게 줄이며 일반화 성능에도 영향을 미칠수있다.
-
Classififcation, Retrieval등 여러 방변에서 높은 성능을 달성하였다.
6. Limitation
- 모든 비디오가 음성과 Text를 가지고 있는 것이 아니어서 현재 우리의 연구에는 제한 사항이 존재한다.
- 텍스트의 경우 많은 노이즈가 존재하며 음성 또한 희박한 경우가 많다.
7. 회고
최근 멀티모달이 조금 재미는 있긴한데 시간이 없다보니 할 시간이 없는거 같지만 간간히 해야겠다. 저번에는 ImageBIND에 이어 VATT를 했는데 CLIP이나 ImageBIND쪽도 재미가 있지만 멀티모달에 대한 모델도 공부가 필요한것 같아 이 논문을 선택하였다.
