Alethio-Intern_2023
1.[HyperDreambooth 논문 리뷰](HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models)
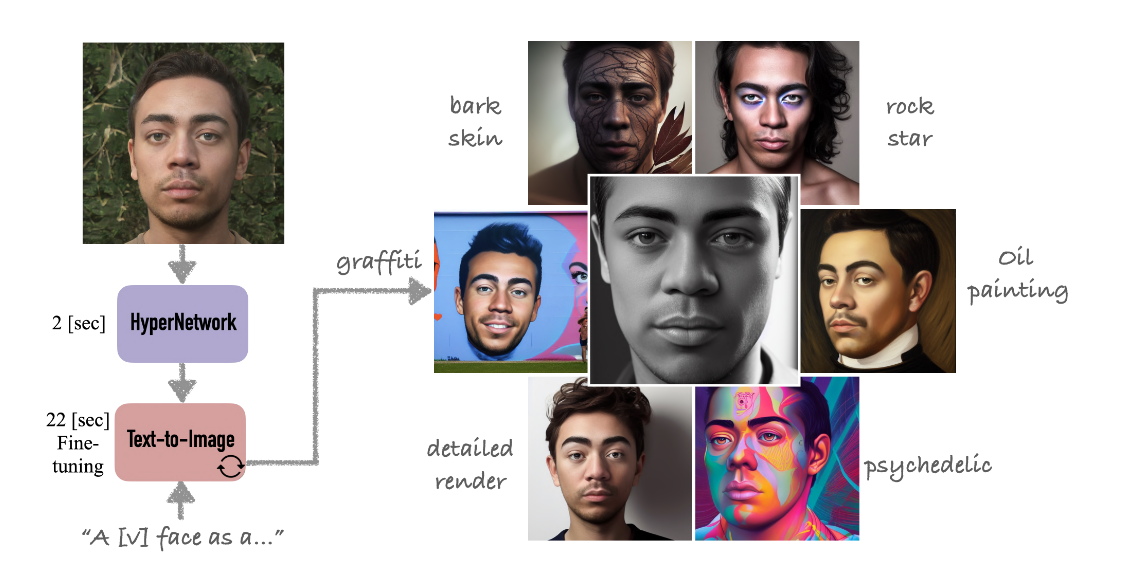
Task: Personalization of Text-to-Image GenerationInput: TextOutput: ImagePersonalization of Text2Image : 텍스트를 기반으로 이미지를 만드는 개인화된 생성 모델기존의 DreamBooth의
2.[ImageBind 논문 리뷰](One Embedding Space To Bind Them ALL)
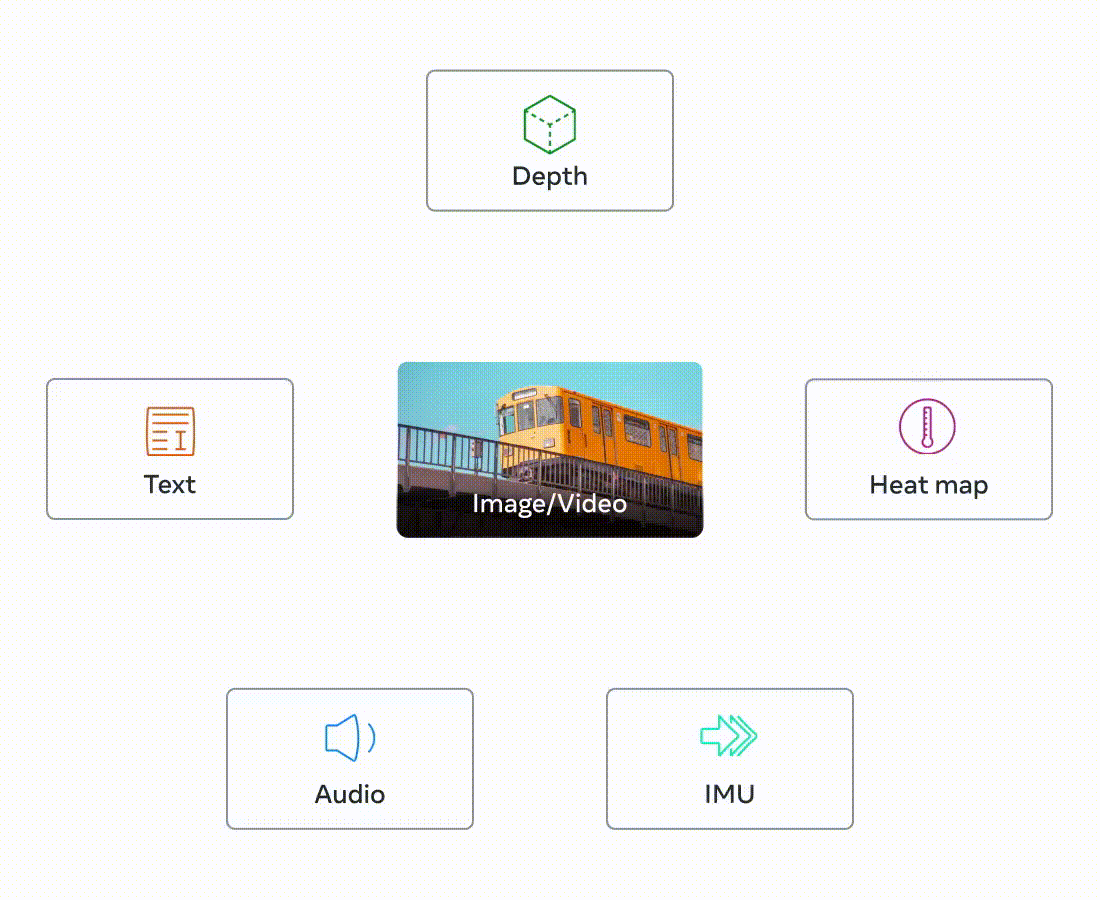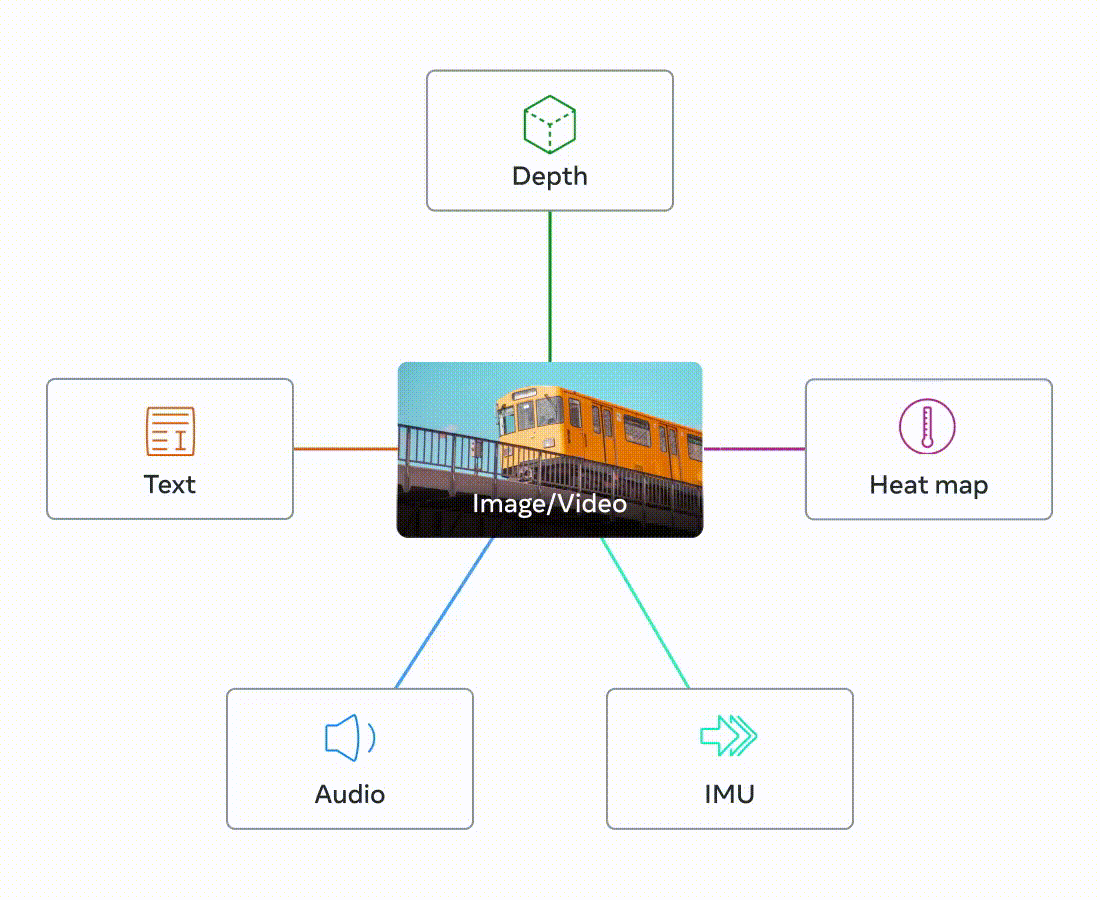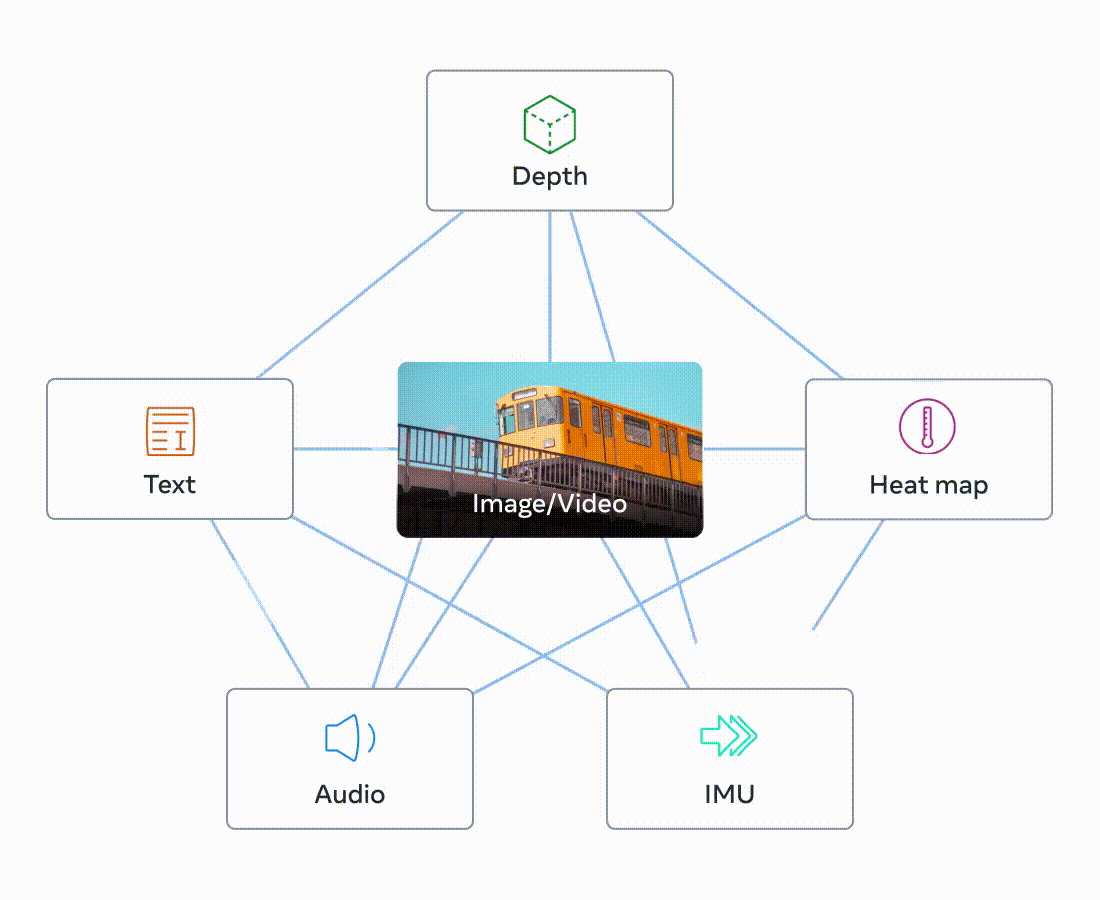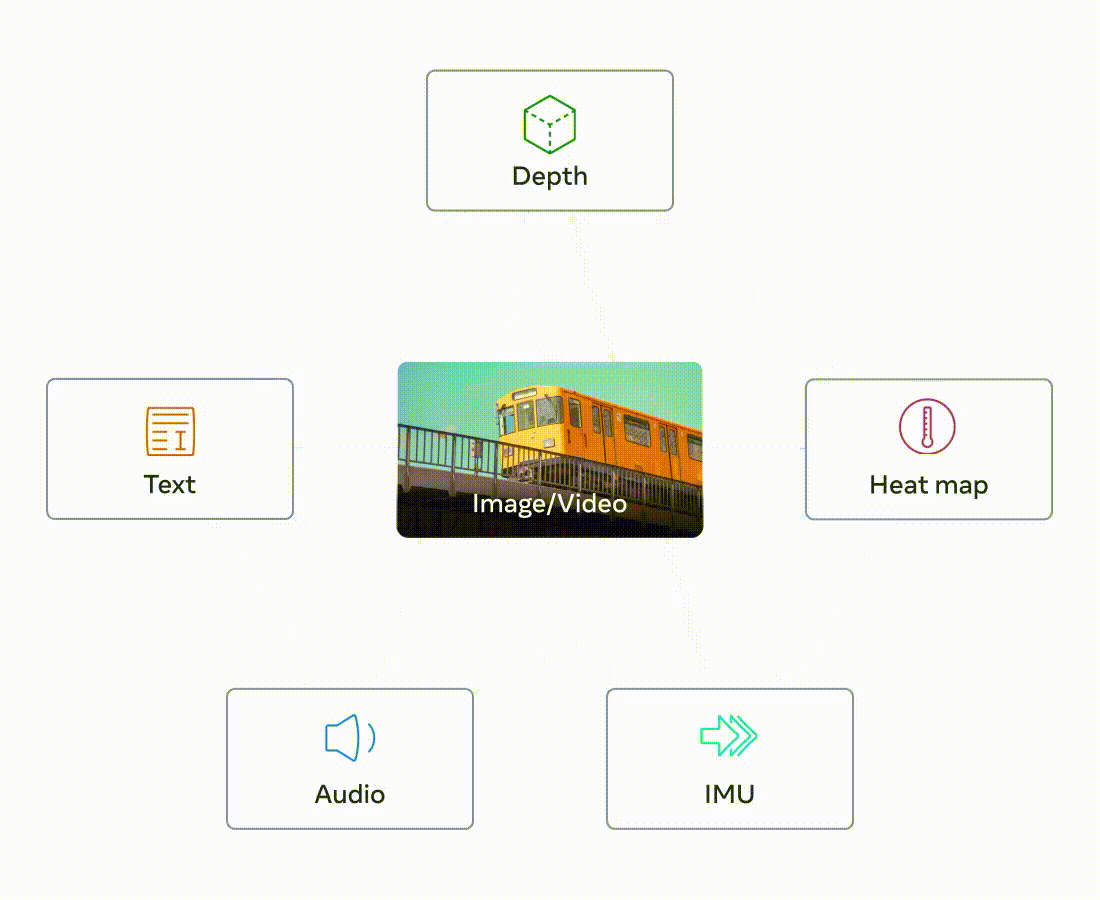
A single image can bind together many experiences – an image of a beach can remind us of the sound of waves, the texture of the sand, a breeze, or eve
3.[VATT 논문 리뷰](VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text)
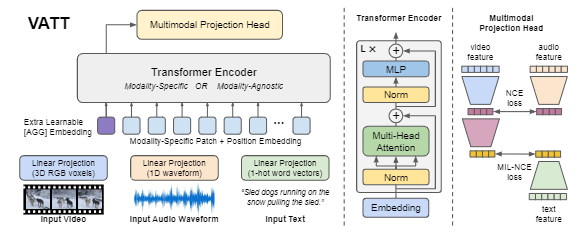
Task: Image,Video,Audio ClassificaionInput: Video, Audio, TextOutput: Class
4.[LLaVA 논문 리뷰](Visual Instruction Tuning)

LLaVA 1. 논문이 다루는 Task Task: Text Generation Input: Image, Text Output: Text 2. 기존 연구 한계 2-1. Text-Only 논문에서는 시작하자마자 인간은 다양한 신호로 세계를 관찰하고 있다는 점을 언급한다. 또한 최근에 나온 모델들인 Flamingo, BLIP-2 같은 모델은 비록 언어에...
5.[ALBEF 논문 리뷰]Align before Fuse: Vision and Language Representation Learning with Momentum Distillation

ALBEF 1. 논문이 다루는 Task Task: Vision-Language Input: Image, Text Output: Image-Text Retrieval, Visual Entailment, Visual Question Answering, Natural L
6.[FILIP 논문 리뷰]FINE-GRAINED INTERACTIVE LANGUAGE- IMAGE PRE-TRAINING
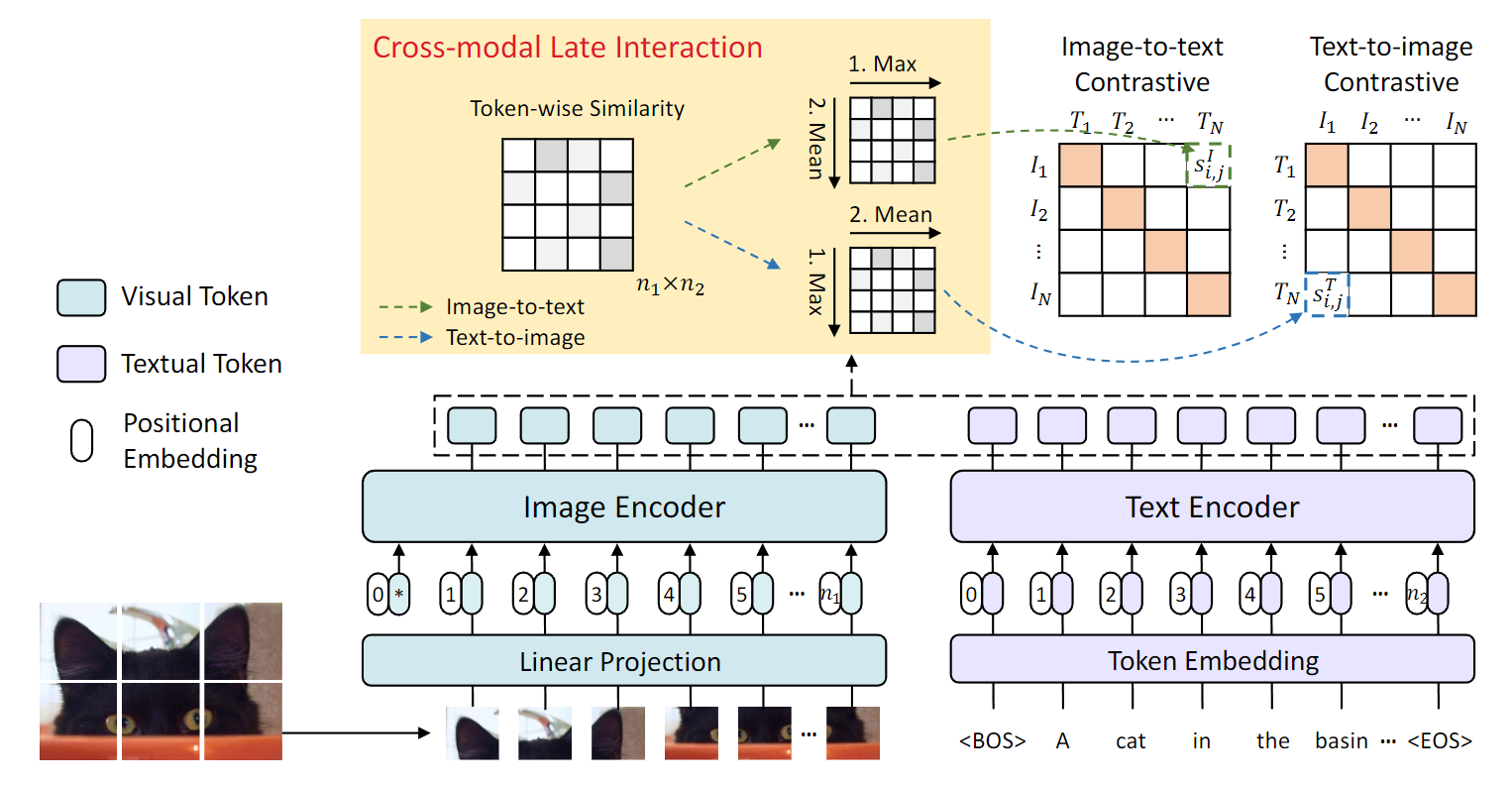
FILIP 1. 논문이 다루는 Task Task: Vision-Language Input: Image, Text Output: Image-Text Retrieval, Zero-shot Image Classification 2. 기존 연구 한계 2-1. Globa
7.[BEiT 논문 리뷰]BEiT: BERT Pre-Training of Image Transformers
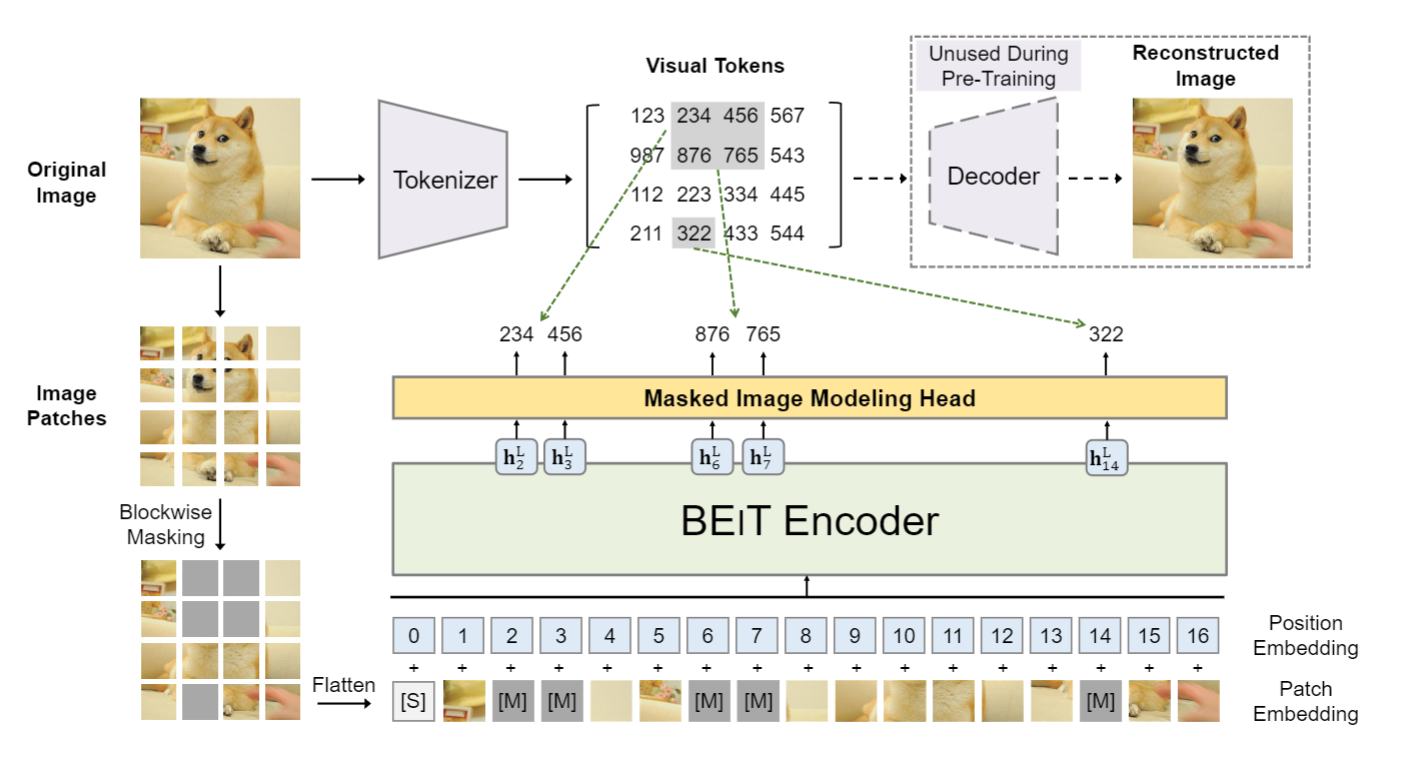
BEiT 1. 논문이 다루는 Task Task: Computer Vision Input: Image Output: Image Representation 2. 기존 연구 한계 2-1. Vision Transformers의 데이터 의존성 문제 컴퓨터 비전에서의 Transformer 모델들은 CNN에 비해 더 많은 학습 데이터를 필요로 한다. 이 문제를...
8.[SLIP 논문 리뷰]SLIP: Self-supervision meets Language-Image Pre-training

Task: Vision-LanguageInput: Image, TextOutput: Image Representation, Text Representation기존의 CLIP, AlIGN의 같은 모델은 각 Encoder의 CLS 토큰을 사용하여 Contrastive Le