4주차 - 카파 아키텍처: 스트림 프로세싱 심화
Lambda Architecture
-
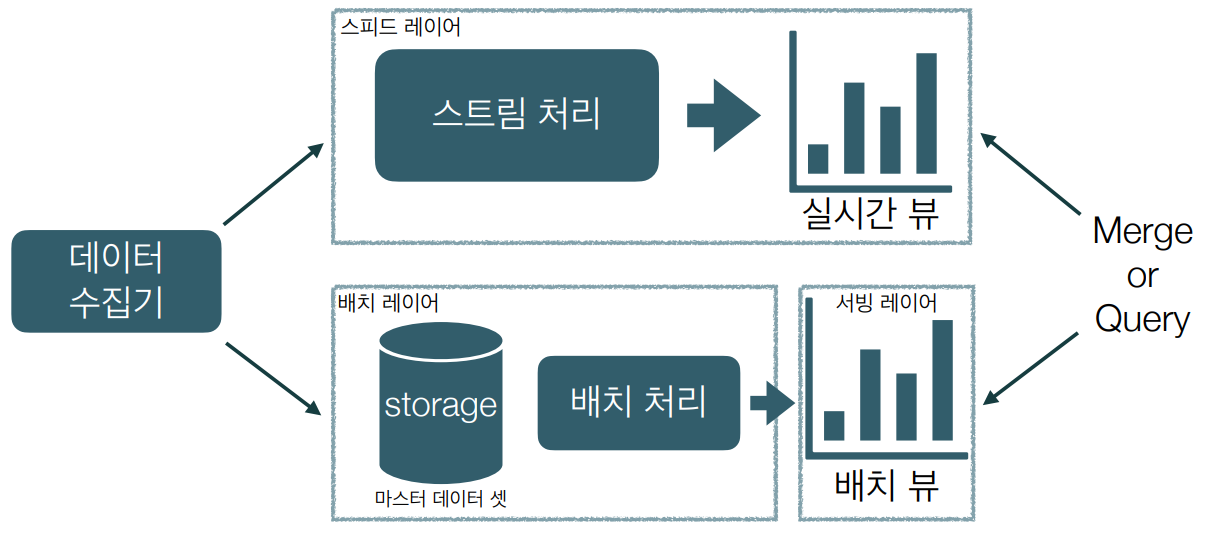
대량의 데이터를 실시간으로 분석하기 위해 batch로 만든 데이터와 실시간 데이터를 혼합하여 사용하는 아키텍처
-
Lambda Architecture = batch layer + serving layer + speed layer
Lambda Architecture에 대한 회의감
Disney가 Lambda Architecture 버린 이유
• Duplicate Code
: 두 개의 서로 다른 코드와 개발 팀, 유닛 테스트가 필요하다. 따라서 하나가 바뀌면 모두 전파해야 하고 릴리즈 또한 연동되어야 한다.
• Data Quality
: Batch & Speed layer 간의 알고리즘이 일치하는가? 그걸 어떻게 입증할 것인가?
• Added Complexity
: 어떤 데이터를 언제 읽을지? 배치 잡의 딜레이? 고려할것이 많다.
• Two Distributed Systems
: 두 배의 인프라를 구성해야 하고 모니터링, 로깅도 각각 해야하니 2배이다.
Kappa Architecture
-
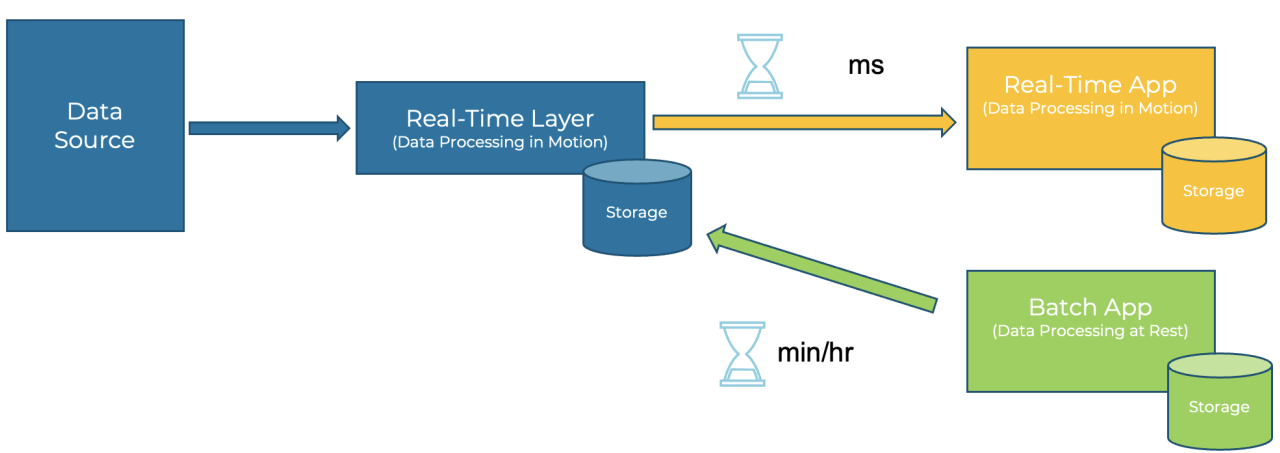
스트림 처리로만 파이프라인을 구성해서 단순화(배치, 스피드 버림)
-
단일 파이프라인을 운영하여 효율 up, 컴퓨팅 리소스를 절약 on
스트림 프로세싱 심화

- 스트림 처리가 중요해지면서 데이터의 처리 - 저장 - 분석 단계가 중요해지고 복잡해짐.
Apache Flink

-
Flink는 독일어로 민첩함을 뜻하는 단어로 Apache Flink는 베를린 TU대학교에서 만들어져 현재 널리 사용되고 있는 분산 스트림 처리 프레임워크다.(Processing unbounded data)
-
Exactly-once의 이벤트 처리를 보장하는 네이티브 스트림 방식으로, 지연 발생이 적고 처리량은 높으며 비교적 사용하기 쉽다.
-
일괄처리 기능도 제공하지만 스트림 프로세싱을 목적으로 주로 사용
-
단순 수집과 전달에서부터 합계·평균 계산과 같은 집계, 패턴에 기반한 예측 분석 및 데이터 형식을 변환, 다른 데이터 소스와 결합(join) 등의 작업이 가능하다.
Apache Flink 특징
Stream & Batch processing
• 스트림 처리 & 배치 처리 모두 가능한 통합 데이터 처리 엔진
• DataStream API와 DataSet API(legacy) / Table API
• Batch Runtime Mode for bounded flink program
• env.setRuntimeMode(RuntimeExecutionMode.BATCH);
High Performance(Native Stream & Low Latency & High Throughput)
• Spark Streaming처럼 micro/mini batch 구조가 아닌 완전 스트림 최적화 방식
• Flink 외에도 Kafka streams도 이와 같은 방식
• 지연시간 최소화
• 높은 처리량
• 전체적으로 우수한 성능을 보여준다.
Fault-tolerance
• Flink의 핵심이라고 할 수 있는 Checkpoint라는 기술을 이용해 장애 감내성을 제공한다.

• Checkpoint는 분산 체크포인팅 및 분산 스냅샷 기술의 일종
• Chandy-Lamport 알고리즘을 개선한 알고리즘이 적용되어 있다.
• Exactly-once를 지원하기 위해서도 사용된다.
데이터를 어딘가에 꼭 저장해야 하는 것은 아니다!
연산/분석 결과만 다른 곳으로 전달하는 것 또한 Flink의 역할 중 하나
Dataflow Programming
• DAG(Directed Acyclic Graphs) : 유향 비순환 그래프(방향성 비순환 그래프)
Dataflow graph
• Source Operator : 그래프 상에서 제일 처음인 입력부(입력이 없는 연산자)
A operator
• Transformation Operator : 변환/연산 등을 하는 연산자
B, C operator
• Sink Operator : 그래프 상에서 제일 마지막인 출력부(출력이 없는 연산자)
D operator
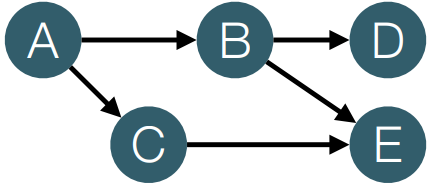
ETL과 비슷
[Extract-Transform-Load] : [Source-Transformation-Sink]
Source operator
• Custom source
• Apache Kafka
• AWS Kinesis Streams
• RabbitMQ
• Twitter Stream API
• Google PubSub
• Collections
• Files
• Sockets
Sink operator
• Custom sink
• Elasticsearch
• Kafka producer
• Cassandra
• AWS Kinesis Streams
• File • Socket
• Standard output
• Redis
Transformation operator
• Map : 사용자가 정의한 변환 코드를 통과시켜 하나의 이벤트를 출력

• FlatMap : map과 유사하지만 각 요소에 대해 0개 이상의 출력을 생성

• Filter : 특정 조건에 따라 pass or drop

• KeyBy : 특정 키를 이용해서 스트림을 파티션별로 분리
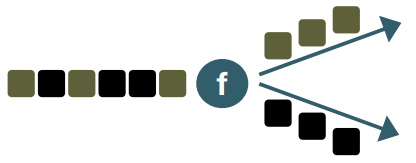
• Union : 두 개 이상의 동일한 타입의 스트림을 병합
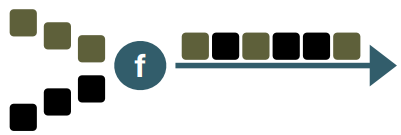
• Reduce : 키별로 나뉜 데이터 스트림을 합쳐주는 역할
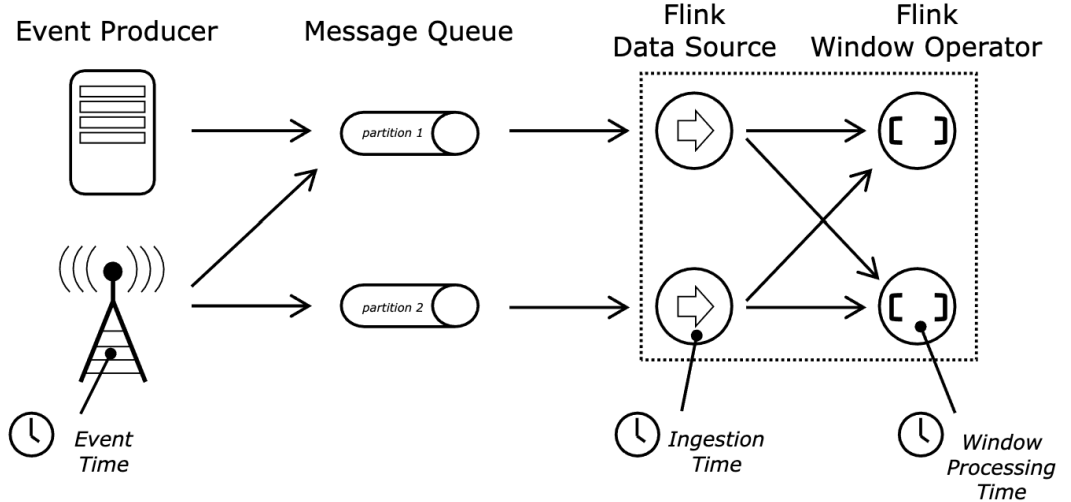
Flink에서의 Time
• Event Time : 데이터가 실제로 생성된 시간
• Ingestion Time : 데이터 Flink job으로 유입된 시간
• Processing Time : 데이터가 특정 operator에서 처리된 시간
Windows
• 규칙적이고 반복적인 시간 기반의 집계
• '각 x 기간의 그룹화 함수'로 표현
Tumbling Windows(그룹별 집계)
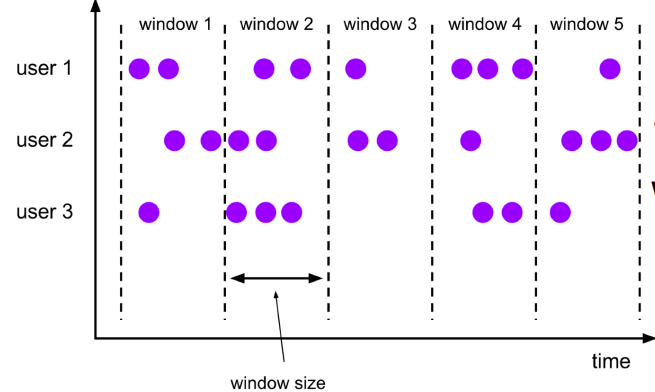
• 겹치지 않는 고정된 윈도우의 그룹
• 절대 중복으로 처리되는 데이터가 없다.
• 각 윈도우가 이전 윈도우와 독립적
Sliding Windows
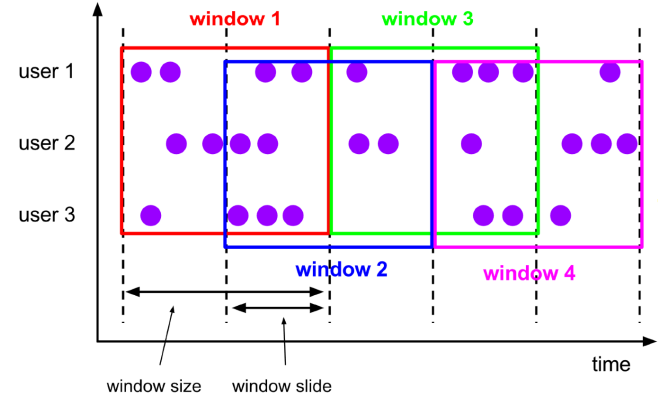
• N 시간마다 +-M시간 전후 데이터를 한 window에서 처리되는 개념
• 중복데이터를 허용, window마다 앞뒤로 중복으로 처리되는 데이터가 존재
• 사용 예시 :
10초마다 최근 1분간의 온도의 평균을 계산하는 프로세스가 있다면 위에서 설명한 Tumbling window로 처리할 수 없다. 간격보다 처리해야할 데이터의 시간이 더 크기 때문이다. 그럴 때 Sliding Windows 사용
Session Windows
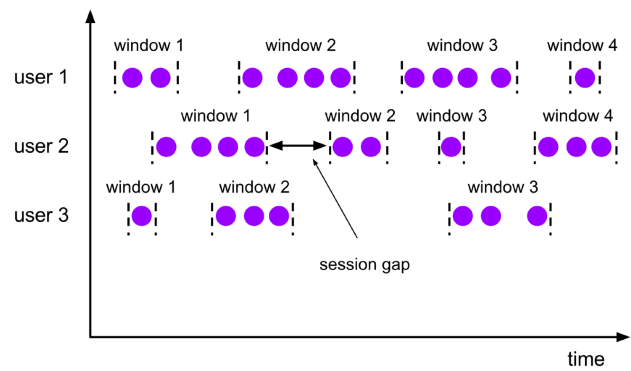
• 일정 기간동안 반응이 없는 경우 세션 시작부터 반응이 없는 시간까지의 데이터를 하나의 window size로 처리한다.
• 사용 에시 :
session gap을 5초로 가정하고 5초 동안 데이터가 들어오지 않으면 window를 쪼개는 방식이다. 00:00부터 1초 간격으로 데이터가 꾸준히 들어오다가 00:10초부터 데이터가 들어오지 않고 00:17초 에 데이터가 들어왔다면 session gap인 5초를 지나 00:00~00:10가지의 데이터를 window size로 정해진다.
• 그림을 보면 session gap마다 window가 처리되는 것을 볼 수 있다.
따라서 하나의 window에서 처리되는 element 갯수가 굉장히 다를 수 있다.
Global Window

• global window는 하나의 윈도우로 모든 데이터를 처리한다.
따라서 trigger와 evictor를 설정해야지만 의미있게 사용할 수 있다.
trigger는 가져올 데이터에 대한 정의를 하고, evictor는 처리할 데이터에 대한 정의이다.
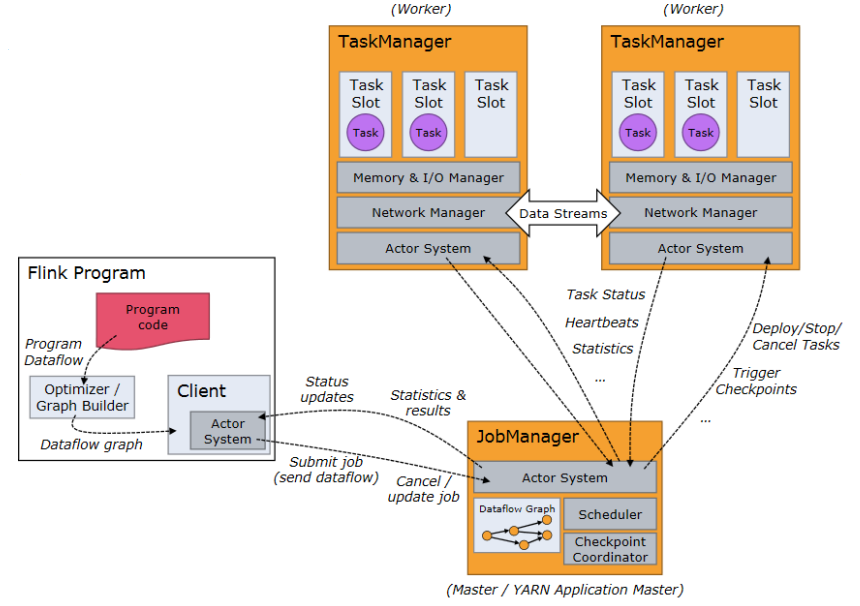
Flink Architecture
Master가 worker들을 관리하고, Worker는 각 task를 실행하는 구조이다.
Client는 런타임안에서 실행되지 않고 접속하여 컨트롤 및 정보 전달을 수행한다.
Job Manager: Master
- kafka에서 Zookeeper랑 비슷
- Task scheduling
- Checkpointing
- Recovery
Task Manager: Worker
- Task execution
Programs and Dataflows
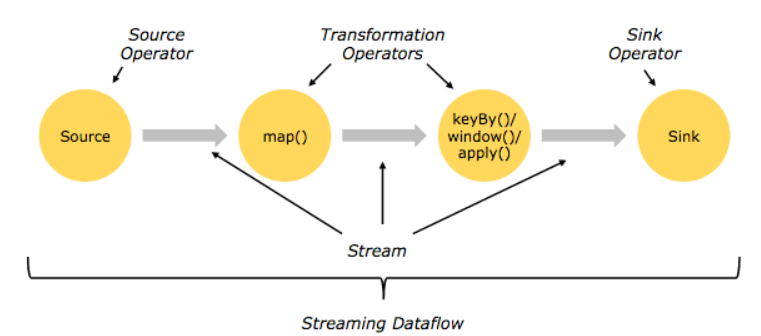
Flink의 기본 빌딩 블록은 다른 스트림 시스템과 유사하다.
flink에서는 인풋 스트림을 Source, Operation을 Transformation 그리고 아웃풋을 Sink라고 명명하고 있다.
Source로 스트림 데이터를 받아 여러 Transformation으로 데이터를 가공하고 Sink로 데이터를 처리(저장)을 하는 전체 플로우가 Streaming dataflow이다.
위 그림은 Flink에서 dataflow를 구성하는 소스코드와 스트림이 처리되는 flow를 그림으로 잘표시하고 있다.
처음과 끝을 Source와 Sink로 구성되어 있고, 중간에 Transformation을 2개 구성하여 데이터를 가공한다. Source, Transformation, Sink간의 데이터는 Stream 형태로 전달된다.
출처: https://gyrfalcon.tistory.com/entry/Flink-1-소개-Basic-Concept [Minsub's Blog:티스토리]
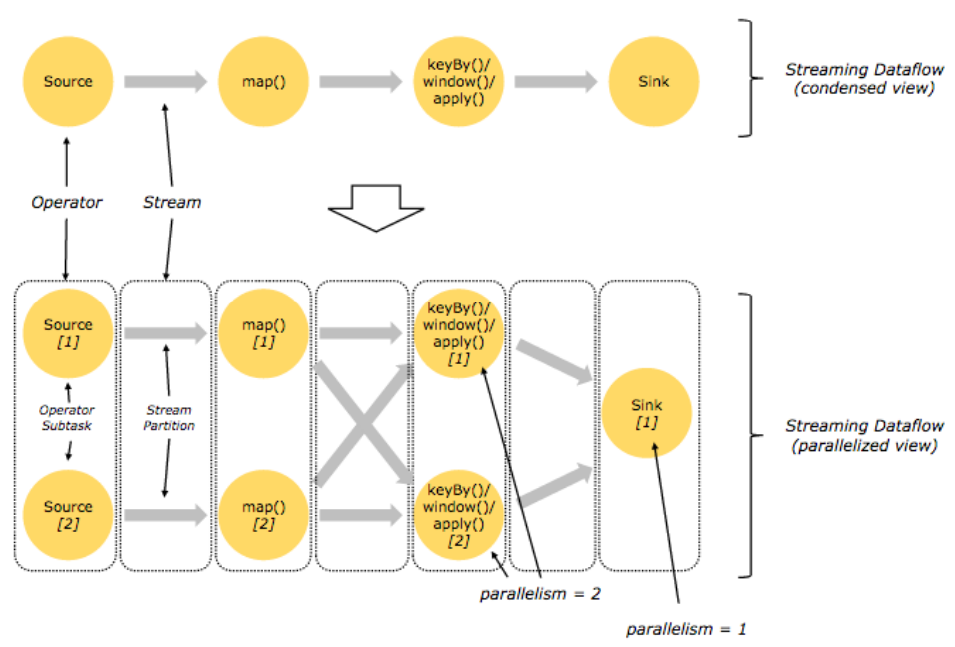
Streaming Dataflow
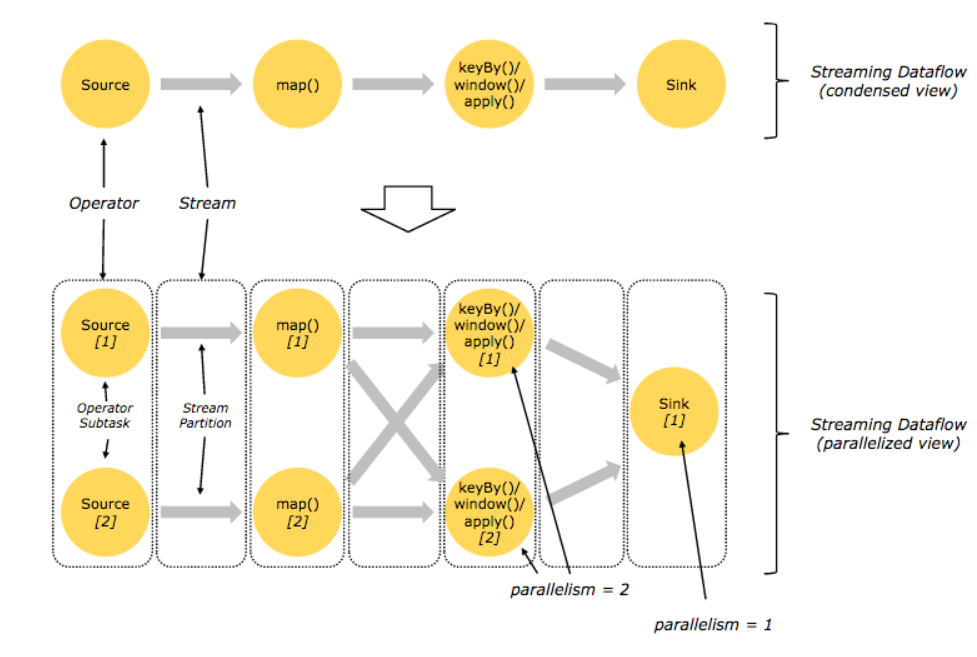
Flink는 분산환경에서 각각의 operator들이 Parallel하게 처리될 수 있다.
Stream은 여러 stream paritions으로 구성될 수 있고, Operator또한 여러 operator subtasks로 나뉠 수 있다. Flink가 나름 용어를 지정하여 사용하고 있지만, 간단히 말해 여러 스레드에서 parallel하게 분산처리를 한다고 생각하면 된다.
위에서 설명한 dataflow를 Parallel하게 처리되는 구조로 변경된 그림이다. 2개의 Parallelism으로 설정하면 각 operator들이 각각의 thread에서 실행하여 처리된다.
이때 연산자의 특성에 따라 모든 stream에서 데이터를 받아 처리될 수 있고 1:1로 매핑될 수 있다.
이 예제에서는 keyBy()연산자는 각 subtasks에서 key별로 처리되기 때문에 이전의 transformation에서 map으로 처리된 데이터를 양쪽 모두에서 받아서 처리된다.
Distributed Execution
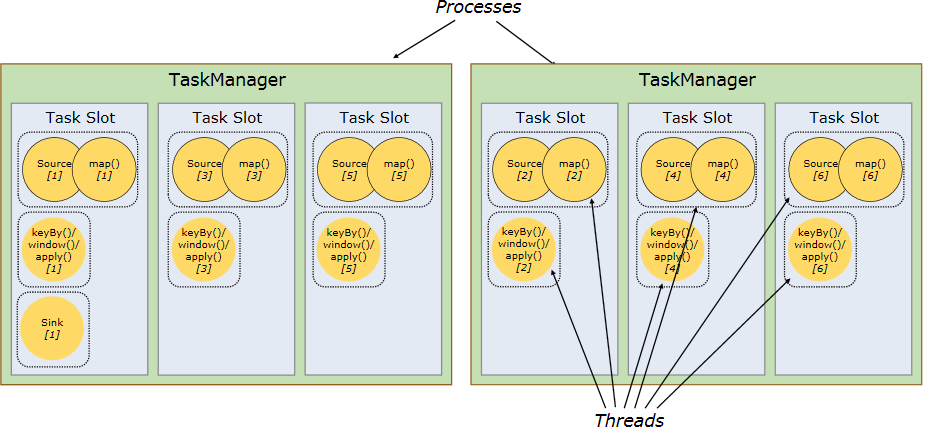
각 worker(Task Manager)는 JVM 프로세스 단위로 동작하고 1개 이상의 Subtask들이 각 스레드로 실행된다.
task는 task slot안에서 실행되는데 task slot은 각 worker내의 resource(메모리)를 나누어 관리한다. 즉, slot별로 개별적인 메모리 공간에서 task들이 실행되는 구조이다. 보통 slot의 갯수는 CPU core갯수로 지정하는 것이 좋다.
