
20211008
lms를 시작하기 전에 매번 퍼실님이 노드 이해를 돕기 위한 사전 지식에 대한 내용을 정리해주신다.
그리고 그 전에 배웠던 내용들에 대한 질문을 많이 해주시는데, 이 시간이 나의 현재 상태를 잘 깨닫게 한다.
결론적으로 나는 아는게 없다.
자기 비하가 아니라 객관적인 내 상태가 그러하다...
뭔가 한 번에 많은 지식을 받아들이지 못하고 그냥 끌어 안고 있는 기분이다.
앞으로의 공부 방법에 대해 다시 생각해볼 필요가 있겠다고 은연 중에 생각은 했지만,, 오늘을 기점으로 확실해졌다.
나는 변화가 필요하다 ..!
추가적으로 무언가를 공부할게 아니고 이전에 학습한 것을 다시 볼 필요가 있을 것 같다.
계속 새로운 것을 한다는 것은 모래 위에 성을 쌓는 것 같을 듯 하다😥
아무튼 이번 연휴동안 고민을 좀 해봐야겠다.
짧은 회고 아닌 회고 끝. 공부해야지..🤪
1. 신경망의 구성
신경망(Neural Network): 뉴런들이 복잡하게 얽혀있는 그물망과 같은 형태를 이루는 것을 밀한다.
인공신경망(Artificial Neural Network): 각 퍼셉트론(Perceptron)들을 연결한 형태
다층 퍼셉트론(Multi-Layer Perceptron; MLP)
- 예시 (3개의 레이어로 구성된 퍼셉트론)
- 은닉층에 H개의 노드가 있다.
- 출력층에는 K개의 노드가 있다.
+1은 bias
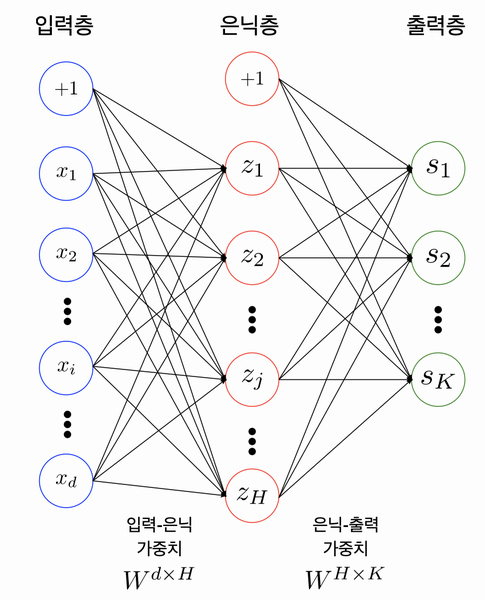
출처: AIFFEL Fundamentals 15. 딥러닝 들여다보기입력층(input layer)
은닉층(hidden layer): 입력층과 출력층 사이에 존재하는 층
출력층(output layer): 최종 출력값이 있는 층
Fully-Connnected Nerual Network: 인접한 층에 위치한 노드들 간의 연결만 존재한다는 의미 (다른 층에 위치한 노드간엔 연결 관계 존재하지 않음)
인공 신경망을 표현할 때 노드를 기준으로 레이어를 표시하기 때문에 3개의 레이어라고 생각할 수 있다.
하지만, 실제로는 2개의 레이어를 가진 것이며, 레이어 수를 확인할 때는 노드간 연결하는 부분의 수를 확인하는 것이 좋다.
Parameters/Weights
각 층 사이에 존재하는 행렬.
Weight와 Parameter는 거의 같은 뜻으로 사용되나, 엄밀히 따지면 Parameter에는 bias 노드가 포함된다.
- 인접한 레이어들간의 관계
2. 활성화 함수 (Activation Functions)
활성화 함수는 보통 비선형 함수를 사용한다.
사용하면 모델의 표현력이 좋아지게 된다.
(비선형 함수가 포함되지 않으면 한 개의 레이어로 이루어진 모델과 크게 다른 점이 없다)
Sigmoid
이전에는 많이 사용하였으나, vanishing gradient 현상과 exp 함수 사용으로 비용이 큰 문제로 인하여 현재는 잘 사용하지 않는다.
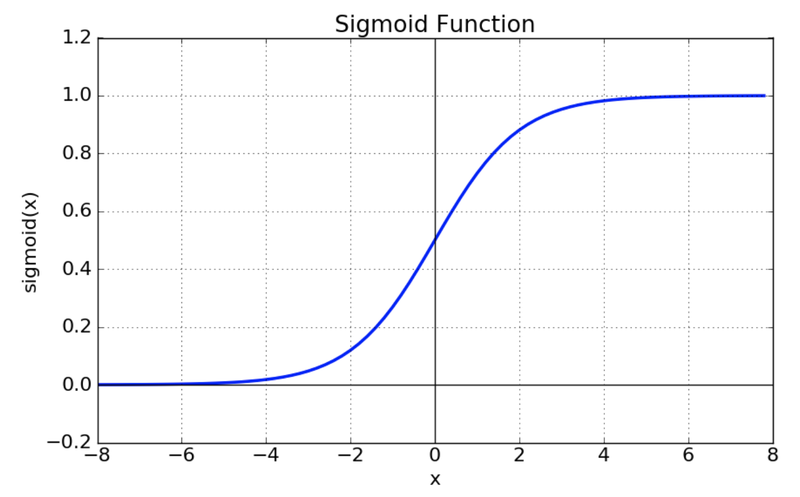
출처 : https://reniew.github.io/12/
Tanh
중심값을 0으로 옮김(sigmoid의 최적화 과정이 느려지는 문제 해결)
하지만 여전히 vanishing gradient 문제 존재
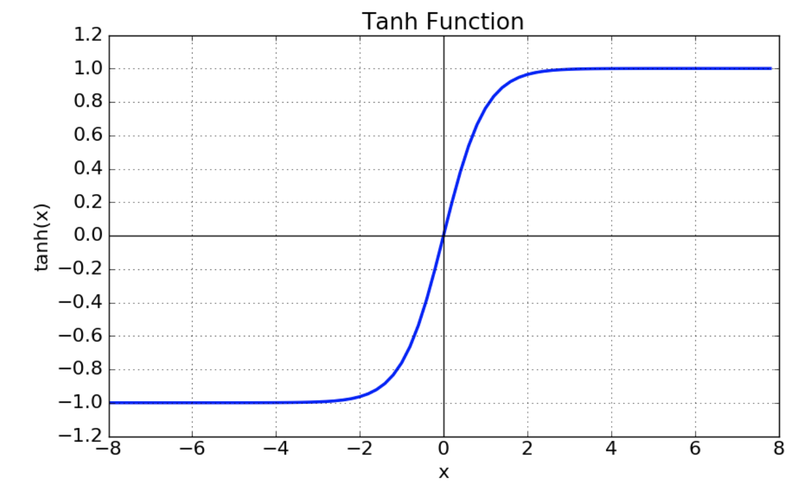
출처 : https://reniew.github.io/12/
ReLU
sigmoid, tanh 함수에 비해 학습이 빠르다.
연산 비용이 크지 않으며, 간단하게 구현할 수 있다.
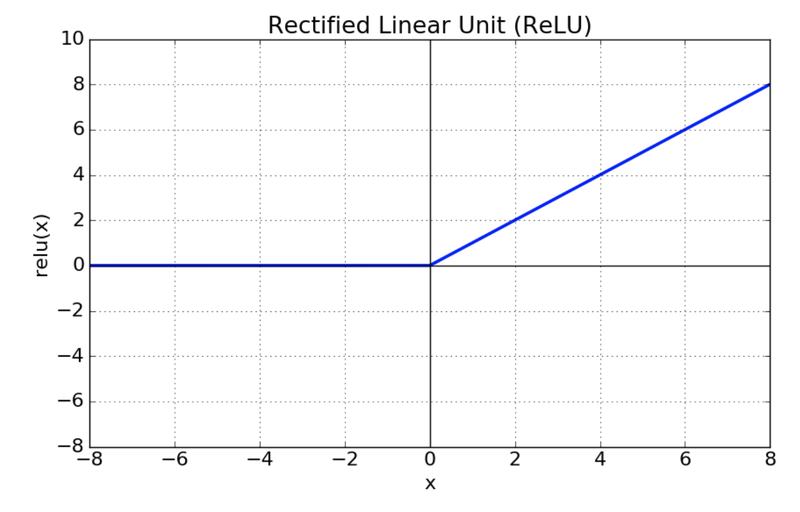
3. 손실함수 (Loss Functions)
정답과 전달된 신호 정보들 사이의 차이를 계산
평균 제곱 오차 (MSE: Mean Square Error)
교차 엔트로피 (Cross Entropy)
두 확률분포 사이 유사도가 클수록 작아지는 값
4. 경사하강법(Gradient Descent)
단계별 기울기를 구해 해당하는 기울기가 가리키는 방향으로 이동하는 방법
오차 기울기가 커지는 방향의 반대 방향으로 파라미터를 조정
학습률(learning rate)
- 산에서 내려올 때 발걸음 폭과 같은 역할
- 기울기 값과 learning rate를 곱한 값만큼 걷는 것
- parameter의 값들을 어떻게 초기화하는지와 관련되어 있다.
5. 오차역전파법(Backpropagation)
MLP를 학습시키기 위한 일반적인 알고리즘.
loss 값(출력층의 결과와 target값 차이)을 각 레이어들을 지나 역전파하며 각 노드가 가진 변수들을 갱신하는 것.
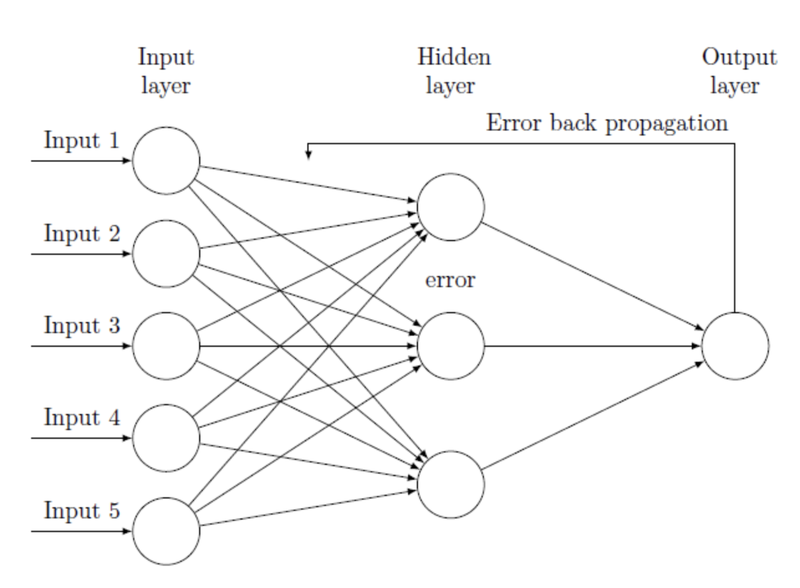
출처: AIFFEL Fundamentals 15. 딥러닝 들여다보기
추가 자료
What is the role of the bias in neural networks?
Why must a nonlinear activation function be used in a backpropagation neural network?
Understanding different Loss Functions for Neural Networks
[ ML ] 모두를 위한 TensorFlow (3) Gradient descent algorithm 기본
[머신러닝] lec 7-1 : 학습 Learning rate, Overfitting, 그리고 일반화
가중치 초기화 (Weight Initialization)
Classification and Loss Evaluation - Softmax and Cross Entropy Loss
