앞으로 수업에서 다룰 것
- 데이터 엔지니어링 개요
- 데이터 수집기(logstash, filebeat, fluentd)
- AWS (S3, Athena, Kinesis, Glue, Lambda, etc)
- Elasticsearch
- Kafka
- Apache Flink
데이터 엔지니어링이란?
데이터를 수집, 저장, 처리를 위한 시스템을 구축하고 운영하는 것을
데이터 엔지니어링이라고 한다. 또한 데이터 플랫폼과 데이터 파이프라인을 개발 및 운영하는 것도 데이터 엔지니어링이다. 한마디로 요약하면 “데이터를 수집하고 데이터 기반 의사결정을 위한 플랫폼을 개발 및 운영하는 것"
이렇게 수집한 데이터들을 분석하여 유의미한 결과를 도출하거나 인사이트를 제공하는 것은 데이터 분석가의 일이다. 하지만 이것은 회사의 상황이나 하는 일에 따라 다르다고 한다. 일반적으로는 데이터 엔지니어의 주 업무는 데이터 수집, 데이터 분석가의 주 업무는 데이터 분석이다.
V4
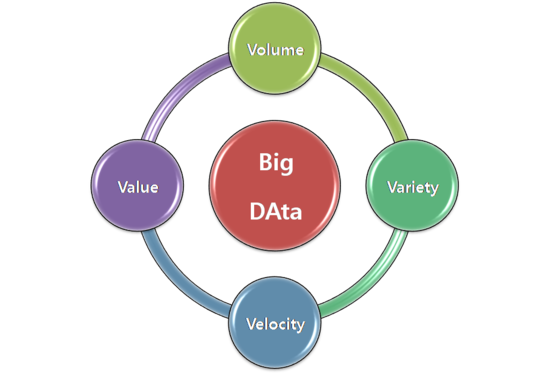
빅데이터 시대가 들어서면서 V4가 중요하게 여겨지고 있다.
Volume(용량) : 이전보다 데이터가 급격히 증가, 로우가 증가
Variety(다양성) : 이전보다 다양한 데이터(클릭로그,행동패턴 등등), 칼럼이 증가
ex) 사람이 버튼을 클릭하고 몇 초뒤에 또 다시 클릭 하는지 엄청 세세하게 분석
Velocity(속도) : 빠르게 처리하는 것이 중요
Veracity(정확성) : 데이터 엔지니어링이 고도화 되면서 정확히 인사이트를 얻어내는거(퀄리티)에 집중, 타겟팅이 잘못되면 돈낭비 큼
V4를 통해 데이터 엔지니어가 하는 일과 목표를 알 수 있다. 간단히 말하면 데이터 엔지니어는 빅테이터로부터 value를 얻어내는 사람들이고, 데이터를 통해 돈을 아끼고 더 버는 것이 데이터 엔지니어의 목표이다.
데이터 엔지니어 로드맵
https://github.com/datastacktv/data-engineer-roadmap
데이터 파이프라인
데이터 파이프라인은 배관이랑 비슷한데 실제로 배관공이랑 하는 일이 비슷해 관련 용어도 배관 쪽에서 가져온 것이 많다.
물 : 데이터
배관 : 데이터 파이프라인
배관공 : 데이터 엔지니어
일반적으로 순차적으로 전달/처리되는 데이터로 구성된 시스템을 데이터 파이프라인이라고 한다.
데이터 파이프라인은 (데이터 처리 단계의 출력)이 다음 단계의 입력으로 이어지는 구조이다.
또한 데이터 파이프라인은 어디에서 어떻게 데이터를 수집하여 무엇을 하고 싶은지에 따라 변화한다.
처음에는 간단한 구성으로도 구축할 수 있지만, 원하는 것에 따라 시스템이 점차 복잡해질 수 있고 그것을 어떻게 조합할지 문제가 된다.
Term
알 수 없는 많은 용어들이 있는데 더 깊게 들어가기 전에 간단하게 알아보자.
ETL, ELT
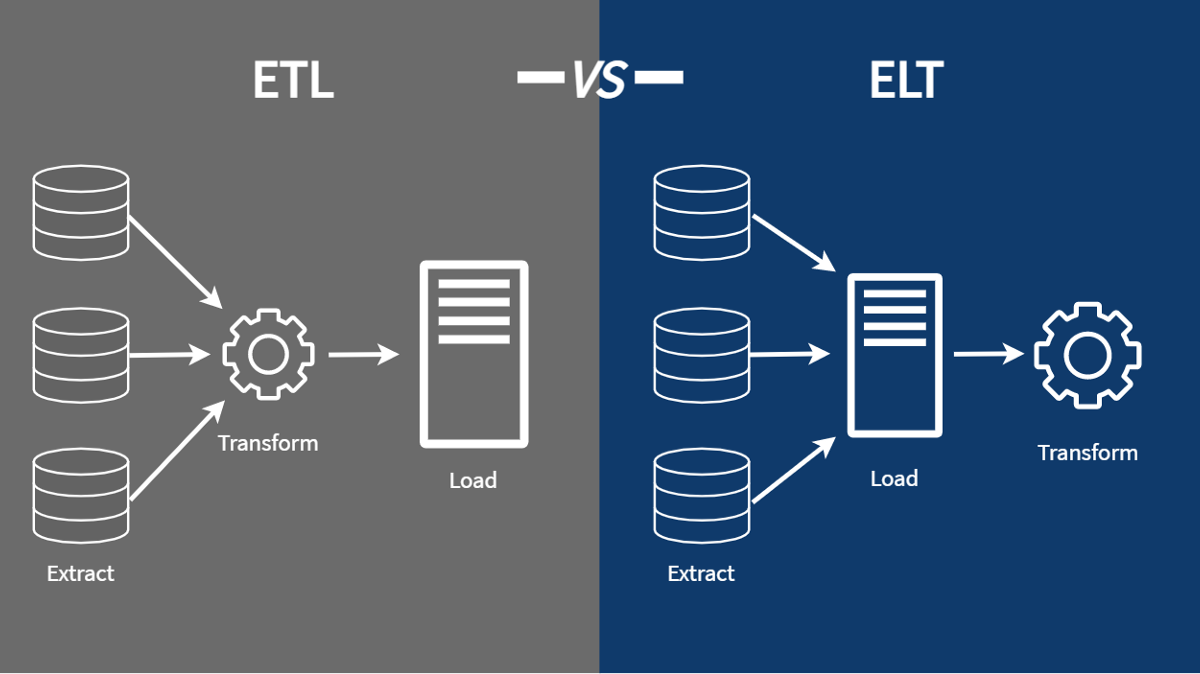
ETL(Extract-Transform-Load)은 데이터를 추출(Extract)하고, 가공(Transform)한 후, 저장소에 로드(Load)하는 데이터 파이프라인이다.
ELT((Extract-Load-Transform)은 데이터를 추출(Extract)한 후에, 저장(Load)한 후, 가공(Transform)하는 데이터 파이프라인이다.
데이터 웨어하우스, 데이터 마트
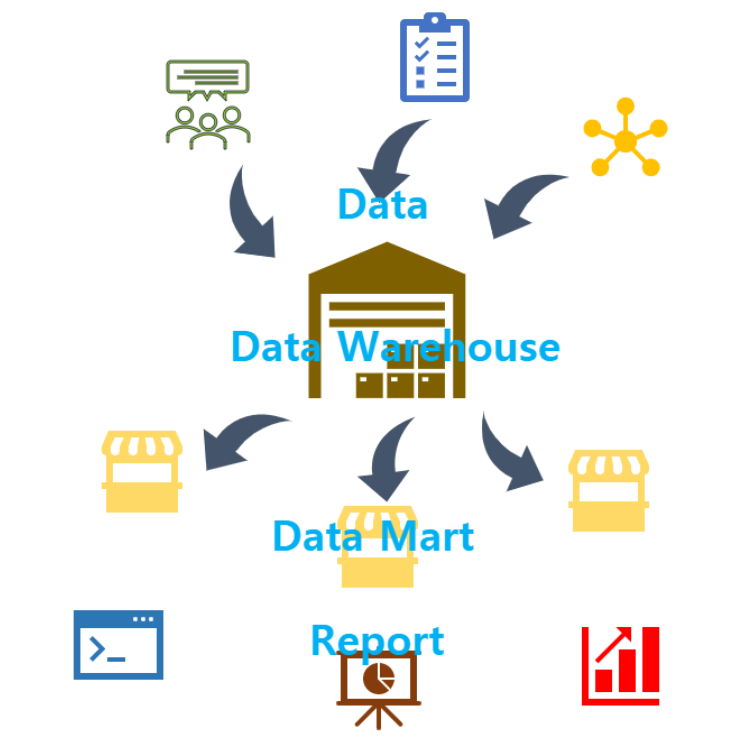
데이터 웨어하우스는 대량의 데이터를 장기보존하는 것에 최적화되어 있다.
따라서 정리된 데이터를 한 번에 전송하는 것은 뛰어나지만, 소량의 데이터를 자주 쓰고 읽는 데는 적합하지 않다.
업무에 필요한 RDB나 로그를 저장하는 파일 서버를 데이터 소스라고 부르고, 거기에 보존된 로우 데이터(원시 데이터)를 추출하고 가공한 후 데이터 웨어하우스에 저장하는 과정이 ETL프로세스다.
데이터 웨어하우스는 업무에 중요한 데이터 처리를 하는 곳이기 때문에, 자주 사용해 시스템 과부하를 일으키는 것은 안된다. 따라서 데이터 분석과 같은 목적으로 사용하는 경우 데이터 웨어하우스에서 필요한 데이터만을 추출하여 데이터 마트를 구축한다.
데이터 레이크
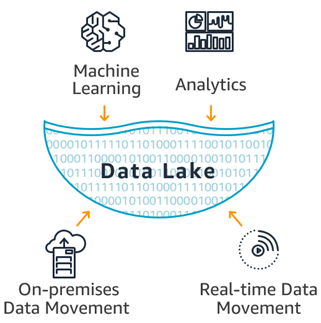
빅데이터 시대가 되면서 ETL 프로세스 자체가 복잡해졌다. 또한 모든 데이터가 데이터 웨어하우스를 고려하여 만들어지는 것이 아니기 때문에 데이터 웨어하우스에 맞지 않거나 적재할 수 없는 데이터가 있을 수 있다.
그렇다고 이러한 데이터를 그냥 버릴 것은 아니고 어딘가에 보관은 해놔야 한다. 이러한 보관 장소를 여러 곳에서 데이터가 흘러들어 오는 '데이터를 축적하는 호수'에 비유해 데이터 레이크라고 한다.
데이터 웨어하우스와 비교하자면 데이터 웨어하우스는 한번 가공한 데이터들이 저장되어 있는 공간이고, 데이터 레이크는 미가공의 원시 데이터를 그대로 저장하는 공간이라는 차이점이 있다.
OLAP, OLTP
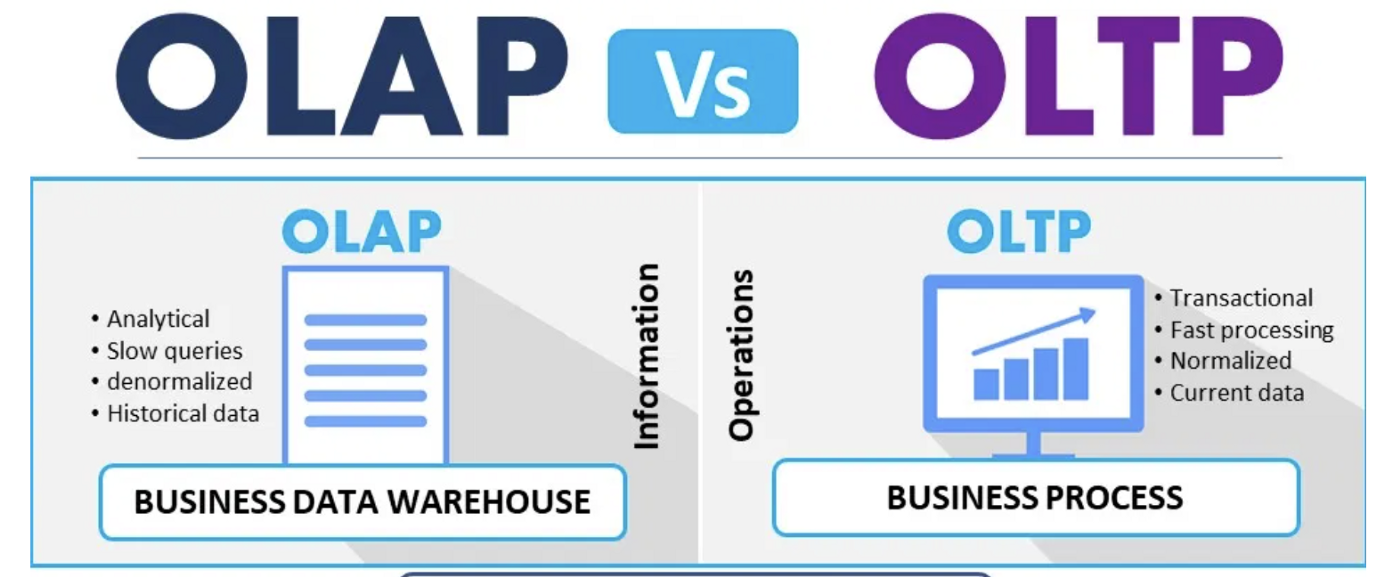
OLAP(Online Analytical Processing)는 온라인 분석 처리라는 뜻의 용어다. OLAP의 목적으로는 데이터 분석, 데이터 마이닝을 통해 사용자의 의사결정에 도움을 주는 것이다. 예시로는 SELECT, SUM, COUNT가 있다.
OLTP(Online Transaction Processing)는 온라인 트랜잭션 처리라는 뜻의 용어다. OLTP의 목적으로는 사용자의 PC에서 발생한 Transaction을 서버가 처리하고, 그 결과를 실시간으로 사용자에게 알리는 것이다. 예시로는 INSERT, DELETE, UPDATE가 있다.
데이터 수집(처리) 방식
데이터 전송 방식에는 크게 벌크 형, 스트리밍 형, 배치 형 이렇게 세 가지가 있다.
벌크형 방식은 이미 어딘가에 존재하는 데이터를 정리해 추출하는 방식으로, DB와 파일 서버등에서 정기적으로 데이터를 수집할 때 사용하는 방법이다.
Stream Processing(스트림 처리)
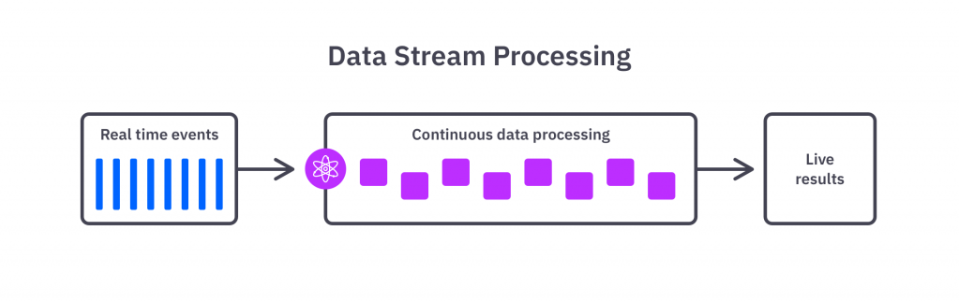
스트리밍 형은 순차적으로 생성되는 데이터를 실시간으로 끊임없이 계속해서 보내는 방법이다. 주로 모바일 애플리케이션이나 암베디드 장비 등에서 데이터를 수집할 때 쓰인다.
기존의 경우, 데이터 웨어하우스에서 데이터를 다룰 때 주로 벌크형 방법이 사용되었지만 시대가 변화하면서 모바일 애플리케이션이 증가함에 따라 스트리밍 방식이 주류가 되었다.
스트리밍 방식으로 받은 데이터는 아무래도 실시간으로 처리하고 싶은데 이것을 스트림 처리라고 한다.
실시간으로 데이터를 처리하기 때문에 지나간 과거의 데이터에는 손을 대지 못하는 단점이 있다. 또한 실시간으로 받는 데이터의 오류나 정확성을 확인하지 못하기 때문에 데이터의 정확성이 떨어질 수 있다.
Batch Processing(배치 처리)
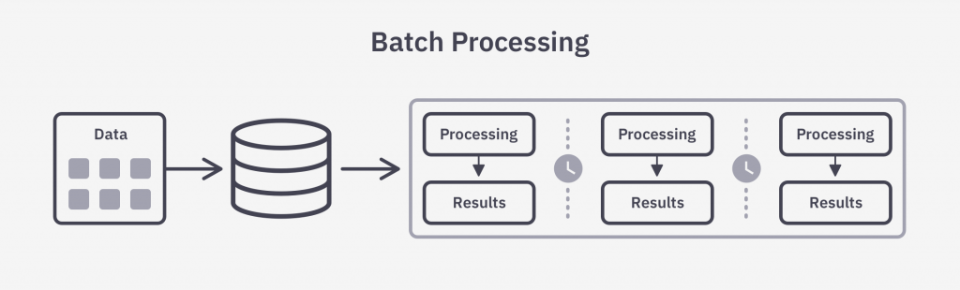
한편 스트림 처리가 장기적인 데이터 분석에 적합하지 않을 때가 있다. 장기간의 대용량 데이터를 분석하려고 하면 처리해야 할 데이터의 양이 수천 배 혹은 수만 배로 증가한다.
실시간으로 대용량의 데이터 분석결과를 하나의 시스템으로 실현하는 것은 쉽지 않기 때문에, 장기간에 걸친 대용량의 데이터 분석을 위해서는 배치 처리가 사용된다.
벌크 형과 비슷하게 스토리지에 저장된 데이터를 정기적으로 추출해 처리하는 방식이고 영속성 덕분에 언제든지 재처리 가능한 장점이 있다.
Stream Processing vs Batch Processing
스트림 처리와 배치 처리에는 각각의 문제점이 존재한다.
먼저 스트림 처리의 문제점으로는
- 틀린 결과, 오류, 누락을 어떻게 보완할 것인가?
- 늦게 전송된 데이터를 어떻게 처리할 것인가?
배치 처리의 문제점으로는
- 정기적으로 텀을 두고 배치 작업때만 데이터를 추출하기 때문에 실시간으로 데이터 확인 불가능
각 처리 방법의 장단점이 모두 있으므로 어느 것이 무조건 좋다고 할 수 없다.
그래서 람다 아키텍처(Lambda Architecture)가 탄생했다.
Lambda Architecture
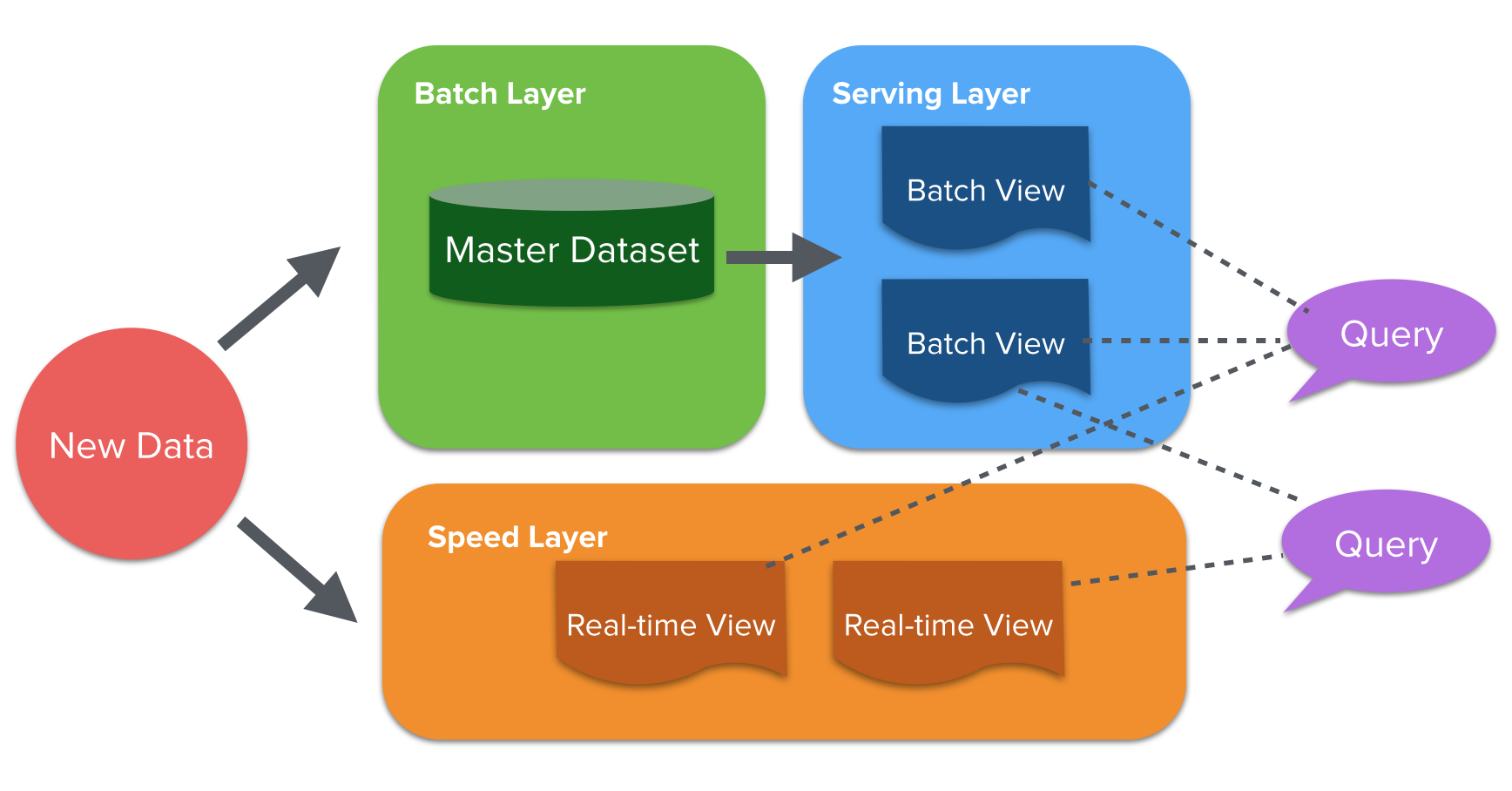
람다 아키텍처는 대량의 데이터를 실시간으로 분석하기 위해 배치로 만든 데이터와 실시간 데이터를 혼합하여 사용하는 방법이다.
람다 아키텍처는 그림과 같이 세 개의 레이어로 구성되어 있다.
배치 레이어(batch layer)
- 모든 데이터는 배치에서 처리 가능하다.
- 과거의 데이터를 장기 저장소에 축적하고 여러 번 다시 집계할 수 있다. (재처리 가능)
- 대용량 데이터를 처리할 수 있지만 한번 처리하는데 보통 시간이 오래 걸린다.
서빙 레이어(serving layer)
- 배치 처리의 결과가 저장되어 있다.
- 정기적인 데이터 업데이트가 있지만 실시간 정보를 얻을 순 없다.
스피드 레이어(speed layer)
- 스트림 처리를 하는 부분으로 실시간으로 데이터를 집계한다.
- 데이터 보관 기간이 짧아 일정 기간이 지난 데이터는 삭제된다.
람다 아키텍처 요약
- 원본 데이터는 장기저장소에 쌓이고 있음.
- 대용량 데이터를 분석하기 위해서는 배치 레이어 이용.
- 배치 레이어가 작업하는 동안에는 실시간 데이터 파악하지 못한다.
- 서빙 레이어를 통해 배치 레이어 작업 내용, 결과 확인.
- 스피드 레이어는 실시간으로 데이터를 조회하고 집계.
그림에서 보듯이 배치 레이어와 서빙 레이어를 묶어서 하나로 본다.
람다 아키텍처는 (배치 레이어 + 서빙 레이어), 스피드 레이어로 이루어져 있고
두 가지 뷰를 조합하여 조회한다.
배치 작업(1h, 12h, 24h, etc)이 완료되기 전까지는 정확성이 떨어지는 실시간 뷰를 이용하다가 배치 작업이 끝나면 업데이트 된 배치 뷰를 이용.
**스트림 처리의 문제점(데이터의 부정확성)을 장기 저장소와 안정적인 배치 처리로 보완하는 것이 람다 아키텍처의 핵심이다.
람다 아키텍처 문제점
독립된 두 개의 파이프라인(배치+레이어, 스트림)을 운영해야하기 때문에 효율↓
파이프라인에서 나온 결과를 병합하거나 양쪽에 쿼리를 해야하기 때문에 번거롭다.
이렇게 람다 아키텍처도 문제점이 있어서 또 다른 아키텍처가 등장했는데
그것이 바로 카파 아키텍처(Kappa Architecture)
Kappa Architecture
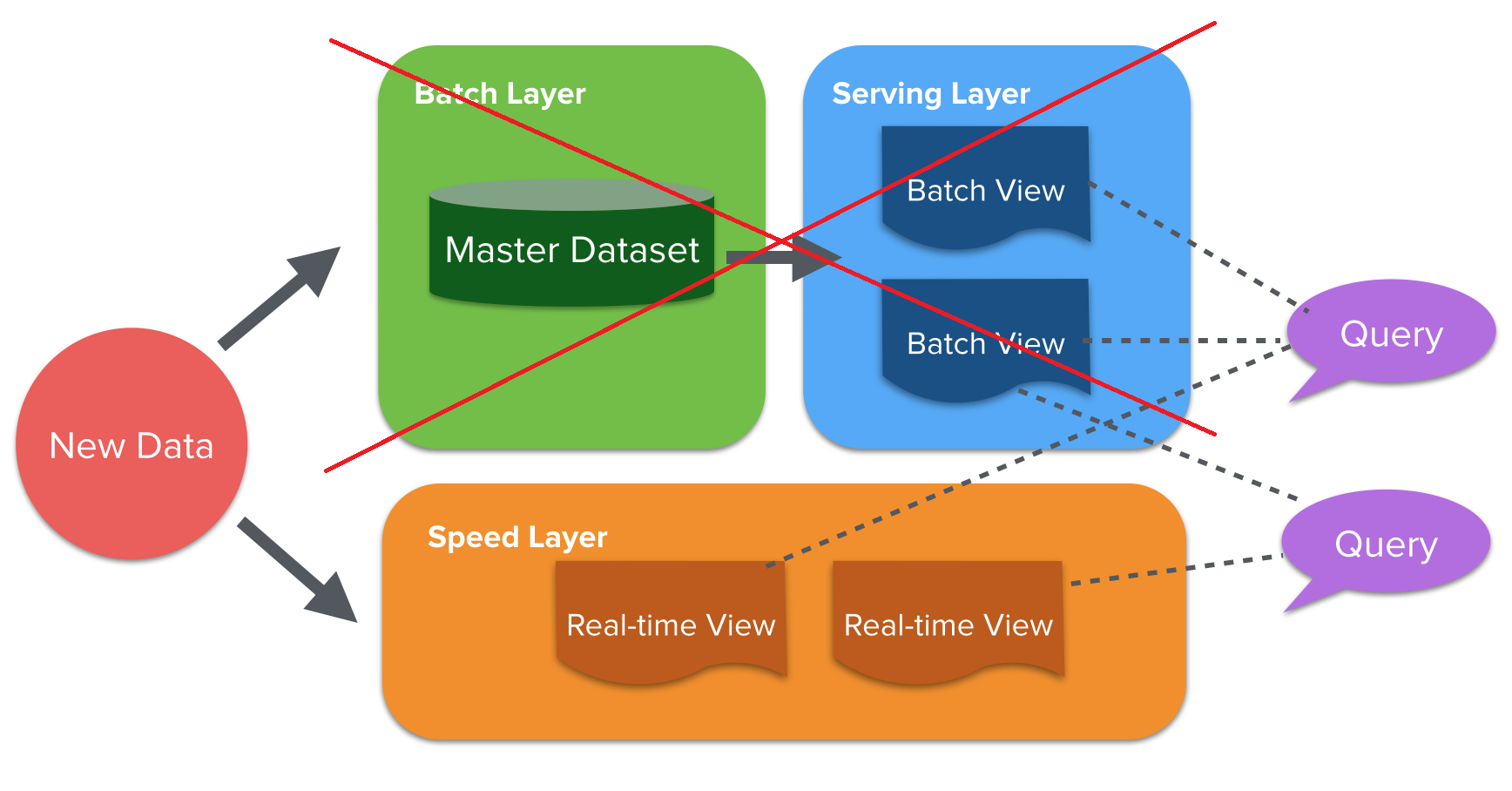
카파 아키텍처는 람다 아키텍처에서 배치 레이어와 서빙 레이어를 제거하고 단순화한 형태다. 단일 파이프라인을 운영하여 효율을 높였고 두 가지 결과물을 병합하는데 있어서 사용했던 컴퓨팅 리소스를 절약하였다.
왜 갑자기 단순화 했을까
이전에는 그러면 스피드 레이어로만 운영하지 못했던 걸까?
왜 람다 아키텍처가 만들어지고 나서야 모델을 단순화 시킨 카파 아키텍처가
등장한 것일까?
- 이전 보다 스트림 기술이 좋아졌다.
- 시장이 실시간 스트리밍을 더 중요시 여기고 있다.
카파 아키텍처가 람다 아키텍처보다 더 좋은 아키텍처라서 그런게 아니라 시장의 니즈가 람다 아키텍처보다 카파 아키텍처에 맞게 바뀌어서 카파 아키텍처가 등장하게 된 것이다.
카파 아키텍처 단점
- 높은 과부하
- 실시간 데이터이므로 이미 지나간 데이터는 재처리가 어려움
- 실시간성, 빠른 반응성 때문에 딥러닝, 머신러닝같은 CPU 집약적(computation-intensive)인 작업은 어려움
그러나 이러한 단점들은 분산 처리, scale-out, 클라우드 컴퓨팅으로 해결 가능하므로 클라우딩을 배워야 한다.
Cloud
데이터 분석과 클라우드 서비스의 관계
빅데이터를 다루는데 필요한 시스템 자원은 매일 변동하며, 갑자기 평소의 몇 배나 되는 처리 능력이 요구되는 경우도 있다. 예를 들어 장시간의 배치 처리 도중에 에러가 발생하여 처음부터 재실행해야 하는 경우, 적어도 지연된 시간을 되찾으려면 보통 때보다 두 배의 자원을 확보해야 한다. 그렇기에 클라우드 서비스처럼 언제라도 자원을 증감할 수 있는 환경은 꼭 필요하다.
클라우드는 데이터 분석을 좀 편하게 하기 위해 이용하는 툴이다.
클라우드 장점
- 확장성
- 늘어나는 데이터를 손쉽게 대응(컴퓨팅 자원, 스토리지, 신규 기능)
- 효율적인 자원 활용
- 뛰어난 비용 효율성
- 현대 데이터 엔지니어링에서 클라우드는 뗄 수 없는 사이
- 데이터를 위한 수많은 서비스
- 개발/구축할 인력 대신 만들어진 서비스를 이용
- 일부 대체 불가능한 서비스들 (ex: Bigquery, S3, etc)
- 법적, 제도적 이슈 (클라우드 및 개인정보 관련 인증과 제도)
- 손쉽게 사용 가능한 ML/DL 솔루션
(여러 서비스 생태계를 누리면서 연동 및 확장 가능)
