
20211013
1. 지도학습의 종류
지도학습은 분류(classification)와 회귀(regression) 문제로 나뉜다.
분류 : 데이터의 feature 값들을 이용하여 데이터의 클래스를 추론하는 것
회귀 : 데이터의 feature 값들을 이용하여 연관된 다른 데이터 값을 추론하는 것
2. 회귀(Regression)
회귀분석(Regression Analysis): 관찰된 데이터들을 기반으로 연속형 변수 간의 관계를 모델링하고 적합도를 측정하는 분석 방법.
회귀: 단순히 평균으로 수렴하는 현상을 넘어서서, 두 개 이상의 변수 사이의 함수관계를 추구하는 통계적 방법
독립변수(independent variable): 설명변수(explanatory variable)라고도 함
종속변수(dependent variable): 반응변수(response variable)라고도 함
-
회귀분석의 예시
-
부모 자식간 키의 관계
-
자동차 스펙을 이용한 가격 예측
-
독립변수와 종속변수 사이의 상호 관련성을 규명하는 특징이 있음
-
3. 선형 회귀 분석(Linear Regression)
두 변수 사이의 관계를 직선 형태로 가정하고 분석하는 것.
종속변수와 한 개 이상의 독립변수의 선형 상관관계를 모델링.
회귀 분석의 가장 대표적인 방법.
-
선형 회귀분석의 기본 가정 (대상 변수들이 가져야 할 조건)
-
선형성
-
독립성
-
등분산성
-
정규성
-
-
선형 회귀식
-
: 회귀계수
-
: 종속 변수와 독립 변수 간 오차
-
- 선형회귀 모델을 찾는다 = 데이터에 선형식이 잘 맞도록 회귀계수 및 오차를 구하는 것
머신러닝과 선형회귀 모델
-
H: 가정(Hypothesis) -
W: 가중치(Weight) -
b: 편향(bias) -
W, b는 고차원의 행렬(matrix) 형태인 경우가 많음 -
파라미터(W)의 개수가 많을수록 모델의 크기가 커지고 학습이 어려움
-
잔차(Residuals): 추정한 값과 실제 데이터의 차이
-
최소제곱법: n 개의 데이터에 대하여 잔차의 제곱의 합을 최소로 하는
W,b를 구하는 방법≒ 손실함수(Loss function) -
결정계수: 회귀모델이 잘 결정되었는지 확인할 때 참고하는 지표
-
R-squared, R2 score
-
0~1 사이의 값
-
1에 가까울수록 데이터를 잘 표현하고 있는 것
-
경사하강법 (Gradient Descent Algorithm)
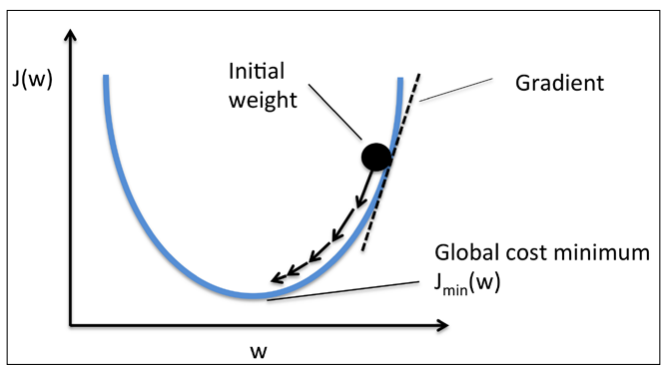
[출처 : https://lsh424.tistory.com/9]
- 그래디언트 값 업데이트
- : learning rate
4. 로지스틱 회귀분석(Logistic Regression)
로지스틱 회귀분석(Logistic Regression): 데이터가 카테고리에 속할 확률을 0에서 1 사이의 값으로 예측 → 가능성이 더 높은 범주에 속하는 것으로 분류.
-
Y값: 확률 → 하한, 상한
[0, 1] -
이진 분류문제를 풀 때 많이 사용 -
이진 분류(binary classification): 독립변수를 이용하여 데이터가 2개의 범주 중 하나에 속하도록 결정하는 것
정의 및 회귀 분석
로지스틱 회귀식을 확률을 기준으로 정리하면 sigmoid function의 형태의 로 만들 수 있다.
결론적으로 구한 Log-odds 값을 sigmoid function에 넣어서 0에서 1 사이의 값으로 변환하는 것이다.
- 종속 변수가 0일 확률:
- odds: 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값
- 로지스틱 회귀식
- 로 정리하기
- z =
중간에 exp가 들어가면서부터 이해가 잘 안됐는데 퍼실님이 설명해주셔서 1차적으로 이해하고, 다시 정리하면서 완전 이해했다!
각 식에 대한 정리 내용은 아래 참고



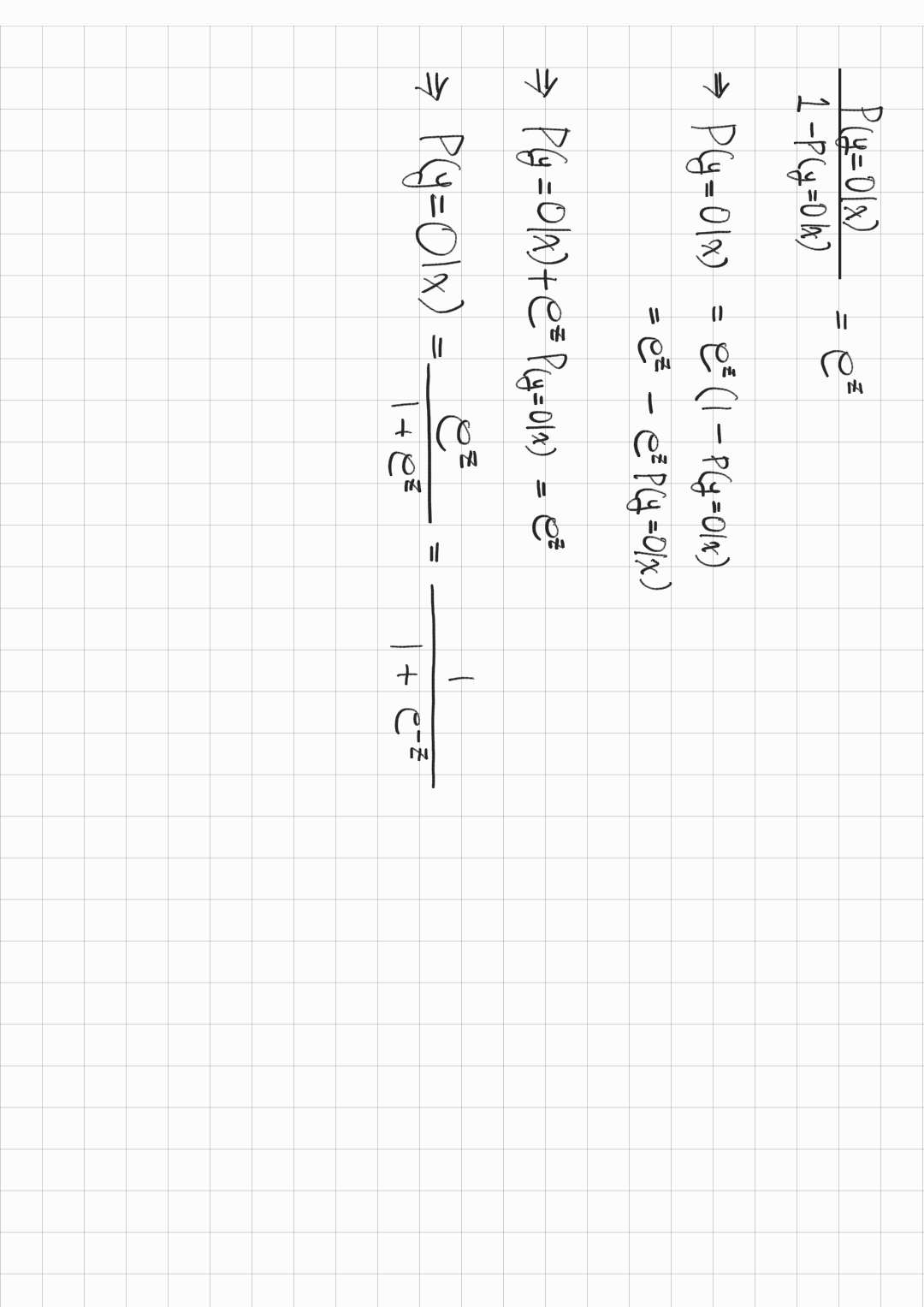
로지스틱 회귀 예측 순서
-
데이터를 대입하여 Odds, 회귀계수 구하기
-
Log-odds 값을 sigmoid function의 입력으로 넣어서 특정 범주에 속할 확률 계산
-
설정한 threshold에 맞추어 이진 분류를 수행(설정값 이상이면 1, 이하면 0)
5. Softmax
여러 범주로 분류하는 함수.
Multi class classification에 적합
-
확률 값이 0에서 1 사이의 값
-
모든 softmax의 값을 더했을 때 그 합은 1
-
큰 log-odds와 작은 log-odds의 차이를 극대화
-
one-hot encoding을 통해 표현(가장 큰 값을 1, 나머지 값들은 0으로 인코딩)
6. Cross Entropy
softmax 함수의 손실함수.
q(x)와 p(x)의 차이를 계산한 것.
차이가 적을수록 Cross entropy가 작아짐
-
H(p,q)의 값이 감소하게 되는 방향으로 가중치 학습
-
p(x): 실제 데이터의 범주 값
-
q(x): softmax의 결과 값
7. 요약
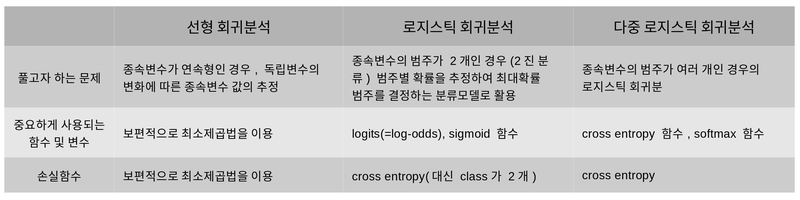
AIFFEL Fundamentals_ssac2 16. 선형 회귀와 로지스틱 회귀
추가 학습 자료
