
20211006
Lecture 5 | Convolutional neural networks
앞부분은 CNN에 대한 히스토리를 설명해서 따로 필기하진 않았다.
1. Convolution Layer
이전에는 input image를 늘려서 wx에 넣었으나, 이 방법에는 문제(예. 말 머리 2개가 나오는 현상)가 있어서 방법을 변경하였다.


-
Convolve filter
-
input 이미지의 특징을 뽑음
-
input 이미지와 filter의 depth는 같아야 함 (위 이미지에서는 3)
-
convolve filter를 거치면 하나의 activation map이 나옴 (하나의 층)
-
한 이미지에 필터를 여러개 사용하면 필터의 수만큼 activation map(층)이 쌓임
-
쌓인 필터의 수 = depth
-
위 방법을 반복해나감 → 이미지의 특징을 계속해서 추출해냄(점점 상세해짐)
-
2. filter 적용 과정

N: input size (N x N)
F: filter size (F x F)
stride: 옆으로 이동하는 값
+1: bias
output size가 정수로 떨어지지 않으면 안된다.
같은 부분이어도 필터가 다르면 다른 특징을 뽑아낸다.
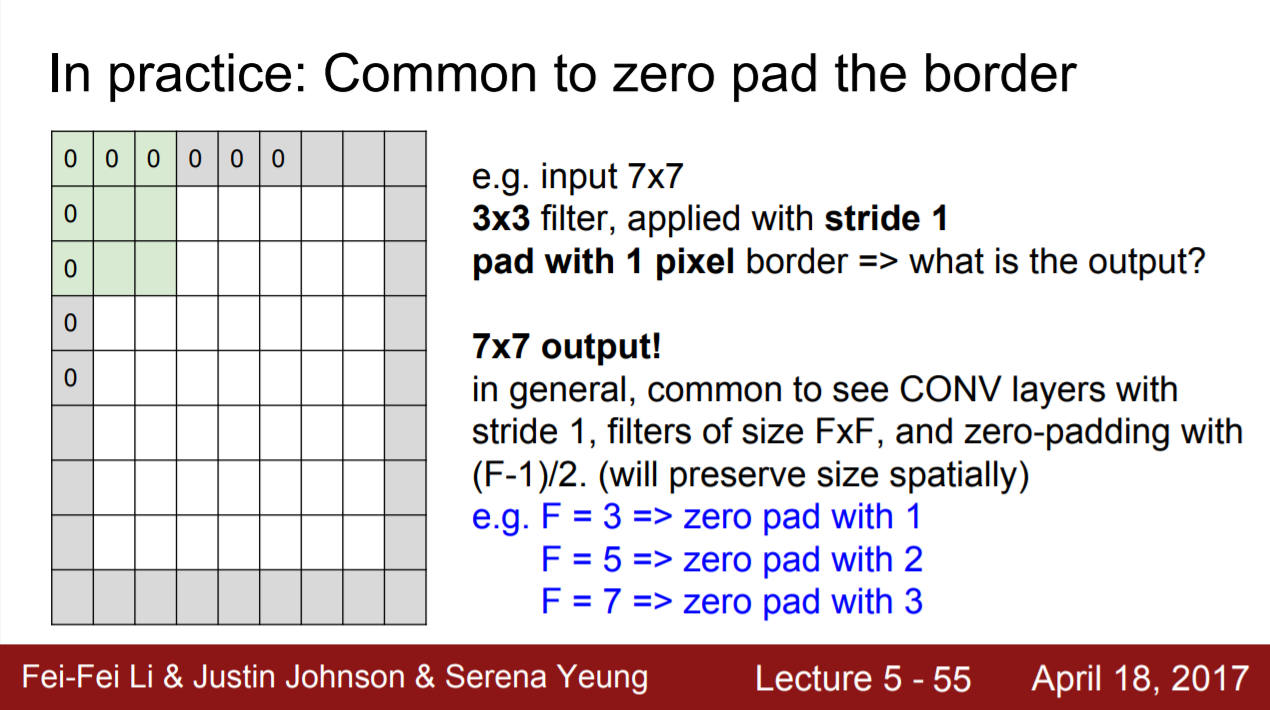
3. zero-padding
전체 사이드에 0값을 둘러주는 것.
padding을 통해 이미지가 급격하게 줄어드는 것을 방지할 수 있음
-
이미지는 stride를 거칠수록 사이즈가 작아짐
-
이미지의 크기가 급격히 작아지면 낮은 층에서도 이미지가 소멸될 수 있음
-
이미지의 사이드 부분은 안쪽 부분에 비해 필터가 적용되는 횟수가 적음
-
필터 사이즈에 따른 일반적인 zero pad 적용
-
filter 3 → zero pad 1겹
-
filter 5 → zero pad 2겹
-
filter 7 → zero pad 3겹
-
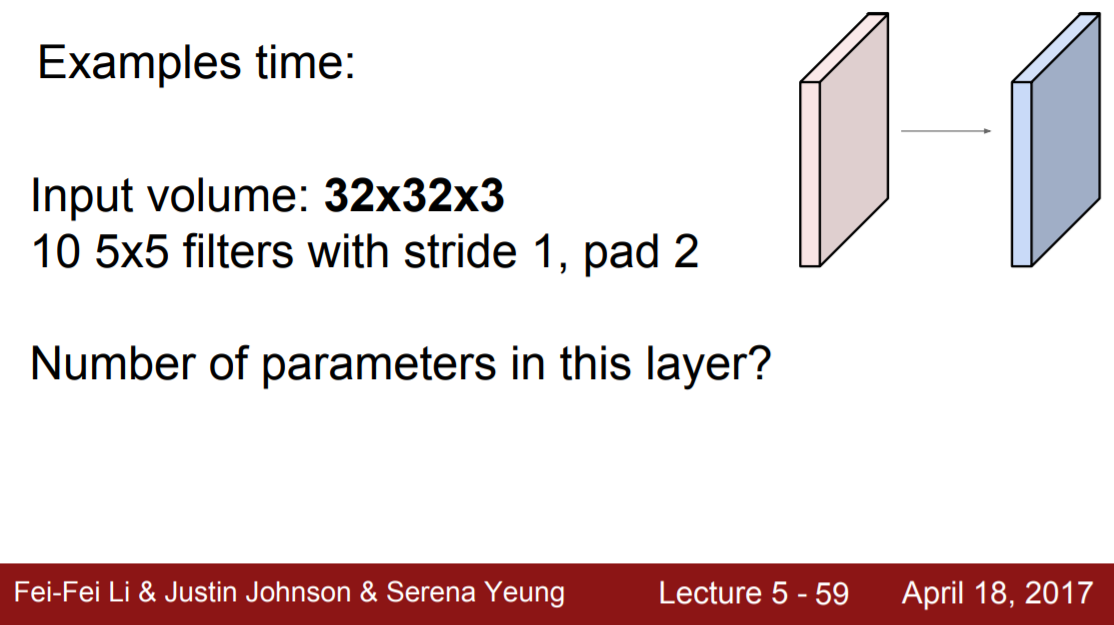
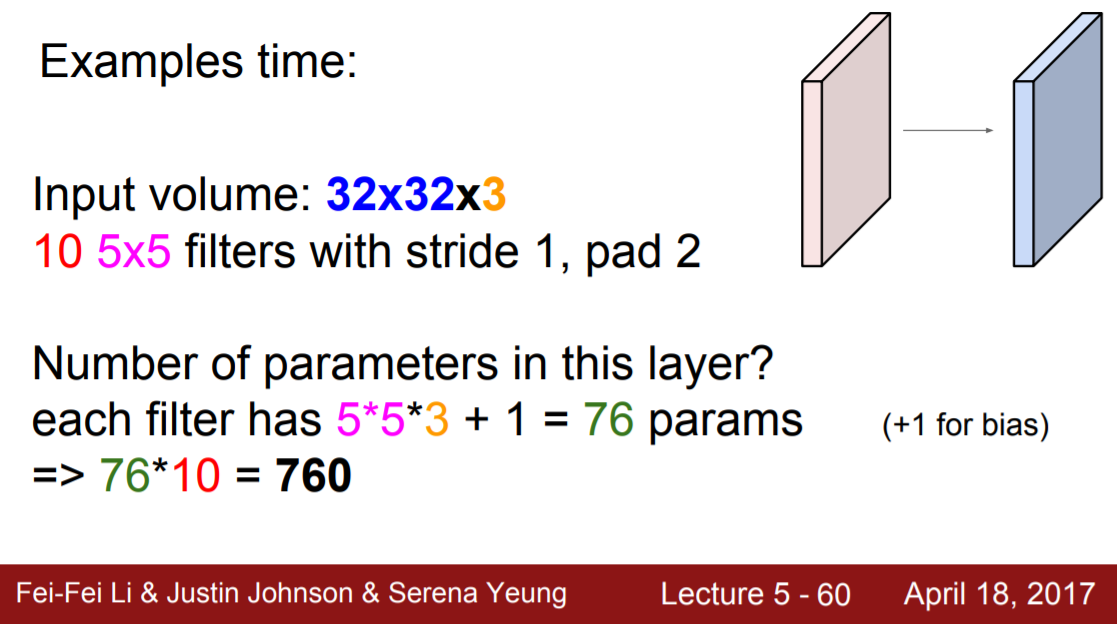
예시 문제 풀어보기
- 파라미터 개수 구하기

4. Max pooling
pooling: 큰 특징 값은 유지하면서 이미지 사이즈를 줄여 나가는 것

max pooling은 큰 특징 값들을 뽑아내고 나머지는 버린다(stride X).
5. Summary

마무리
점점 CS231n 정리글에 슬라이드 사진이 많아진다..
대충 쓰는게 아니라 그림이 없으면 이해하기 어려울 것 같아서 함께 올린다 !
확실히 글쓰면서 정리할 때도 그림이 있으니까 더 잘 떠오르는 것 같다.
