식물의 사진으로 질변분류 - 학습하기
- colab에서 작성
from google.colab import drive
drive.mount('/content/drive')# 구글 드라이브에 올린 파일 압축 풀어서 colab 폴더에 두기
!unzip -qq '/content/drive/MyDrive/Colab Notebooks/dataset.zip' -d './dataset'import os
original_dataset_dir = './dataset'
classes_list = os.listdir(original_dataset_dir)
base_dir = './splitted'
#os.mkdir(base_dir)
# 이미 생성된 경우에는 실행시키면 에러가 날 수 있음# 데이터 정리를 위한 목록 및 폴더 생성
import shutil
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'val')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
for cls in classes_list: # 폴더 이름을 다 동일하게 넣기
os.mkdir(os.path.join(train_dir, cls))
os.mkdir(os.path.join(validation_dir, cls))
os.mkdir(os.path.join(test_dir, cls))# 데이터 현황 확인
import math
for cls in classes_list:
path = os.path.join(original_dataset_dir, cls)
fnames = os.listdir(path)
# train, validation, test의 비율 지정
train_size = math.floor(len(fnames) * 0.6)
validation_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
train_fnames = fnames[:train_size]
print('Train size(",cls,"): ', len(train_fnames))
for fname in train_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(train_dir, cls), fname)
shutil.copyfile(src, dst)
validation_fnames = fnames[train_size:(validation_size + train_size)]
print('Validation size(",cls,"): ', len(validation_fnames))
for fname in validation_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(validation_dir, cls), fname)
shutil.copyfile(src, dst)
test_fnames = fnames[(train_size + validation_size):(validation_size + train_size + test_size)]
print('Test size(",cls,"): ', len(test_fnames))
for fname in test_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, cls), fname)
shutil.copyfile(src, dst)# 학습준비
import torch
import os
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device('cuda' if USE_CUDA else 'cpu')
BATCH_SIZE = 256 # 크면 빠르긴 한데 gpu 메모리 한계에 걸릴 수 있어 주의 필요
EPOCH = 30import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
transform_base = transforms.Compose([transforms.Resize((64, 64)), transforms.ToTensor()])
train_dataset = ImageFolder(root='./splitted/train', transform=transform_base)
val_dataset = ImageFolder(root='./splitted/val', transform=transform_base)
# ImageFolder : 폴더 이름을 라벨로 본 것?...from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 4)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 4)import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding = 1)
self.fc1 = nn.Linear(4096, 512)
self.fc2 = nn.Linear(512, 33)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = x.view(-1, 4096)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model_base = Net().to(DEVICE)
optimizer = optim.Adam(model_base.parameters(), lr=0.001)def train(model, train_loader, optimizer):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad(): #with 구문이 끝나면 끝남?...가중치를 업데이트 하지 못하게끔..?..
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100 * correct / len(test_loader.dataset)
return test_loss, test_accuracyimport time
import copy
def train_baseline(model, train_loader, val_loader, optimizer, num_epochs = 30):
best_acc = 0
best_model_wts = copy.deepcopy(model.state_dict())
# 정확도가 가장 높은 weight를 저장하기 위해..
for epoch in range(1, num_epochs + 1):
since = time.time()
train(model, train_loader, optimizer)
train_loss, train_acc = evaluate(model, train_loader)
val_loss, val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_acc = val_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('------------------------ epoch {} -----------------------' .format(epoch))
print('train Loss : {:.41f}, Accuracy : {:.2f}%' .format(train_loss, train_acc))
print('val Loss : {:.41f}, Accuracy : {:.2f}%' .format(val_loss, val_acc))
print('Completed in {:.0f}m {:.2f}s' .format(time_elapsed // 60, time_elapsed % 60))
model.load_state_dict(best_model_wts)
return model
base = train_baseline(model_base, train_loader, val_loader, optimizer, EPOCH)
torch.save(base, 'baseline.pt')전이학습
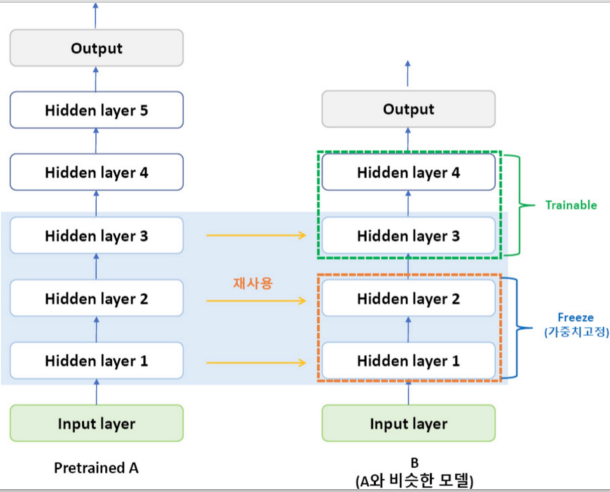
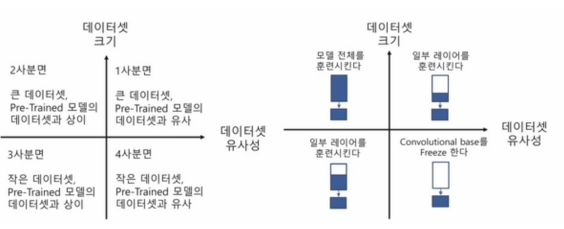
전이학습 모델 수정 후 학습시키기 - 식물잎의 사진으로 질병 분류
# transforms : https://wikidocs.net/157285
# RandomCrop : 사진의 아무 곳 이미지를 자르는 것, 일부를 보여주는 효과..
data_transforms = {
'train': transforms.Compose([transforms.Resize([64, 64]),
transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(),
transforms.RandomCrop(52), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])]), # rgb 평균, 표준편차값, Normalize : 설정하면 색상에 대한 학습 능력이 올라간다고 함..
'val' : transforms.Compose([transforms.Resize([64, 64]),
transforms.RandomCrop(52), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
}data_dir = './splitted'
image_datasets = {x : ImageFolder(root = os.path.join(data_dir, x),
transform = data_transforms[x]) for x in ['train', 'val']}
dataloaders = { x : torch.utils.data.DataLoader(image_datasets[x],
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 4) for x in ['train', 'val']}
dataset_sizes = {x : len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classesfrom torchvision import models
resnet = models.resnet50(pretrained=True) # resnet50(pretrained=True) : 구조및 학습이 완료된 weight를 가져옴
num_ftrs = resnet.fc.in_features # 마지막 레이어를 바꿔주어야 함
resnet.fc = nn.Linear(num_ftrs, 33)
resnet = resnet.to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad, resnet.parameters()), lr = 0.001)
# 마지막 교체한 33개는 학습이 안되어 있어 requires_grad 설정해주어야 함
from torch.optim import lr_scheduler
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size = 7, gamma = 0.1)
# 7 epoch마다 0.1씩 감소
# https://sanghyu.tistory.com/113ct = 0
for child in resnet.children():
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False # 0 - 5번까지의 레이어를 학습하지 않도록 하는 것..def train_resnet(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict()) # 학습이 잘된 weight 저장
best_acc = 0
for epoch in range(num_epochs):
print('------------------- epoch {} -----------------' .format(epoch + 1))
since = time.time()
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0) # 설정된 batch size
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss : {:.4f} Acc : {:.4f}' .format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Completed in {:.0f}m {:.0f}s' .format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc : {:4f}' .format(best_acc))
model.load_state_dict(best_model_wts)
return model
model_resnet50 = train_resnet(resnet, criterion, optimizer_ft,
exp_lr_scheduler, num_epochs=EPOCH)
torch.save(model_resnet50, 'resnet50.pt')transform_resNet = transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
test_resNet = ImageFolder(root = './splitted/test', transform = transform_resNet)
test_loader_resNet = torch.utils.data.DataLoader(test_resNet,
batch_size = BATCH_SIZE,
shuffle = True,
num_workers = 4)# transfer learning 모델 성능 평가
resnet50 = torch.load('resnet50.pt')
resnet50.eval()
test_loss, test_accuracy = evaluate(resnet50, test_loader_resNet)
print('ResNet test acc : ', test_accuracy)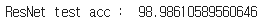
많이 어렵다..ㅠㅠ
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅