3주차 - Stream processing
Apache Kafka
Apache Kafka란 데이터 파이프라인, 스트리밍 분석, 데이터 통합을 위한 오픈 소스 분산 이벤트 스트리밍 플랫폼(distributed event streaming platform)이다. 이벤트 스트리밍은 인체의 중추 신경계에 해당하는 디지털 처리 방식으로, 비즈니스가 점점 더 소프트웨어화, 자동화되는 시대의 대표적인 기술이다.
Apache Kafka는 이벤트 스트림을 지속적으로 발행(publish-write)하고 구독(subscribe-read)한다. 또한 이벤트 스트림을 원하는 만큼 내구성 있고 안정적으로 저장(store)을 하고 이벤트 스트림 발생 시 처리(Process)한다.
• https://github.com/apache/kafka
• Linkedin에서 개발됐다가 2011년 오픈소스화된 프로젝트(scala로 개발)
• 데이터 스트리밍을 위한 미들웨어
• app 간 메시지 전달을 위한 중개인 역할을 하는 메시지 브로커
• 비동기 처리를 위한 pub/sub 메시징 큐
• Pub/Sub model
• Data persistency
• Highly scalable and available
• High throughput and low latency
• at-least-once (최근 exactly-once도 지원)
Apache Kafka - Pub/Sub model
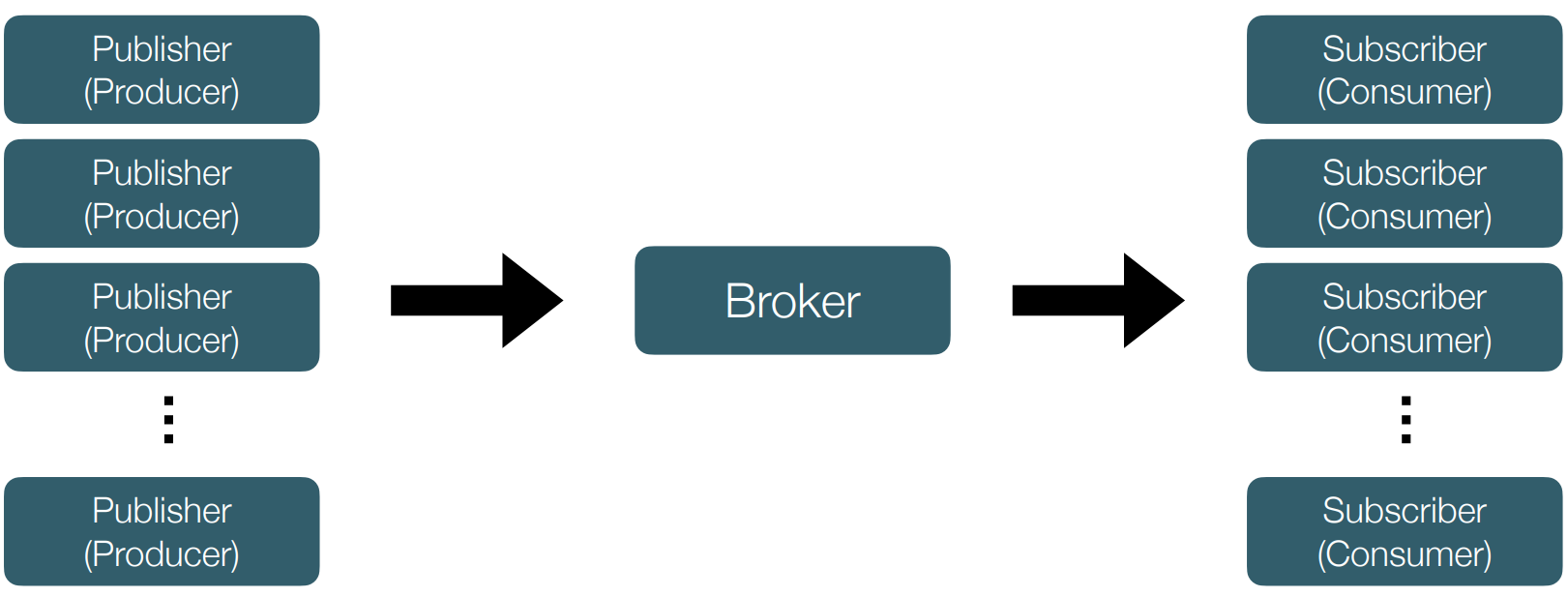
• 메시지나 이벤트를 브로커를 통해 주고 받는다.
• publisher(producer)는 메시지의 최종 목적지가 어디인지, 누가 가져가는지 고려하지 않는다. 최종 목적지의 주소나 관련 정보를 알 필요가 없다. publisher가 바라보는 곳은 메시지 브로커 뿐이다. ex) 쇼핑몰 쿠폰 발행, 어떤 손님이 쿠폰을 발행 했는지 관심 없음
• subscriber는 처리할 수 있는 만큼 메시지를 pull하면 된다. server-client 구조처럼
client가 push하는 방식이 아니다. subscriber가 장애가 나더라도 메시지는 브로커에 저장된다. 장애가 난 subscriber 노드는 다른 subscriber가 대체한다.
• App 간 느슨한 결합을 가능하게 해준다. 따라서 확장가능한 설계를 가져갈 수 있다.
Apache Kafka - Data persistency
• 메시지를 publisher(producer)에게 받는 즉시 스토리지에 저장한다.
in-memory로 가지고 있다가 최종 전달자에게 전송하는 즉시 삭제하는 메시지 큐와 다른 점
• Retention 기간 내 메시지라면 다른 subscriber(consumer)가 요청을 해도 같은 메시지를 전송할 수 있다.
즉, 이미 지나간 메시지도 제한 시간 내에선 얼마든지 구독 가능하다.
• 장애 처리 시 메시지 유실 방지
구조
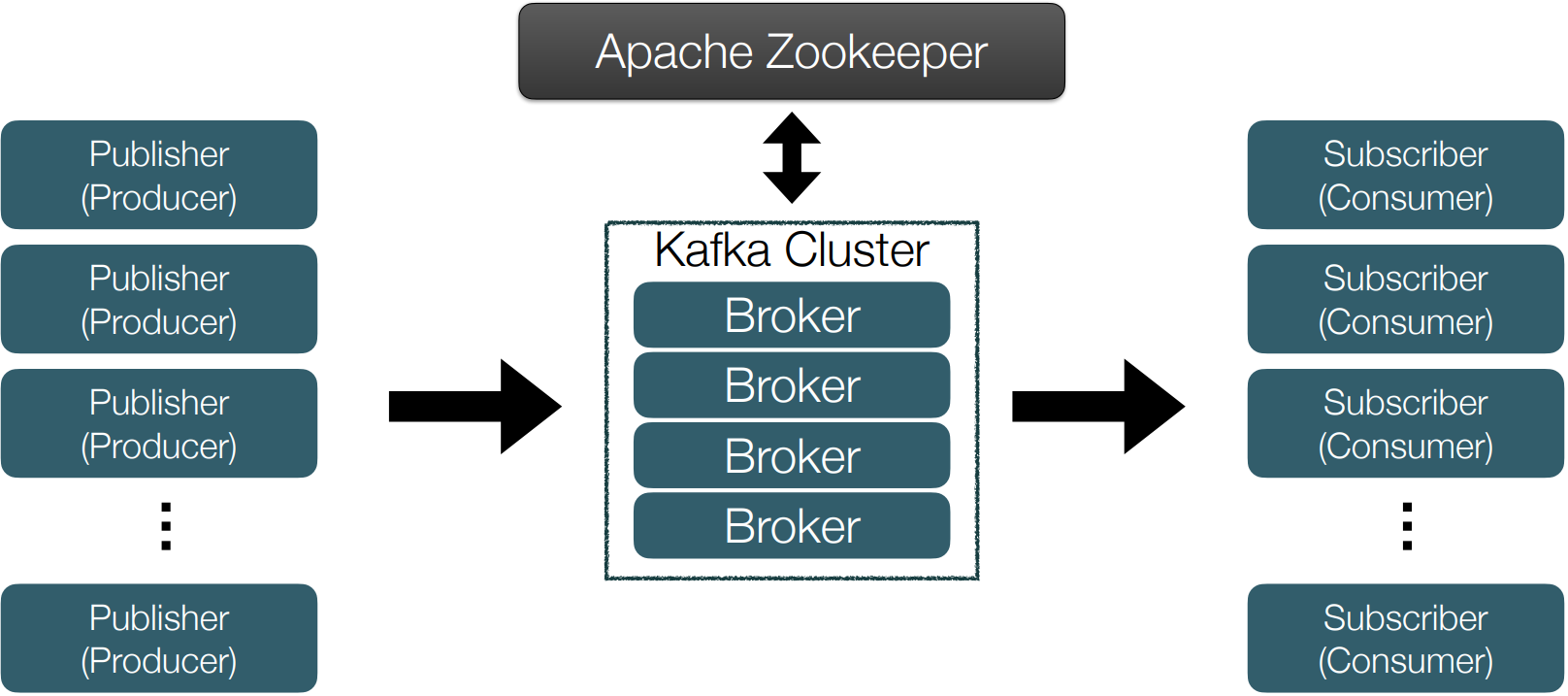
• 다수의 브로커가 클러스터링된 구조
클러스터링 : 하나의 데이터를 여러개의 부분집합(clusters)으로 분할하는 형태
Zookeeper
ZooKeeper는 분산 시스템에서 서비스 동기화 및 명명 레지스트리로 사용된다. Apache Kafka와 함께 작업할 때, Zookeeper는 주로 Kafka cluster의 노드 상태를 추적하고 Kafka 주제와 메시지 목록을 유지하는데 사용된다.
• 분산 코디네이터
• 분산된 카프카 브로커를 클러스터링해주는 핵심 컴포넌트
• 브로커 리더 선출
• 파티션 수와 같은 토픽의 메타데이터 관리, 정보 공유
• 새로운 브로커 추가, 브로커 장애 감지 등
• Topic이라는 채널을 만들고 해당 토픽에 producer가 메세지를 push하고 consumer가 pull해서 메시지를 소비하는 구조
주요 구성 요소
• 토픽(Topic)과 파티션(Partition)
• Replication
• Producer
• Consumer & consumer group
주요 구성 요소 - topic과 partition
• 토픽은 메시지들을 분류해주는 채널 같은 느낌
• 토픽은 여러 개의 파티션으로 나눠질 수 있다.
(단일 파티션일 경우, 내결함성이 떨어짐)
• 확장성(병렬 처리)을 위해 파티션이란 개념을 사용
• ※운영 상 주의 사항 : 파티션은 늘릴 순 있어도 줄일 순 없다.
Event : 과거에 발생한 사건들, Event가 발생함으로서 변화된 상태를 가지고 시스템 사이를 오가는, 불변하는 데이터이다.
Stream : 관련된 이벤트
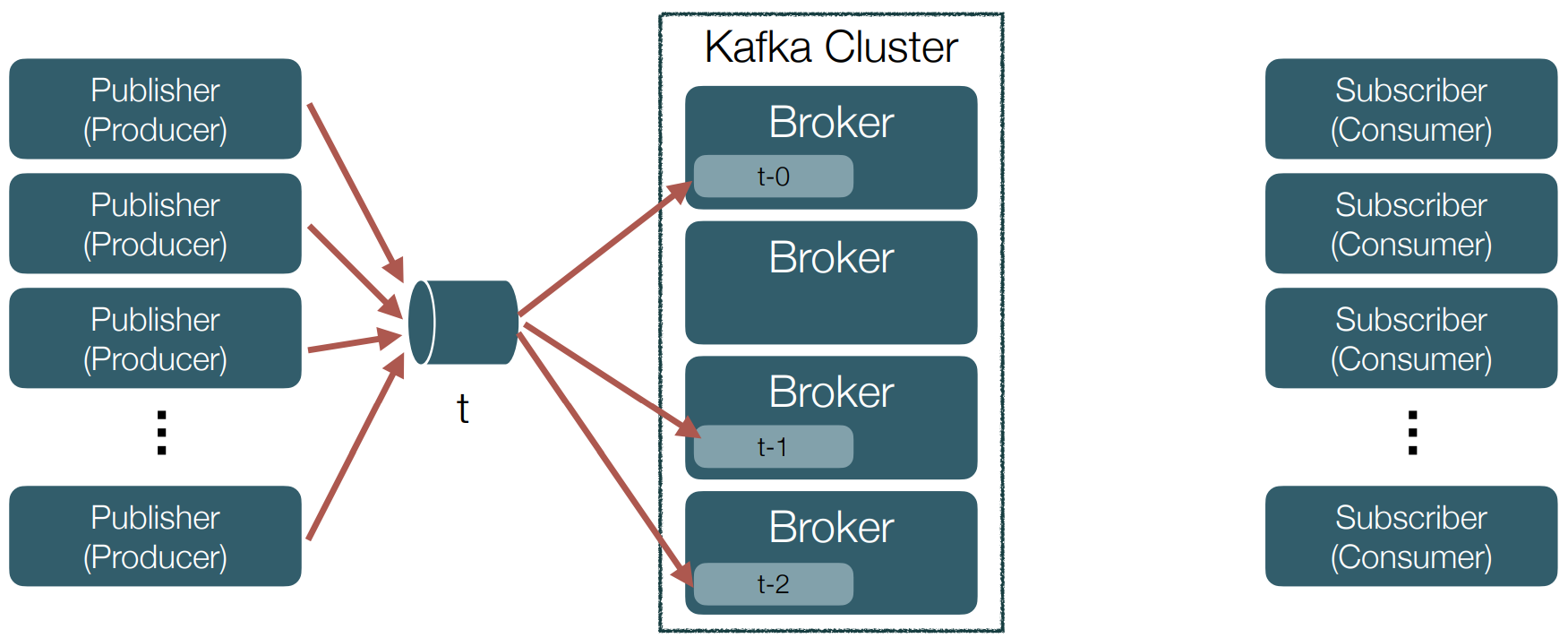
Topics : 이벤트 스트림은 카프카에서는 토픽이란 이름으로 저장된다. 카프카의 세계에서는 토픽이 구체화된 이벤트 스트림을 뜻한다. 토픽은 연관된 이벤트들을 묶어 저장하는데, 이는 데이터베이스의 테이블이나 파일 시스템의 폴더들에 비유할 수 있다.
토픽은 카프카에서 Producer와 Consumer를 분리하는 중요한 컨셉이다. Producer는 카프카의 토픽에 메시지를 저장(Push) 하고 Consumer는 저장된 메시지를 읽어(Pull)온다. 하나의 토픽에 여러 Producer / Consumer가 존재할 수 있다.
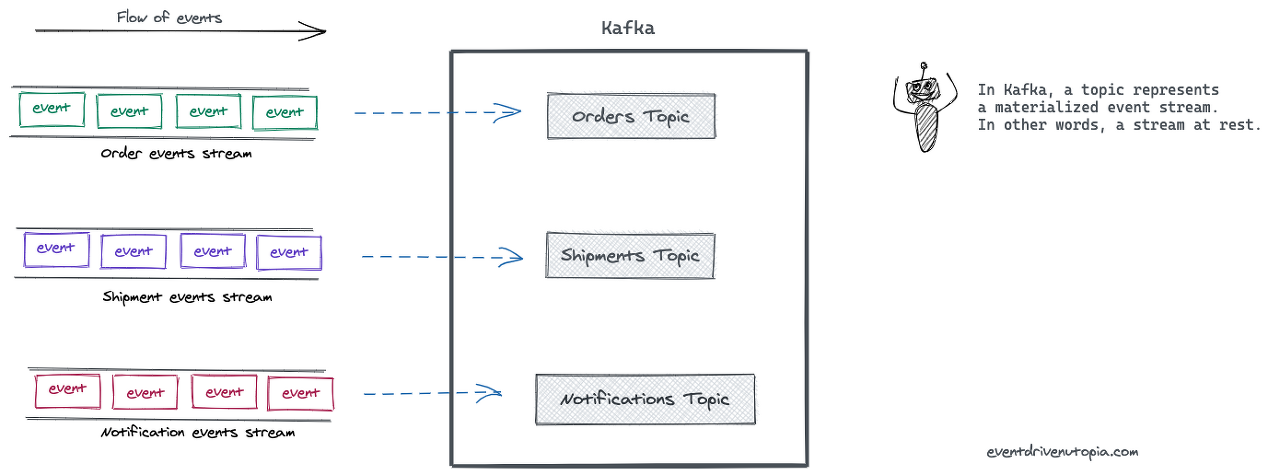
위의 개념들은 이 그림으로 설명이 가능하다. Event가 관련된 것들끼리 모여 Stream을 이루게 되고, 이것이 카프카에 저장될 때 Topic의 이름으로 저장된다.
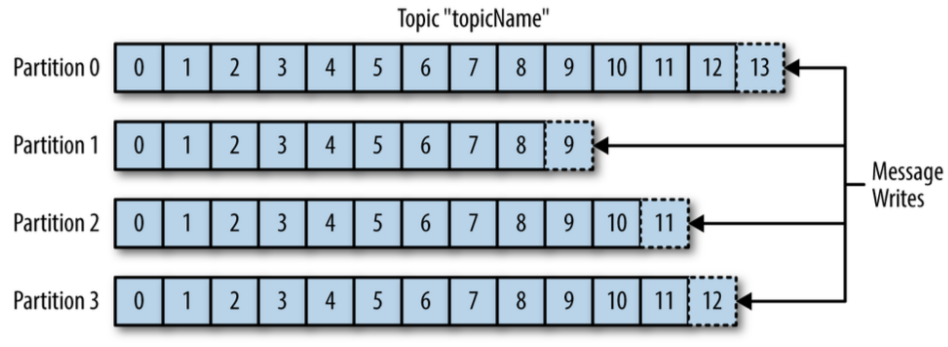
• topicName 이라는 토픽, partition = 4인 경우
• 파티션은 각각 브로커에 할당된다.
• 메시지가 log라는 컨셉으로 계속 append되는 구조
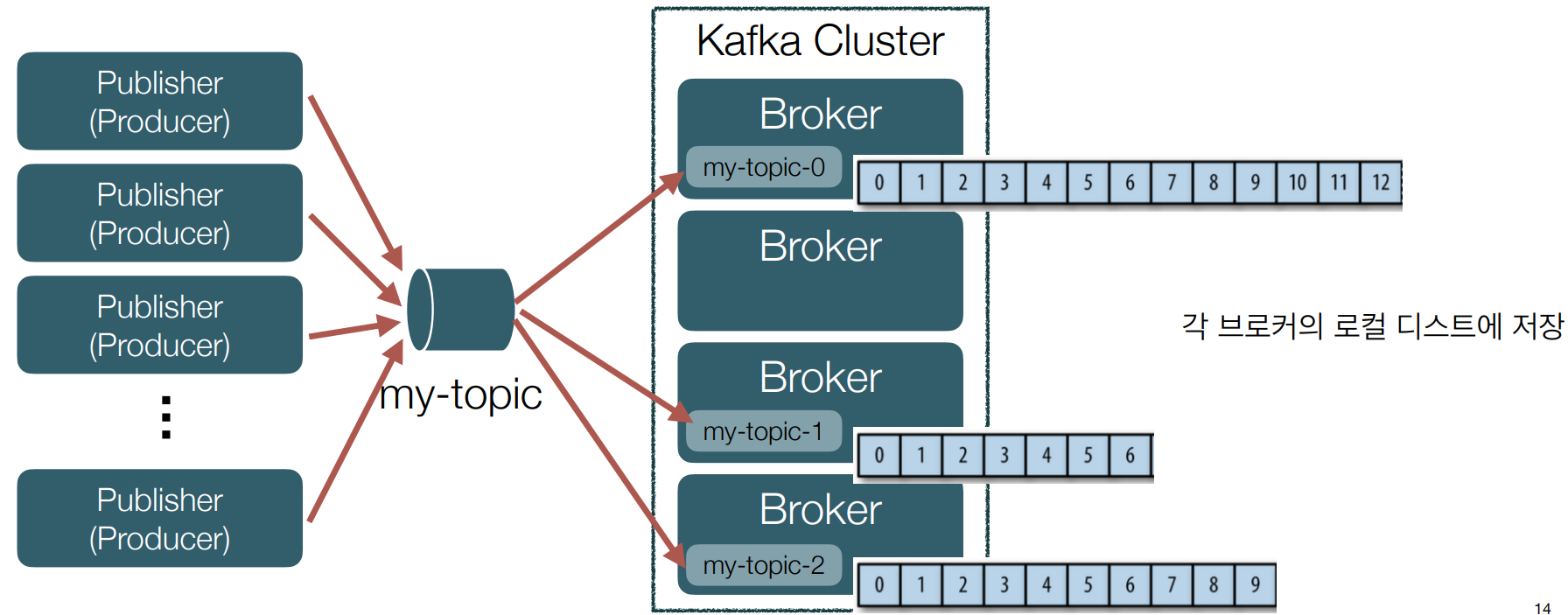
• ‘my-topic’ 이라는 토픽을 생성하고 partition을 3개로 설정했을 경우
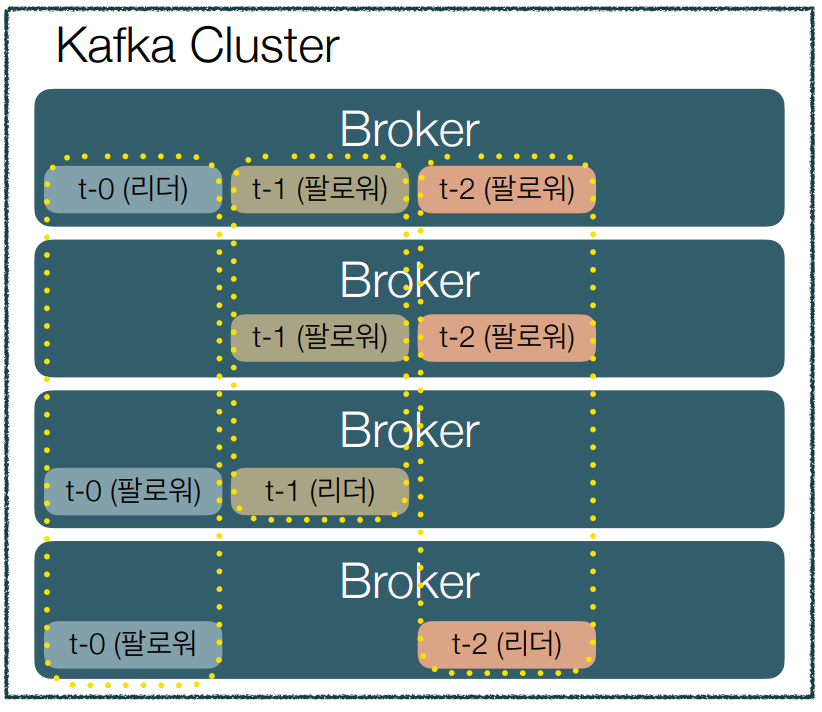
주요 구성 요소 - Replication
• Fault-tolerance 때문에 메시지를 replication-factor만큼 복제해서 브로커들에 분산시키는 작업
• 파티션 단위로 복제
• 일부 브로커가 불능 상태여도 전체 클러스터는 정상 동작한다.
• 안전할수록 좋지만 언제나 오버헤드가 존재하기 때문에 토픽의 특성이나 리소스 사용량 등을 고려해서 replication-factor를 정해야 한다.
• Replication을 위해 파티션별로 리더(leader)와 팔로워(follower) 역할이 할당
• 이 리더와 팔로워를 ISR(In-Sync Replica)이라고 하는 그룹으로 묶는다.
• 이 ISR 그룹 내에 속한 팔로워들은 조건만 맞다면 언제든지 리더가 될 수 있다.
• 파티션의 리더는 팔로워들이 offset을 잘 따라오고 있는지 모니터링하고 그렇지 못한 팔로워가 있으면 ISR에서 추방한다.
• 파티션의 팔로워는 리더가 가진 데이터와 자신의 것을 일치시키기 위해 지속적으로 리더로부터 데이터를 pull한다.
• 리더가 불능 상태가 되면 ISR 그룹 내의 팔로워 중 하나를 리더로 선출한다.
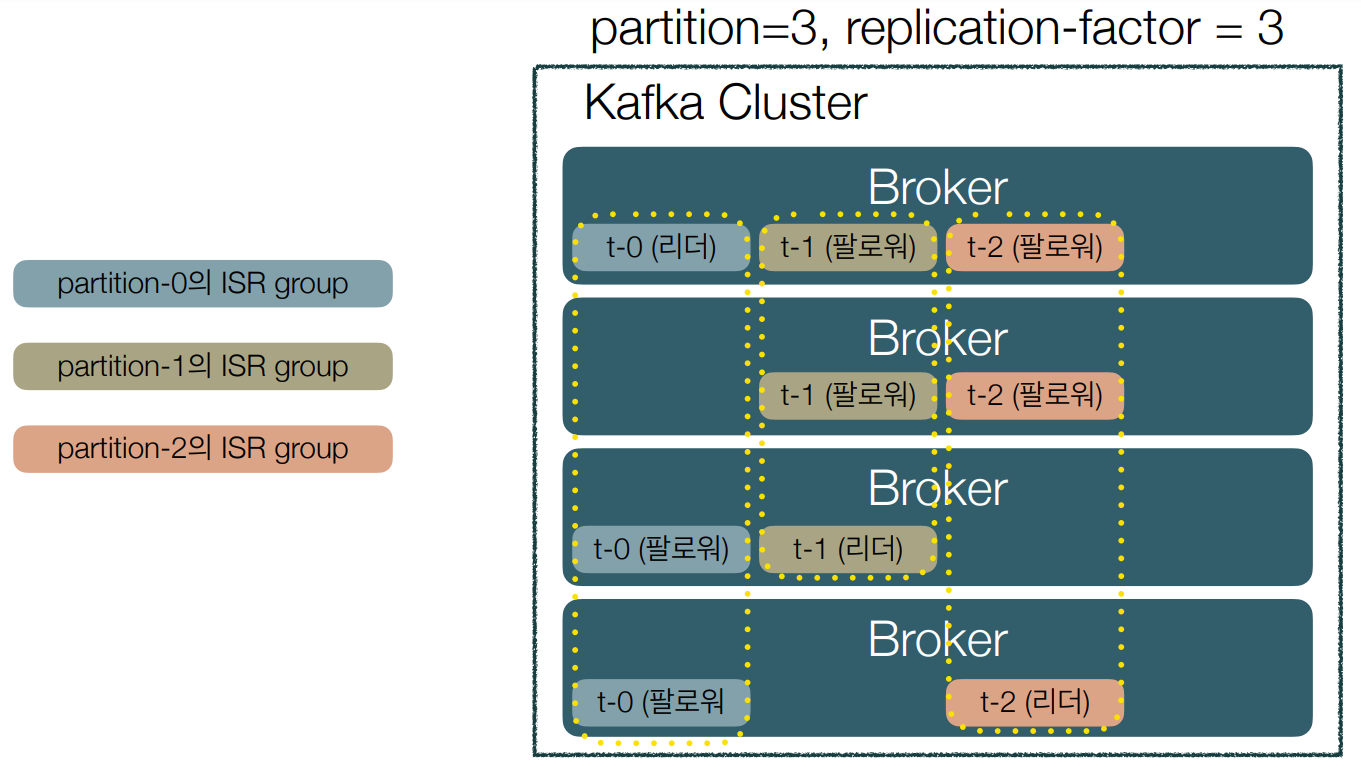
• 하나의 파티션은 replication-factor만큼 복제되어 분산되어 있다.
주요 구성 요소 - Consumer group
• Consumer는 특정 consumer group에 속한다.
(메시지를 가져오는 agent들의 집합)
• 각 consumer들은 토픽의 파티션에 1:1 맵핑되어 메시지를 pulling한다.
• Consumer group는 group-id를 가지고 있고 이를 통해 offset 등을 구분한다.
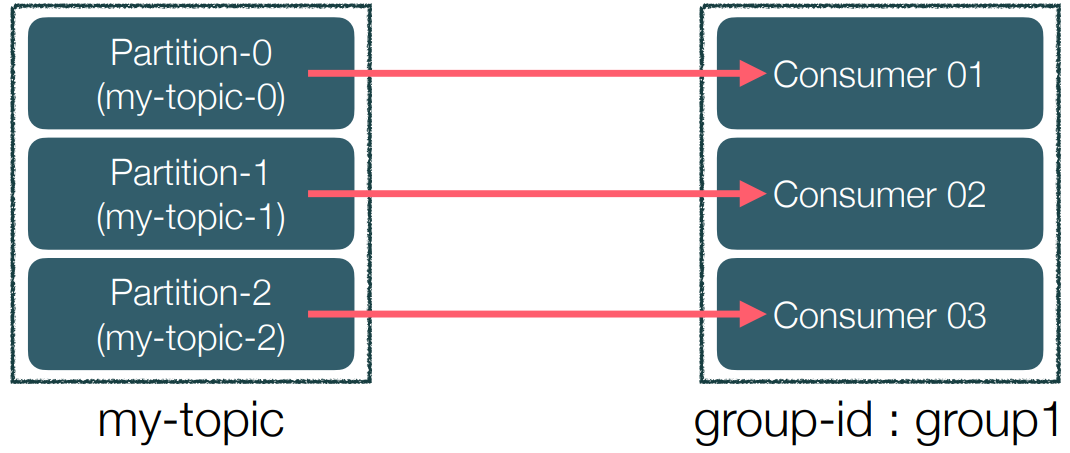
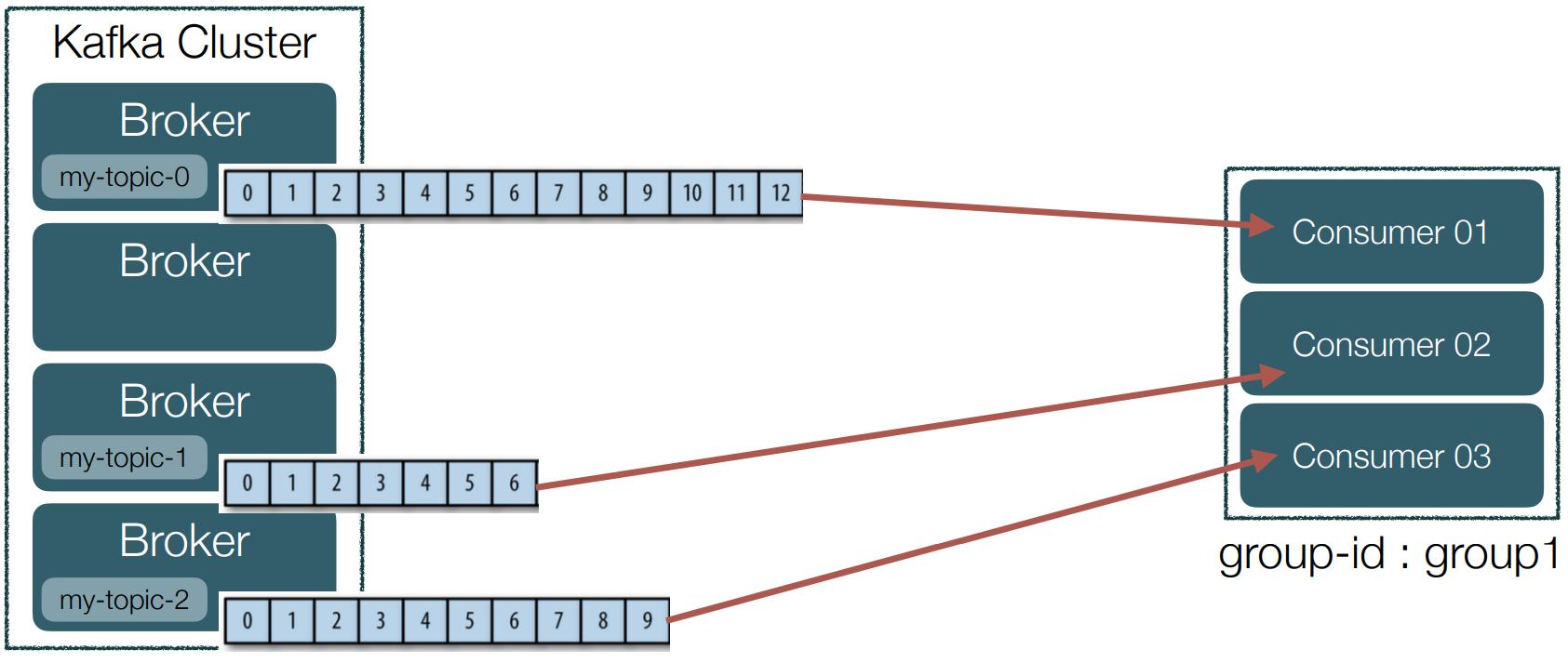
• 각 consumer는 메시지를 가져오고 그 메시지에 해당하는 offset를 commit한다.
• 메시지를 어디까지 가져왔는지 Broker에 표시하는 용도이다.
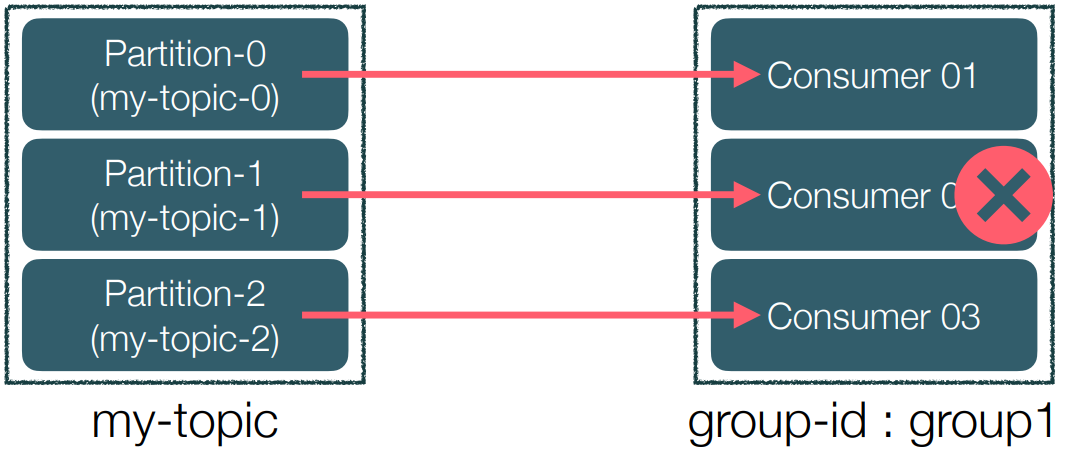
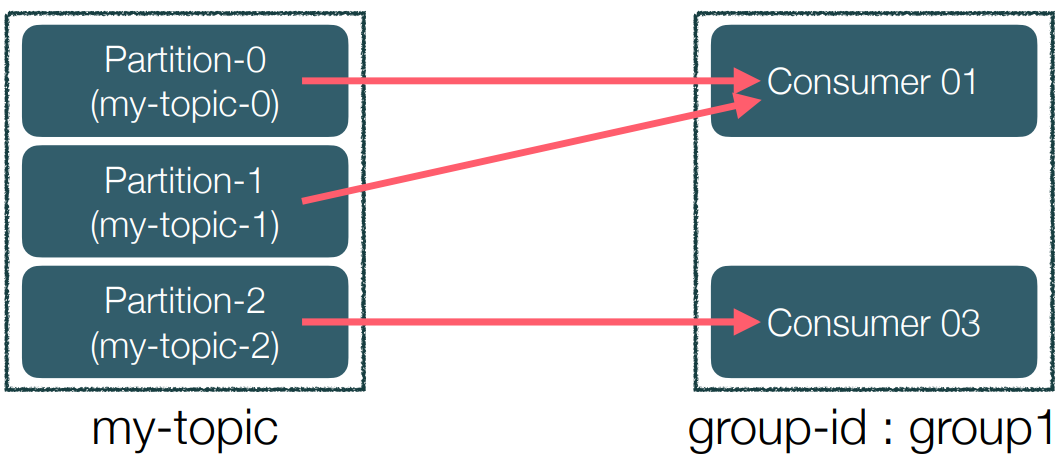
• Consumer 장애 상황 시 구동 방식
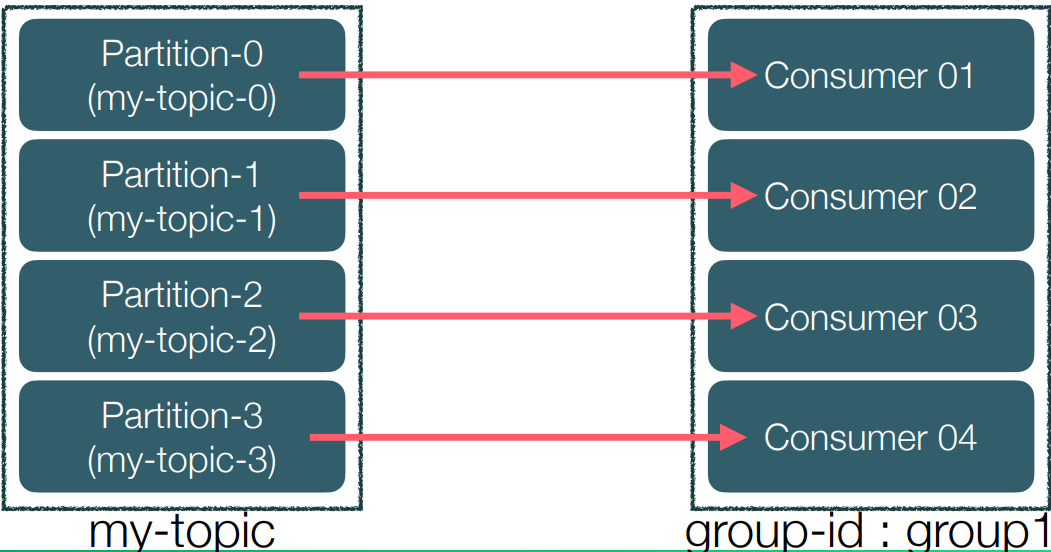
• Scale-out일 경우 파티션 추가 & 컨슈머 추가
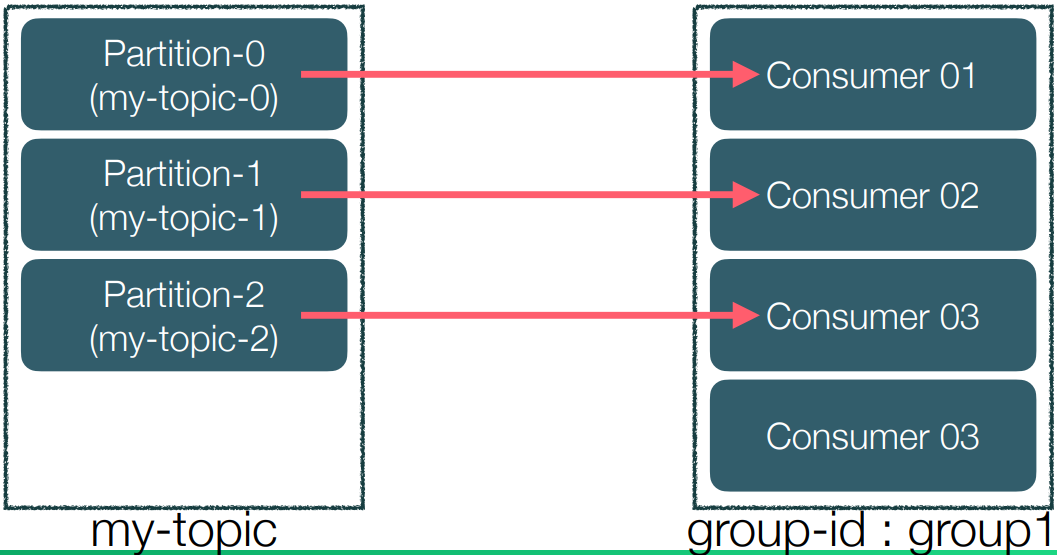
• Consumer가 더 많은 경우 유휴 자원이 된다.
주요 구성 요소 - Producer
• Kafka broker에 메시지를 send/publish/produce하는 인스턴스
• acks 옵션 [0, 1, -1(all)]
- acks = 0 : 안정성 낮음, 속도 빠름
프로듀서가 리더 파티션에 메시지를 전송하고 나서 리더 파티션으로부터
acks(확인)을 안하는 방식, 전송하고 끝! 재전송이나 offset는 신경쓰지 않음.
데이터 유실이 있더라도 빠른 전송 속도가 필요할 때 사용 - acks = 1 : 안정성 보통, 속도 보통
프로듀서는 리더 파티션에 메시지를 전송하고 리더로부터 ack를 기다린다.
하지만 팔로워들에게까지 잘 전송됐는지에 대해서는 신경쓰지 않음.
리더에게 ack를 받았지만 팔로워에게 복제하는 중 리더가 죽으면 fail 발생 - acks = 2 : 안정송 높음, 속도 느림
프로듀서가 전송한 메시지가 리더와 팔로워 모두 잘 저장됐는지 확인하기 때
문에 느릴 순 있지만 안정적이다. ISR에 포함된 모든 파티션에 전달됐는지를 확인하는 것이 아닌 min.insync.replicas에 지정된 갯수만큼 확인한다.
case-1
min.insync.replicas=1 (리더 파티션만 확인)
case-2
min.insync.replicas=2 (리더 파티션 1개와 팔로워 파티션 1개)
case-3
min.insync.replicas=3 (리더 파티션 1개와 팔로워 파티션 2개)
Amazon MSK (Managed Streaming for Kafka)
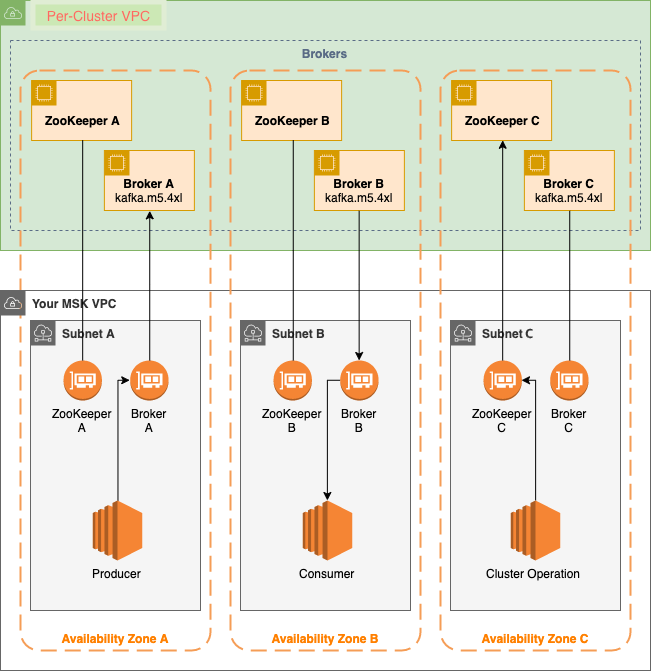
• Amazon Managed Streaming for Apache Kafka (Amazon MSK)는 카프카의 완전관리형 서비스 버전이다.
• ZK 별도 설치 없이 손쉽게 Kafka cluster 관리 & Connector 연동 가능
Amazon Kinesis
Amazon Kinesis는 실시간으로 비디오 및 데이터 스트림을 손쉽게 수집, 처리 및 분석할 수 있는 완전관리형 서비스다.
• 높은 확장성, 다양한 기능
• Data Stream: 데이터 스트림을 캡쳐, 처리 및 저장
• Data Firehose: 데이터 스트림을 AWS 데이터 스토어로 저장
• Data Analytics: SQL 또는 Apache Flink로 데이터 스트림 분석
• Video Streams: 비디오 스트림을 캡쳐, 처리 및 저장
Kinesis Data Streams
![]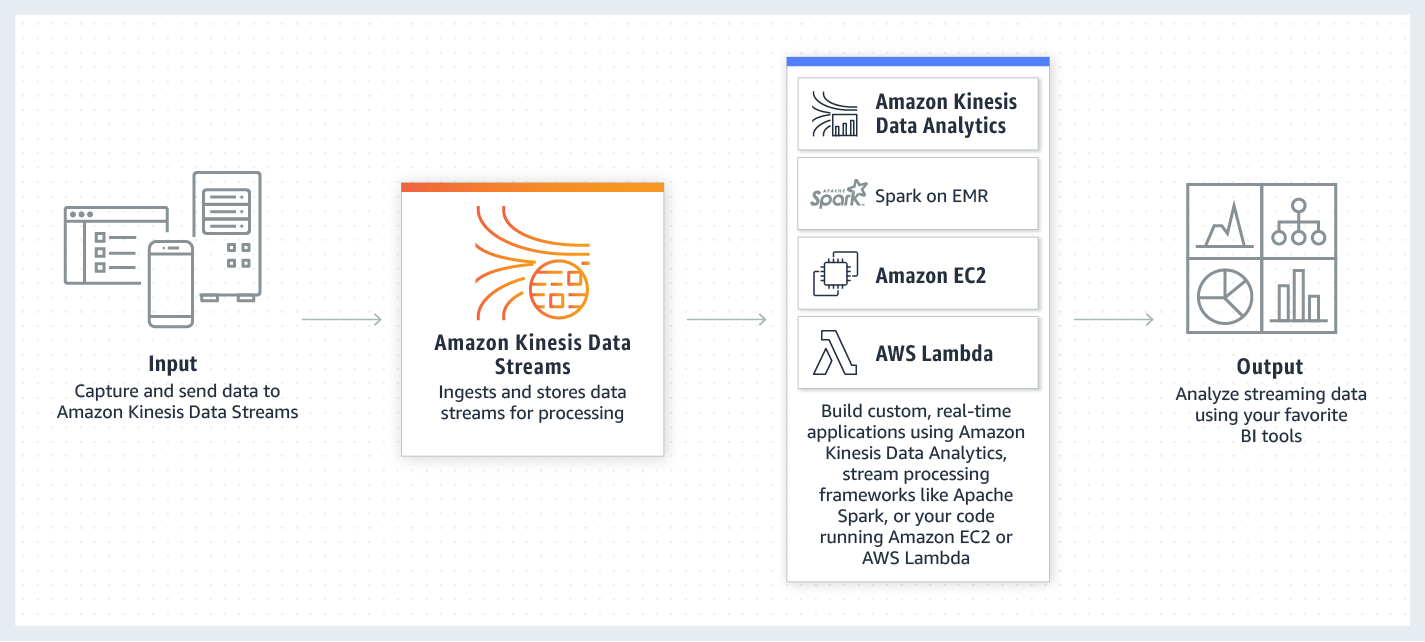
• 카프카 대체 서비스
• 저지연 스트리밍을 위한 서비스(주로 ingest 용도)
• EC2, Client, Agent, 사용자 개발 코드 등에서 생산된 데이터를 받아주고, 이를 다른 서비스에서 소비할 수 있게 해준다.
• Kafka의 Partition 같은 것이 Kinesis의 shard이다.
• Data retention : 24hour ~ 365day
• Kafka와 달리 reshard가 가능하다(split & merge)
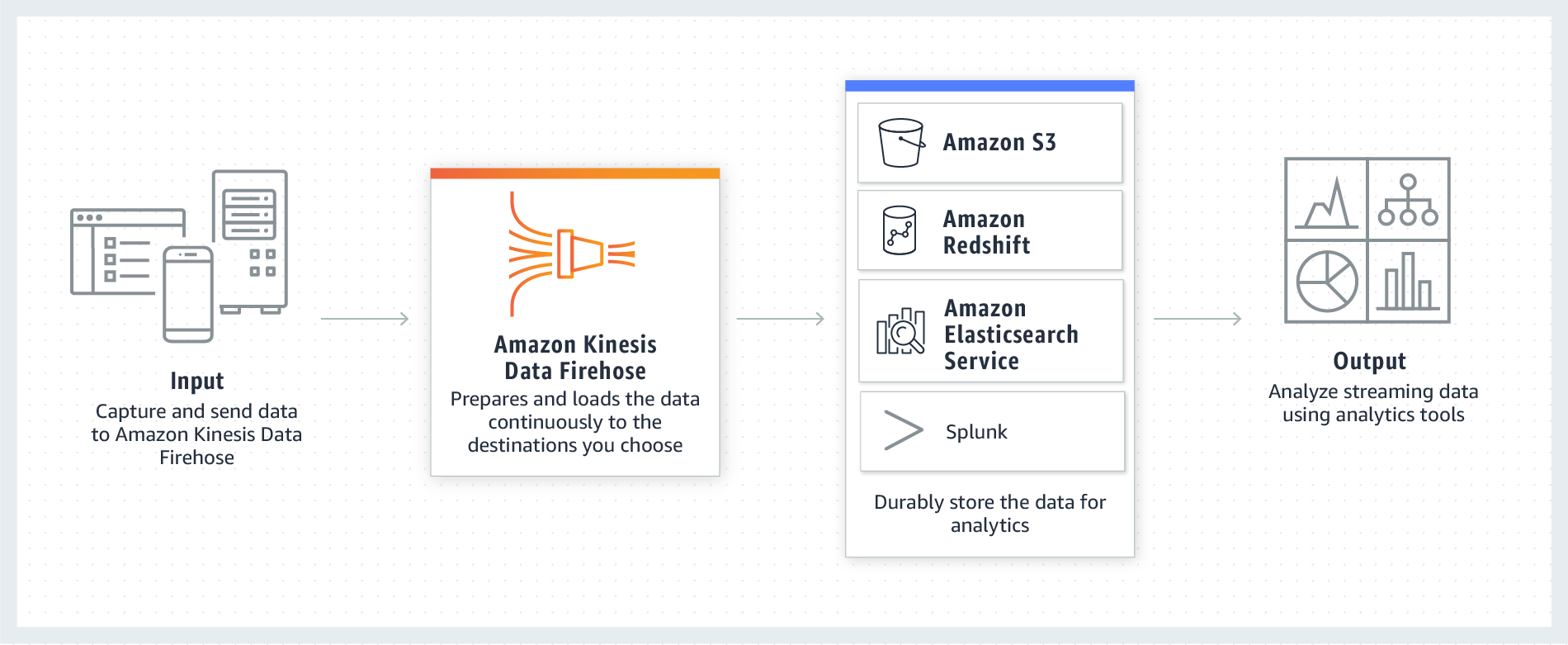
Kinesis Data Firehose
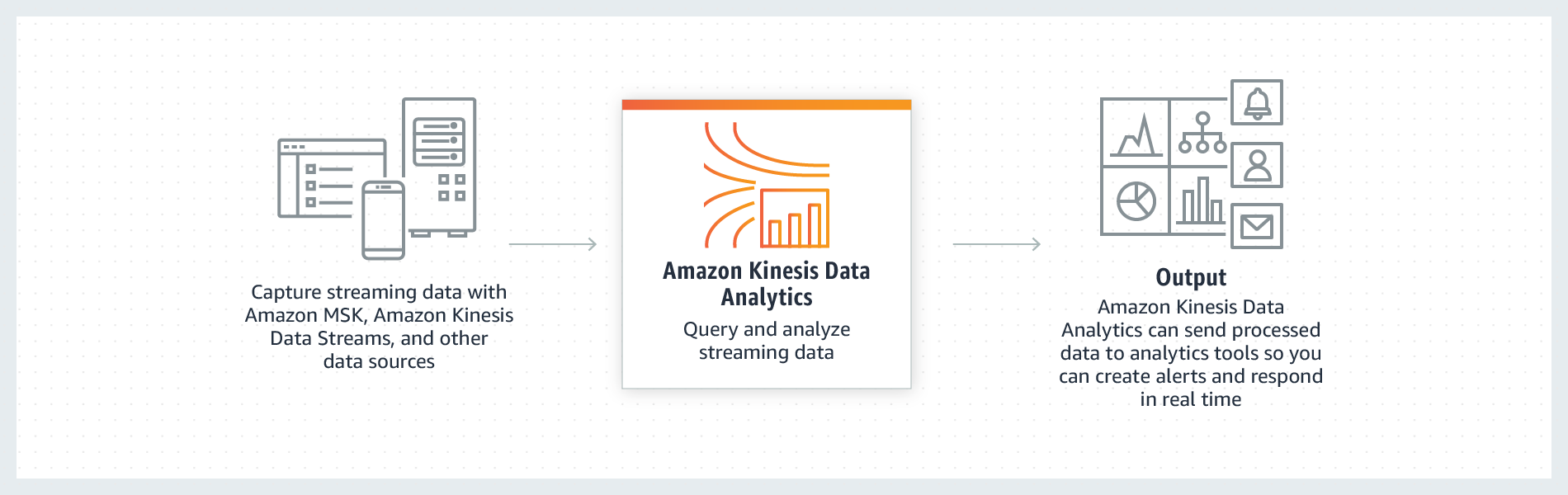
Kinesis Data Analytics
NETFLIX 사례

• Amazon Kinesis Data Streams는 매일 테라바이트급의 로그 데이터를 처리하고 있지만, 분석 기능에 이벤트를 표시하는 데는 몇 초밖에 걸리지 않는다. 문제를 실시간으로 발견해 대응할 수 있어서 고가용성은 물론 우수한 고객 경험까지 보장된다.
• 보통 약 1,000개의 Amazon Kinesis 샤드가 병렬로 작동하여 데이터 스트림을 처리한다.
