학습내용
Validation data
train : 학습데이터
validation : 학습시킨 모델을 평가하여 모델을 발전시켜나가는데 사용되는 데이터
test : 모델의 최종 성능 확인 데이터
Logistic Regression
classification의 한 종류
분류모델의 성능평가는 일반적으로 accuracy를 많이 사용함
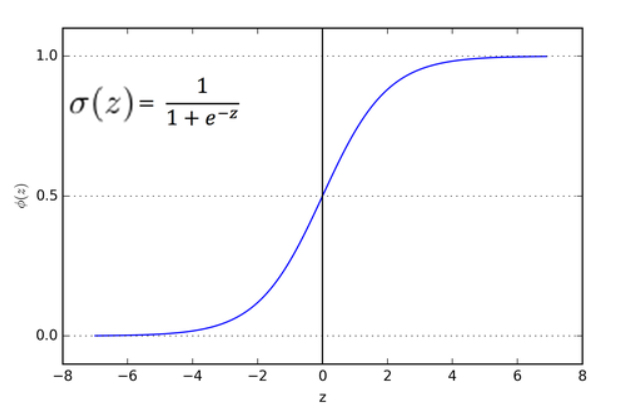
위의 수식을 이용하여 관측치가 특정 클래스 속할 확률값을 계산하여 classification
아래의 odds를 이용하면 결과에 대한 해석이 좀 더 쉬워짐
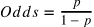
odds에 로그를 취해 변환하면 선형회귀식이 나오는데 이 변환을 로짓변환이라고 함. 이를 이용하여 회귀계수에 대한 설명을 용이하게 함
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegressionCV
from sklearn.metrics import accuracy_score
logistic = LogisticRegression(C = 0.1, max_iter=1000)
#penalty = 'l2'으로 고정
#C는 정규화의 정도를 나타냄
logistic.fit
logistic.predict
logistic.score() # = accuracy_score(y_test, y_pred)학습된 logistic 모델의 회귀계수 나타내기istic 모델의 회귀계수 나타내기
coefficients = pd.Series(logistic.coef_[0], X_train.columns)
coefficients.sort_values().plot.barh(); #h빼면(bar) 가로로 나타남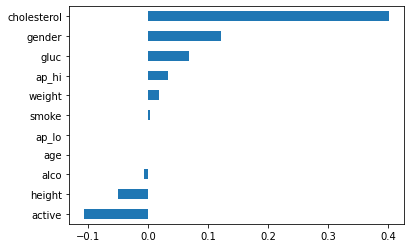
Grid search
grid_search는 최적의 parameter를 찾고 이를 이용하여 train, validation를 합친 data를 fit 한다.
#grid_search 이용
from sklearn.model_selection import GridSearchCV
param_grid = {
'C' : [0.001, 0.01, 0.1, 1, 10, 100],
'max_iter' : [100,1000]
}
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid_search.fit(X_train_val, y_train_val)
print('test accuracy : ', grid_search.score(X_test, y_test))
print('최적의 parameters : ', grid_search.best_params_)
#직접구현
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
Cs = [0.001, 0.01, 0.1, 1, 10, 100]
max_iters = [100,1000]
best = 0
for C in Cs:
for max_iter in max_iters:
model2 = LogisticRegression(C=C, max_iter=max_iter)
temps = cross_val_score(model2, X_train_val, y_train_val, cv=5)
score = np.mean(temps)
if best < score:
best = score
params = {
'C' : C,
'max_iter' : max_iter
}Imputer
simpleimputer : na값을 평균값으로 대체해줌
from sklearn.impute import SimpleImputer
## default, imputing 'mean' value
imputer = SimpleImputer()
X_train_imputed = imputer.fit_transform(X_train)
X_val_imputed = imputer.transform(X_val)