Logistic Regression
- 분류 문제는 0 또는 1로 예측해야 하나 Linear Regression을 그대로 적용하면 예측값 hθ(x)는 0보다 작거나 1보다 큰 값을 가질 수 있음
- hθ(x)가 항상 0에서 1 사이의 값을 갖도록 Hypothesis 함수를 수정
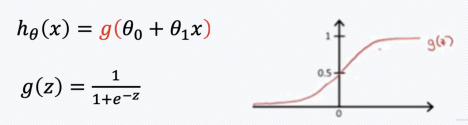
# logistic function
import numpy as np
z = np.arange(-10, 10, 0.01)
g = 1 / (1+np.exp(-z))z, gimport matplotlib.pyplot as plt
%matplotlib inline
plt.plot(z, g)plt.figure(figsize=(12, 8))
ax = plt.gca()
# gca() : 설정값 변경 가능 함수
ax.plot(z, g)
# spines() : 축 지정
ax.spines['left'].set_position('zero')
ax.spines['right'].set_color('none')
ax.spines['bottom'].set_position('center')
ax.spines['top'].set_color('none')
plt.show()- Decision Boundary
- Logistic Regression에서 Cost Function 재정의
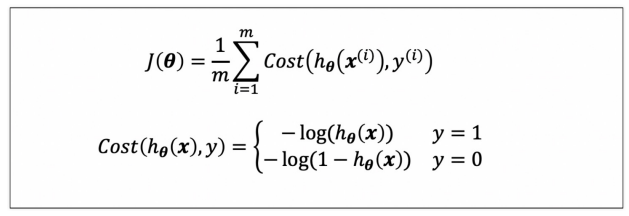
- Learning 알고리즘은 동일

# Logistic Reg. Cost Function의 그래프
h = np.arange(0.01, 1, 0.01)
C0 = -np.log(1-h)
C1 = -np.log(h)
plt.figure(figsize=(12, 8))
plt.plot(h, C0, label = 'y=0')
plt.plot(h, C1, label = 'y=1')
plt.legend()
plt.show()실습 - 와인데이터
- 와인 등급
# 데이터 받기
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine.head()# 맛 등급 만들기
wine['taste'] = [1 if grade > 5 else 0 for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)# 간단 로지스틱 회귀 테스트
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver = 'liblinear', random_state=13)
#solver = 'liblinear' : 최적화 알고리즘을 liblinear로 설정
lr.fit(X_train, y_train)y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))# 스케일러까지 적용해서 파이프라인 구축
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()), # standardscaler() : 기존 변수의 범위를 정규 분포로 변환하는 것.
('clf', LogisticRegression(solver='liblinear', random_state=13))] # 분류기
estimatorspipe = Pipeline(estimators)
pipe#fit
pipe.fit(X_train, y_train)# 상승효과가 있긴 하다
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))# Decision Tree와의 비교
from sklearn.tree import DecisionTreeClassifier
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
models = {'logistic regression' : pipe, 'decision tree' : wine_tree}
models# AUC 그래프를 이용한 모델간 비교
from sklearn.metrics import roc_curve
plt.figure(figsize=(10, 8))
plt.plot([0, 1], [0, 1], label = 'random_guess')
for model_name, model in models.items():
pred = model.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label = model_name)
plt.grid()
plt.legend()
plt.show()실습 - PIMA 인디언 당뇨병 예측
- 원래 데이터는 kaggle
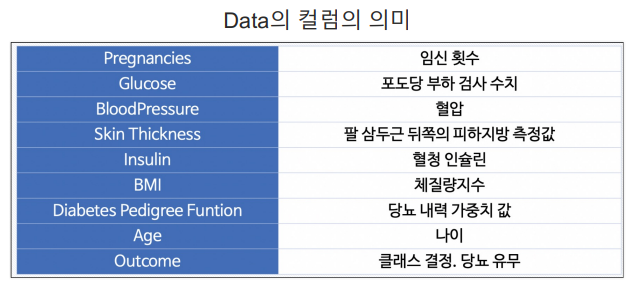
# 데이터 읽기
import pandas as pd
PIMA_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/diabetes.csv'
PIMA = pd.read_csv(PIMA_url)
PIMA.head()
# 데이터 확인
PIMA.info()# float으로 데이터 변환
PIMA = PIMA.astype('float')
PIMA.info()# 상관관계 확인
# Outcome과 다른 특성과의 관계
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(12, 10))
sns.heatmap(PIMA.corr(), cmap='YlGnBu')
plt.show()# 0인 데이터 존재 ★
# 0이라는 숫자가 혈압에 있는 것은 문제로 보임
(PIMA==0).astype(int).sum()# 의학적 지식과 PIMA 인디언에 대한 정보가 없으므로 일단 평균값으로 대체
zero_features = ['Glucose', 'BloodPressure', 'SkinThickness', 'BMI']
PIMA[zero_features] = PIMA[zero_features].replace(0, PIMA[zero_features].mean())
(PIMA==0).astype(int).sum()
# 데이터 나누기
from sklearn.model_selection import train_test_split
X = PIMA.drop(['Outcome'], axis=1)
y = PIMA['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13,
stratify=y) # stratify 값을 설정하면 비율에 맞춰 나눠짐
# Pipeline 만들기
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
estimators = [('scaler', StandardScaler()),
('clf', LogisticRegression(solver='liblinear', random_state=13))]
estimatorspipe_lr = Pipeline(estimators)
pipe_lrpipe_lr.fit(X_train, y_train)pred = pipe_lr.predict(X_test)
pred# 수치 확인
# 상대적 의미를 가질 수 없어서 이 수치 자체를 평가할 수는 없다.
from sklearn.metrics import (accuracy_score, recall_score, precision_score,
roc_auc_score, f1_score)
print('Accuracy : ', accuracy_score(y_test, pred))
print('Recall : ', recall_score(y_test, pred))
print('Precision : ', precision_score(y_test, pred))
print('AUC score : ', roc_auc_score(y_test, pred))
print('f1 score : ', f1_score(y_test, pred))# 다변수 방정식의 각 계수 값 확인
coeff = list(pipe_lr['clf'].coef_[0])
# coef :특성에 대한 계수를 포함한 배열
labels = list(X_train.columns)coeff# 중요 feature 그래프
# 포도당, BMI 등은 당뇨에 영향을 미치는 정도가 높다.
# 혈압은 예측에 부정적 영향을 준다.
# 연령이 BMI보다 츨력 변수와 더 관련되어 있었지만, 모델은 BMI와 Glucose에 더 의존함
features = pd.DataFrame({'Features':labels, 'importance':coeff})
features.sort_values(by=['importance'], ascending=True, inplace=True)
features['positive'] = features['importance'] > 0
features.set_index('Features', inplace=True)
features['importance'].plot(kind='barh', figsize=(11, 6)
, color = features['positive'].map({True:'blue', False:'red'}))
plt.xlabel('Importance')
plt.show()featuresPrecision and Recall - 정밀도와 재현율의 트레이드오프
# 데이터 받기
import pandas as pd
wine_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
wine = pd.read_csv(wine_url, index_col=0)
wine['taste'] = [1 if grade > 5 else 0 for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 간단한 로지스틱 회귀 적용
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression(solver='liblinear', random_state=13)
lr.fit(X_train, y_train)
y_pred_tr = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
print('Train Acc : ', accuracy_score(y_train, y_pred_tr))
print('Test Acc : ', accuracy_score(y_test, y_pred_test))- classification_report
- macro avg : 클래스별 평균
- weighted avg : 클래스별 분포를 반영한(support가 반영된) 평균
# classification_report
# macro avg : 클래스별 평균
# weighted avg : 클래스별 분포를 반영한(support가 반영된) 평균
from sklearn.metrics import classification_report
print(classification_report(y_test, lr.predict(X_test)))
- confusion matrix
# confusion matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, lr.predict(X_test))
- precision_recall curve
# precision_recall curve
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
%matplotlib inline
plt.figure(figsize=(10, 8))
pred = lr.predict_proba(X_test)[:, 1]
precisions, recalls, thresholds = precision_recall_curve(y_test, pred)
plt.plot(thresholds, precisions[:len(thresholds)], label = 'precision')
plt.plot(thresholds, recalls[:len(thresholds)], label = 'recall')
plt.grid()
plt.legend()
plt.show()# threshlod = 0.5 : 분류기준
pred_proba = lr.predict_proba(X_test)
pred_proba[:3] # [0일 확률, 1일 확률]# 간단히 확인해보기
import numpy as np
np.concatenate([pred_proba, y_pred_test.reshape(-1, 1)], axis=1)
# reshape(-1, 1): 크기는 유지하되, 마지막에는 1로 만들어달라pred_probay_pred_test# threshold 바꿔보기 - Binarizer
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.6).fit(pred_proba)
pred_bin = binarizer.transform(pred_proba)[:, 1]
pred_binprint(classification_report(y_test, lr.predict(X_test)))# 다시 classification report
print(classification_report(y_test, pred_bin))# 다시 confusion matrix
confusion_matrix(y_test, pred_bin)💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅