Term
용어 정리를 한번 더 해보자.
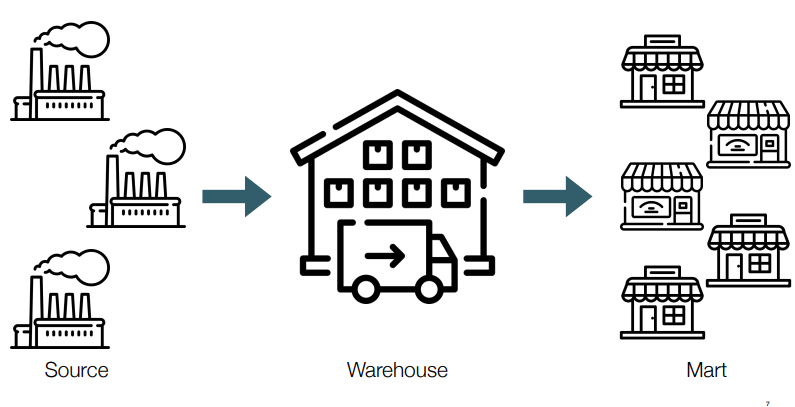
Data Warehouse
• 의사 결정을 위해 다양한 source의 데이터를 분석 가능하고 구조화된 형식으로
저장하는 저장소
• 다양한 source에서 필요한 데이터를 수정, 정제, 가공, 집계해서 저장하는 곳(데이터 레이크와 차이점)
for analysis & reporting
• 구조화된 데이터, 정형 데이터를 담는 repository
• 대량의 데이터를 장기 보관
• ETL 작업을 통해 여러 source로부터 가져온 데이터를 테이블화
• 배치 작업에 의한 대량 쓰기
• 주로 columnar
Data Mart
• DW가 중앙 집중식으로 여러 분야의 데이터를 담고 있다면, 데이터 마트는 특정 분야의 데이터를 정제, 집계해서 따로 담고 있는 repository
• 소수의 source 또는 DW로부터 ETL 프로세싱하여 구성
• DW보다 최종 사용자에 가까운 데이터 스토어
• 용도에 따라 나누어 놓고 OLAP 작업을 통해 BI(Business Intelligence)를 실현
• 최종 사용자가 필요로 하는 속성을 갖고 있는 작은 데이터의 집합
Data Lake
• DW와 달리 정형, 비정형 데이터를 모두 저장하는 repository
• 일단 저장하고 필요할 때 꺼내서 쓴다는 마인드
: 정의된 목적이 없는, 정형화나 정규화를 하지 않고 원시 데이터를 그대로 저장
• DB 보단 대용량 분산 스토리지(S3, HDFS, etc)
• not table / no schema / schema on read
• ELT(Extract-Load-Transform)의 중간 저장소 역할
OLAP
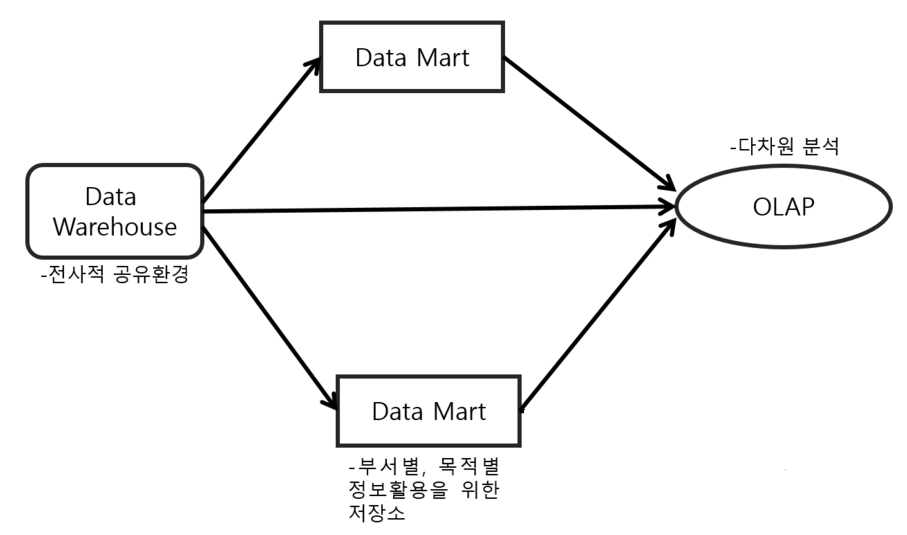
• 사용자가 대화형 쿼리를 통해 다차원 데이터 분석을 하고 이를 의사결정에 참고하는 과정 또는 그러한 과정에 사용하는 데이터베이스 엔진
• 주로 읽기 관련 워크로드
• 분석을 위해 따로 만들어진 다수의 다차원 데이터(OLAP cube)를 aggregate & query
• columnar, column-oriented DB
Row-oriented / Column-oriented DB
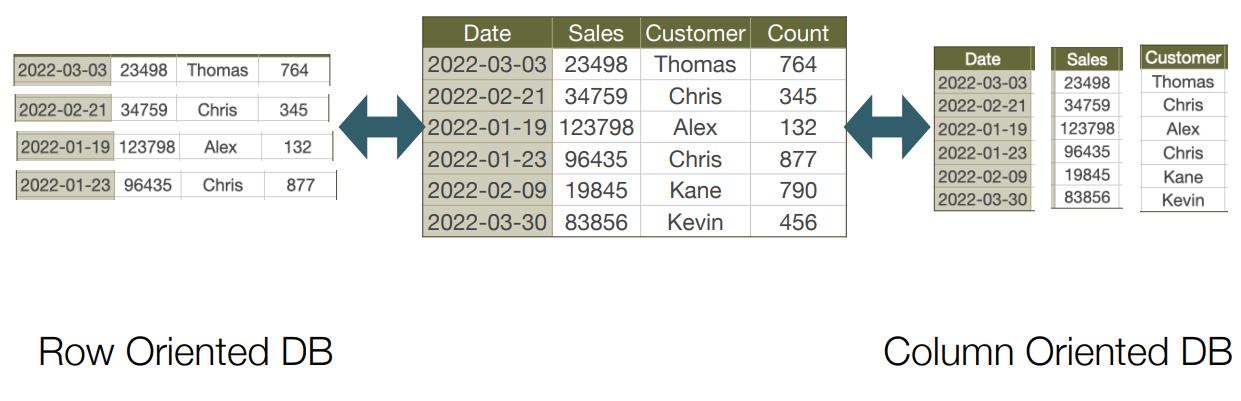
Row-oriented
• 일반적인 RDB(관계형 데이터베이스)
• 행별로 데이터를 관리하고 조회
• 특정 row 검색, 삭제, 업데이트, 추가 효율적
• 트랜잭션 처리
• 적은 양의 데이터를 자주 읽고 쓴다.
Column-oriented
• 열별로 데이터를 저장
• Delete/Update가 비효율적이거나 불가능
• 특정 칼럼의 데이터만 가져오거나 대량의 데이터에 대한 쿼리, 같은 자료형의 데이터가 모여있다.
• 많은 양의 데이터를 종종 읽고 쓴다.
Batch processing
• 일괄 처리
• 데이터를 일정 기간동안 수집하고 나서 하나의 슬롯으로 처리하는 것
• Bounded data processing
• For large volumes of data
• 연산량이 많은 CPU 집약적인 작업(ex: ML/DL)
• 중요도 : latency < throughput
배치 처리시 주의해야 할 점
• 불규칙한 데이터 사이즈
: 배치 처리의 컴퓨팅 리소스와 배치 작업 주기를 산정하기 어렵게 만든다.
• 연산/처리 속도와 배치 주기
: 컴퓨팅 리소스 산정 / 비즈니스 및 DS의 요구사항 고려
• 재처리 방식
: 재처리용 리소스를 따로 할당 or 기존의 리소스를 나눠서 사용
(기존 작업엔 영향이 없는지)
• 태스크 스케줄링(워크플로 스케줄링)
: 배치 작업을 정해진 시간에 실행하고 그 상태/결과를 모니터링할 수 있어야 한다.
(A 태스크가 끝나면 B태스크를 수행한다. A태스크가 실패할 경우 C태스크를 실행한다)
ETL
• Extract-Transform-Load
• 비즈니스 데이터를 활용 가능한 형태로 추출(E), 변환(T), 저장(L)하여 이후 활용할 수 있도록 하는 작업, 또는 그러한 데이터 파이프라인
• 주로 OLTP(OnLine Transaction Processing) DB를 source로 하는 ETL 파이프라인을 만들고 Data warehouse와 Data mart로 저장
• Transform(=filter, sort, aggregate, join, dedup, validate, missing value, etc)
• 주로 일괄 처리 방식, 주로 정형 데이터
ETL의 단점
• 추출을 해야 하는 데이터 스토어가 백엔드 개발자 또는 데이터 엔지니어의 영역
=> 데이터 엔지니어 의존적
=> 데이터 사이언티스트 또는 BI 담당자가 원하는 데이터를 얻기 어려움
• DE가 ETL 작업을 해줘야 원하는 데이터 셋을 얻을 수 있다. (민첩성 결여)
• 비정제, 비정형 데이터를 담아서 활용할 저장소가 마땅하지 않았음
• 기존 DB 구조에서 크게 벗어나지 못함
• 스키마 종속적이고 제한적인 데이터 타입
• 쿼리 등의 성능 때문에 DB 모델링이 중요
ETL에서 ELT로의 변화
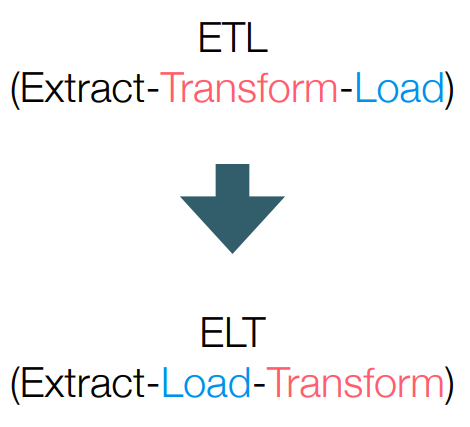
• 데이터 니즈의 다양성
• “원하는 데이터를 추려서 저장”
=> “무슨 데이터가 필요한지 모르니까 일단 다 저장!”
• 데이터 통합
• 데이터 소스의 다양화(비정형 데이터를 포함한 다양한 원시 데이터)
• computing resource / storage resource의 발전
• 쉽고 저렴하게 담아서 원하는 시점에, 원하는 형식으로 꺼내서 사용한다!
• Data lake의 발전
ELT
• 다양한 데이터 소스로부터 원시 데이터를 가져와서 데이터 레이크에 저장
• DW와 달리, 구조화된 데이터 모델이 불필요
• 데이터를 자주 그리고 다양하게 뽑아서 사용하겠다!
• 데이터의 목적지에서 원하는대로 변환해서 사용하겠다!
• 데이터 과학자와 분석가가 편하게 원하는 데이터를, 원하는 방식으로 변환, 모델링, 쿼리할 수 있도록 하자.
ETL은 이제 사용 안하나?
NOPE
• 개인정보, 보안, 암호화 등의 요구사항에선 ETL 방식이 필요
• 데이터의 Outpost(전초기지)가 필요할 땐 ETL로 데이터를 뽑아서 DW, DM 구축
• 뭐 하나가 좋다고 완전히 사라지지 않을 것으로 예상
• 시스템 및 비즈니스 요구사항에 맞춰서 구축하는 것이 현명하고
비용도 고려해야 함
2주차 - Batch processing
Logstash
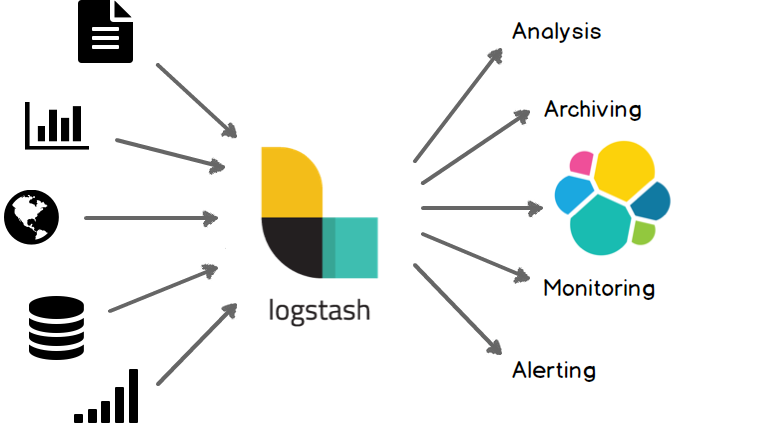
Logstash는 입력(input)을 포함한 다양한 소스로부터 데이터를 수집하고 가공(filter)하여 실시간으로 원하는 대상에 데이터를 전송(output)하는 경량의 오픈소스 데이터처리 파이프라인이다. 원래는 데이터를 수집하는 역할도 했지만 점차 확대되어 파이프라인 툴로 자리를 잡고 있다.
오픈소스 분석 및 검색 엔진인 Elasticsearch의 데이터 파이프라인으로 자주 사용된다.
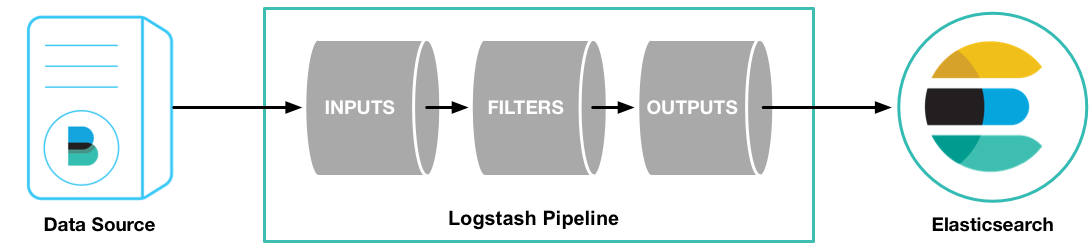
Logstash는 세 부분으로 이루어져 있는데 Input과 Output은 필수적인 요소이고, Filter는 상황에 따라 사용하면 된다.
다양한 input, filter, output plugin 지원
• 플러그인을 통해 원하는 방식으로 parsing 가능
• 데이터 수집 & 전달 (데이터 파이프라인 역할)
• 경량 수집기로부터 전달받은 데이터를 aggregation 하는 역할
Beats

Logstash가 데이터 수집기로서의 역할을 잘 수행하고 있지만, 너무나 다양한 기능을 가지고 있고 많은 곳에서 데이터를 수집하고 있기 때문에 점차 부피가 커져 프로그램이 무거워지는 문제가 생겼다. 이런 문제를 해결하기 위해 Logstash에 비해 경량화 된 데이터 수집기를 개발을 했는데 그래서 등장한 프로그램이 Beats다.
Beats는 단일 목적의 데이터 수집기 무료 오픈 소스 플랫폼이다.
Beats는 Logstash에 비해 갖고 있는 기능이 적지만, Resource를 적게 소모한다는 장점이 있다.
Logstash + Beats
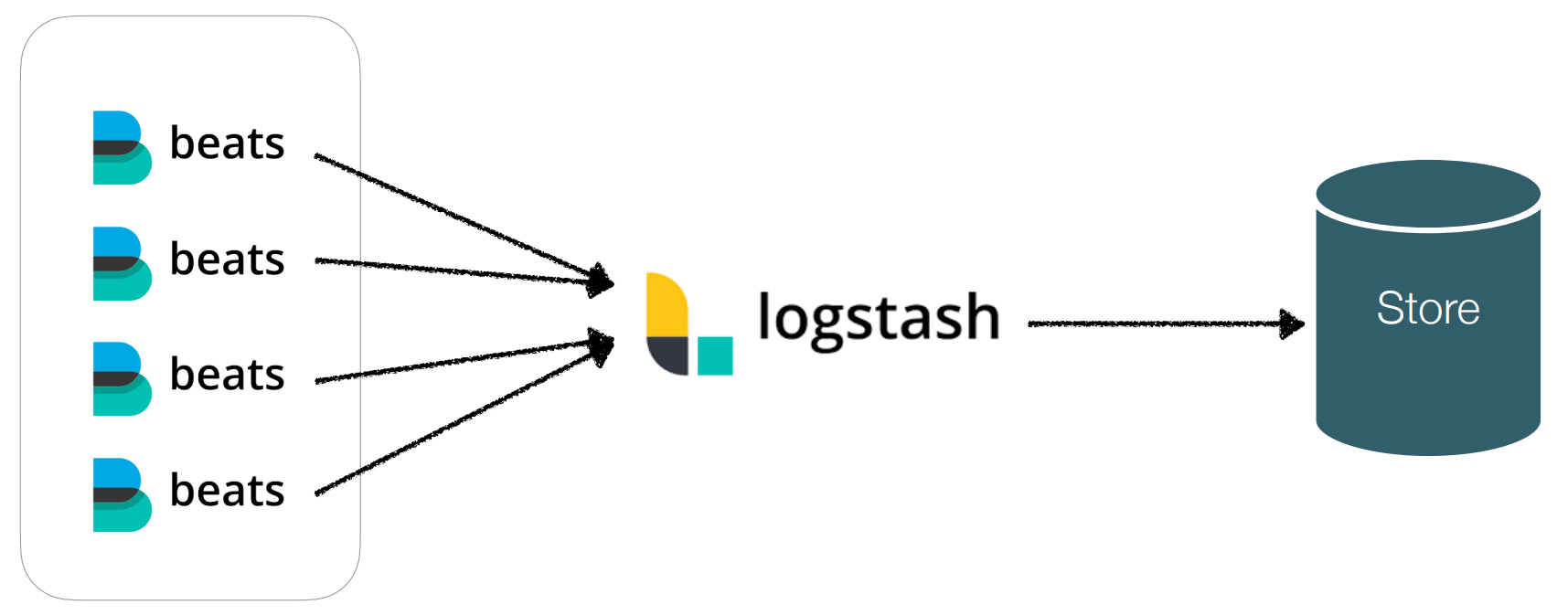
Logstash와 Beats를 결합하면 Beats가 데이터 수집기의 역할을 하고, Logstash는 데이터 파이프라인의 역할을 한다.
결합 예시 :
file - logstash - elasticsearch file - logstash - kafka
kafka - logstash - elasticsearch
kafka - logstash - hadoop
AWS
AWS(Amazon Web Services)는 전 세계적으로 분포한 데이터 센터에서
다양한 서비스를 제공해 널리 채택되고 있는 클라우드 플랫폼이다.
Amazon S3

S3란 Simple Storage Service의 약자로 파일 서버의 역할을 하는 서비스다. 일반적인 파일서버는 트래픽이 증가함에 따라서 장비를 증설하는 작업을 해야 하는데 S3가 이와 같은 것을 대행하므로 트래픽에 따른 시스템적인 문제는 걱정할 필요가 없어진다.
• 객체 - object, AWS는 S3에 저장된 데이터 하나 하나를 객체라고 명명하는데, 하나 하나의 파일이라고 생각하면 된다.
• 버킷 - bucket, 객체가 파일이라면 버킷은 연관된 객체들을 그룹핑한 최상위 디렉토리 혹은 컨테이너라고 할 수 있다. 버킷 단위로 지역(region)을 지정 할 수 있고, 또 버킷에 포함된 모든 객체에 대해서 일괄적으로 인증과 접속 제한을 걸 수 있다. globally unique name
• Cloud storage 중 하나인 object storage (block storage, file storage)
• 정형/비정형 데이터를 모두 저장할 수 있는 Data lake역할
• 수많은 서비스와 쉽게 연동할 수 있다.
• 다양한 스토리지 클래스, 관리 기능, 로깅 및 모니터링, 보안, 규정 준수, 감사
• 무한대의 확장성
• 99.999999999% 데이터 내구성(eleven nine)
• 데이터 보관 정책, 버저닝 등을 통해 데이터 거버넌스에 큰 도움을 준다
• 최종 저장소이자 중간 스테이징 저장소, 파일 캐싱, 코드 저장소 등 무수한 쓰임새
• AWS의 수많은 서비스를 엮어주는 허브 역할
Amazon Athena
Amazon Athena는 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있는 서버리스 대화식 쿼리 서비스다.
서버리스란 서버가 없는 것이 아니라 개발자가 서버의 존재를 신경쓸 필요가 없고 코드에만 집중하면 된다는 뜻이다.
• 복잡한 ETL 작업 없이 데이터 분석이 가능(No DW)
• 실행한 쿼리에 대한 비용만 지불
• CTAS 쿼리 등으로 데이터 변환, 포맷 변환, 데이터 추출 등이 가능
• CSV, JSON, ORC, Avro, Parquet 등 다양한 표준 데이터 형식 호환
• Hive/Hue와 같이 대화형 쿼리 서비스
• 쿼리가 중간에 실패했다면 해당 비용은 청구되지 않는다.
• 서버리스 서비스이기 때문에 scale-out 등을 고려하지 않아도 된다.
AWS Lambda
Lambda는 AWS에서 제공하는 서버리스 컴퓨팅 플랫폼이다.
간단하게 람다를 사용하는 목적은 서버에 대한 걱정 없이 코드를 실행하고 사용한 컴퓨팅 시간, 용량에 대해서만 AWS에 비용을 지불하는 것이다.
• FaaS(Function as a Service), Serverless computing
• 인프라 프로비저닝이나 관리 없이 코드를 실행
• 코드는 브라우저 업로드, S3 불러오기 등이 가능
• 초당 수십만 개의 요청까지 처리 가능
• ms 단위로 사용하는 컴퓨팅 시간에 대해서만 비용을 지불
• Node.js, Python, Java, Ruby, C#, Go, PowerShell 언어 지원
• Stateless한 구조
• 무엇인가 함수를 호출(트리거링)하면 실행되는 구조(API GW, S3, SQS,
EventBridge 등)
Amazon EventBridge
Amazon EventBridge는 다양한 소스의 데이터와 애플리케이션을 연결하는 데 사용할 수 있는 서버리스 이벤트 버스 서비스다.
현재 사용하고 있는 aws 계정에서 발생하는 이벤트를 수신할 수 있고, 이벤트를 대상으로 라우팅 하는 규칙을 적용한다.
그리고 EventBridge에 오는 모든 이벤트는 이벤트 버스와 연결되는데, 여기서 이벤트 버스는 이벤트를 수신하는 파이프 라인 이라고 생각하면 편하다. 이벤트 버스와 연결된 규칙은 이벤트가 도착할 때 이벤트를 평가하고, 이벤트가 규칙과 일치하는지 확인한다.
• 서버리스 이벤트 버스
• 다양한 이벤트를 받아서 라우팅, 필터링, 트리거링할 수 있다.
• Event-Driven Architecture 구축을 편리하게 해준다.
• AWS 서비스에서 생성되는 다양한 이벤트를 가져올 수 있다.
• 특정 규칙을 지정하고 그 규칙에 부합하면 AWS의 다른 서비스를 호출할 수 있다.
• 우리는 일정 시간마다 AWS 서비스를 호출시켜주는 스케줄러로서 사용하고자 한다
• 더 엄격하고 세세한 스케줄러를 사용하고 싶으면 Airflow를 사용하면 된다.
