
20211103
💡Key Point💡
1. 활성화 함수
2. 선형과 비선형
3. 활성화 함수 종류
1. 활성화 함수(activation function)
특정 조건(ex. 임계치) 만족 여부에 따라 활성화, 비활성화를 결정.
딥러닝 모델의 표현력을 향상을 위해 사용(representation capacity or expressivity)
-
선형 함수로는 비선형 함수를 표현할 수 없다.
-
모델의 파라미터와 입력값은 선형 관계
-
비선형 데이터를 표현하기 위해서는 모델이 비선형성을 가져야 함
-
비선형성을 위해 사용되는 것이 활성화 함수
-
선형 활성화 함수(Linear activation function), 비선형 활성화 함수(Non-linear activation function)로 나눌 수 있음
2. 퍼셉트론(Perceptron)
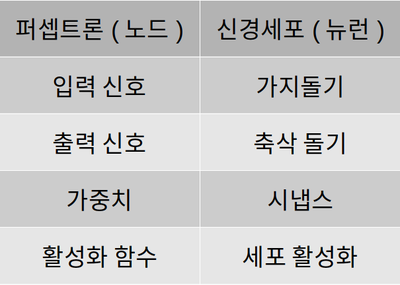
출처: AIFFFEL FUNDAMENTALS_SSAC2 23. 활성화 함수의 이해
3. 선형 변환(linear transformation)
선형으로 공간상의 벡터를 공간상의 벡터로 바꿔주는 역할
-
, 에 대한 가정
-
모두 벡터 공간(≒좌표평면, 벡터를 그릴 수 있는 공간)
-
둘 모두 실수 집합상에 있다고 가정
-
: 정의역(domain) 역할
-
: 공역(codomain) 역할
-
-
선형변환의 조건 (: → )
-
가산성(Additivity) : 에 대하여
-
동차성(Homogeneity) : 에 대하여
-
4. 비선형 함수(Non-linear)
딥러닝 모델의 표현력을 향상
- 선형함수만 사용한다면?
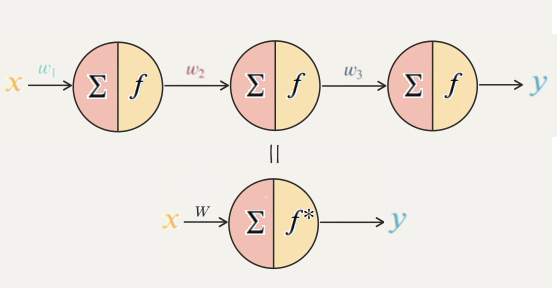
AIFFEL FUNDAMENTALS_SSAC2 23. 활성화 함수의 이해- 즉, 3개의 노드를 1개로 줄여서 표현하는 것과 같다.
5. 활성화 함수
-
활성화 함수의 종류
-
이진 계단 함수(Binary step function)
-
선형 활성화 함수(Linear activation function)
-
비선형 활성화 함수(Non-linear activation function)
-
이진 계단 함수(Binary step function)
입력이 임계점을 넘으면 1(True)를 출력, 그렇지 않으면 0 출력
이진 계단 함수의 한계
-
단층 퍼셉트론은 이 XOR gate를 구현할 수 없다 → 다층 퍼셉트론(multi-layer perceptron, MLP)로 해결
-
역전파 알고리즘(backpropagation algorithm) 사용 못함
-
다중 출력 불가
선형 활성화 함수(linear activation function)
-
다중 출력이 가능
-
다중 분류 문제 해결 가능
-
미분이 가능 → 역전파 알고리즘 사용 가능
-
비선형적 특성을 지닌 데이터를 예측하지 못함
6. 비선형 활성화 함수(non-linear activation function)
-
역전파 알고리즘 사용 가능
-
다중 출력도 가능
-
비선형 데이터 예측 가능
시그모이드 / 로지스틱
- 치역: →
시그모이드 함수의 단점
- kill the gradient
- 시그모이드 함수는 0 또는 1에서 포화(saturate)
- 0이 중심(zero-centered)이 아님
- upstream gradient의 부호에 따라 이 노드의 가중치는 모두 양의 방향으로 업데이트되거나, 모두 음의 방향으로 업데이트 → 훈련의 시간이 오래 걸림
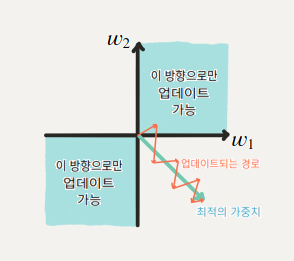
출처: AIFFEL FUNDAMENTALS_SSAC2 23. 활성화 함수의 이해
하이퍼볼릭 탄젠트(tanh, Hyperbolic tangent)
-
쌍곡선 함수
-
0을 중심으로 함
-
일반적으로 시그모이드 함수를 사용한 모델보다 더 빨리 훈련
-
단점: -1 또는 1에서 포화
ReLU(rectified linear unit)
-
최근 가장 많이 사용되고 있는 활성화 함수
-
탄젠트를 사용한 모델보다 몇 배 더 빠르게 훈련
-
비용이 높은 (예를 들면, exponential와 같은) 연산을 사용하지 않기 때문에 처리 속도가 빠름
-
ReLU는 0을 제외한 구간에서 미분이 가능
-
단점
-
출력값이 0이 중심이 아님
-
Dying ReLU
- 모델에서 ReLU를 사용한 노드가 비활성화되며 출력을 0으로만 하는 것
- 노드의 출력값과 그래디언트가 0이 되어 노드가 죽어버리는 문제 (특히 학습률(learning rate)을 크게 잡을 때 자주 발생)
-
ReLU의 단점을 극복하기 위한 시도들
Leaky ReLU
-
'Dying ReLU'를 해결하기 위한 시도
-
0을 출력하던 부분을 작은 음수값을 출력하게 만들어 주어 문제 해결
PReLU(parametric ReLU)
-
Leaky ReLU와 유사
-
새로운 파라미터를 추가하여 0 미만일 때의 '기울기'가 훈련되게 함
ELU (exponential linear unit)
-
0이 중심점이 아니었던 단점과, 'Dying ReLU'문제를 해결
-
단점: exponential 연산으로 계산 비용이 높아짐
참고 자료
Linear transformations and matrices | Chapter 3, Essence of linear algebra
