
20211101
💡Key Point💡
1. Regularization 개념 이해 및 정규화(Normalization)와 구분
2. L1 regularization, L2 regularization의 차이
3. Lp norm, Dropout, Batch Normalization에 대해 학습
1. Regularization
정칙화. 오버피팅 해결법 중 하나.
오버피팅을 방해 (train loss 증가 but validation/test loss 는 감소)
오버피팅: train set 결과는 좋고, validation/test set 결과는 안좋은 현상
2. Normalization
정규화. 적합하게 전처리하는 과정.
0과 1사이의 값으로 데이터 분포를 조정(z-score로 바꾸거나 minmax scaler 사용)
데이터 거리 간 측정이 피처 값의 범위 분포 특성에 의해 왜곡으로 인한 학습 방해 문제를 해결하기 위함
3. L1 Regularization(Lasso)
L1 norm
norm: 벡터나 행렬, 함수 등의 거리를 나타냄
-
이면 L1 norm은 로 나타낼 수 있다.
-
위 lasso 뒷쪽 수식과 일치하는 것을 볼 수 있다!
4. L2 Regularization(Ridge)
5. L1 vs L2 Regularization
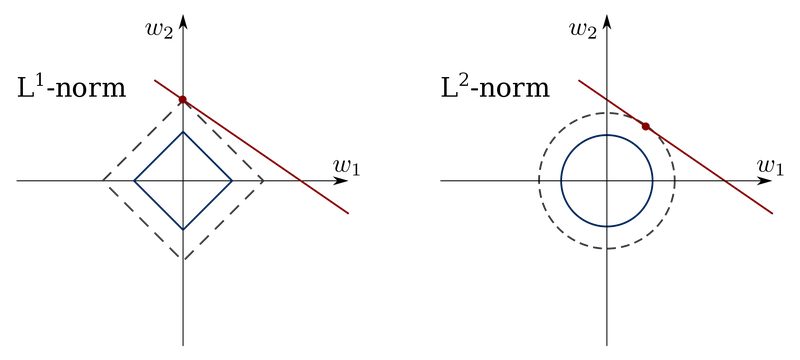
출처 : https://en.wikipedia.org/wiki/Lasso_(statistics)-
L1 Regularization
-
가중치가 적은 벡터에 해당하는 계수를 0으로 보냄
-
차원 축소와 비슷한 역할
-
를 이용 → 마름모 형태의 제약조건
-
문제가 제약조건과 만나는 지점이 해
-
일부 축에서 값을 0으로 보냄
-
-
L2 regularization
-
원의 형태로 나타남
-
0에 가깝게 (온전히 0은 X) 보냄
-
Lasso보다 수렴이 빠름
-
6. Lp norm
Norm: 벡터, 함수, 행렬에 대해 크기를 구하는 것
vector norm
Infinity norm()
matrix norm
- x 행렬
- 일 때: 컬럼의 합이 가장 큰 값 출력
- 일 때: 로우의 합이 가장 큰 값 출력
7. Dropout
정보를 모든 뉴런에 전달하지 않고 랜덤하게 버리면서 전달하는 기법
-
이전에는 fully connected architecture로 모든 뉴런 연결
-
드롭아웃 출현 이후 랜덤하게 일부 뉴럴만 선택하여 정보 전달
-
Regularization layer
-
확률이 너무 높으면 학습이 잘 되지 않고, 너무 낮으면 fully connected layer와 같음
-
fully connected layer에서 오버피팅 → Dropout layer 추가
8. Batch Normalization
gradient vanishing, explode 문제를 해결하는 방법
참고 자료
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
솔직 고백하면,,, 해당 노드는 머리에 잘 안들어온다.. 더 공부해봐야할 것 같다 ㅠㅠ
