
20211001
Lecture 4 | Backpropagation and neural networks
1. 오차역전파(Backpropagation)
결과 값을 통해서 다시 역으로 input 방향으로 오차를 다시 보내며 가중치를 재업데이트 하는 것
예시 1

-
그래프의 뒤에서 부터 본다.
-
x, y, z가 각각 f에 미치는 영향 :
-
덧셈 연산에서 미분은 1, 곱셈 연산에서는 서로의 값을 가지게 된다.
-
각 값이 최종 f에 영향을 미치는 정도를 파악하기 위해 gradient를 계산(위 슬라이드)
-
F → f: 1
-
z → f: q (q는 x+y 이므로 3)
-
q → f: z
-
y → f: → ( y→ q → f) → z = -4
-
x → f: chain rule 사용 → → ( x→ q → f) → z = -4 (local gradient)
- local gradient는 forward passing을 하면서 그냥 구할 수 있기 때문에 미리 값을 가지고 있는다(qz나 x+y와 같은 미리 구할 수 있는 미분 값)
-
-
앞에서 넘어온 gradient: global gradient
-
gradient = local gradient x global gradient
-
여기서 구한 gradient(global)를 뒤로 보내고 뒤에 있는 local gradient와 받은 global gradient를 곱하고 다시 구하고를 반복하여 적절한 gradient를 찾아감
예시2: 시그모이드

-
동일하게 우측부터 보기 시작한다.
-
중심 선을 기준으로 아래측이 global gradient (붉은 글씨로 표기)
-
계산 과정
-
gradient 1
-
Gg: 1, Lg: = , x = 1.37→ gradient = -0.53
-
Gg: -0.53, Lg: 1, x=0.37 → gradient = -0.53
-
Gg: -0.53, Lg: , x = -1→ gradient: - 0.20
-
Gg: -0.20, Lg: -1 → gradient: 0.20
-
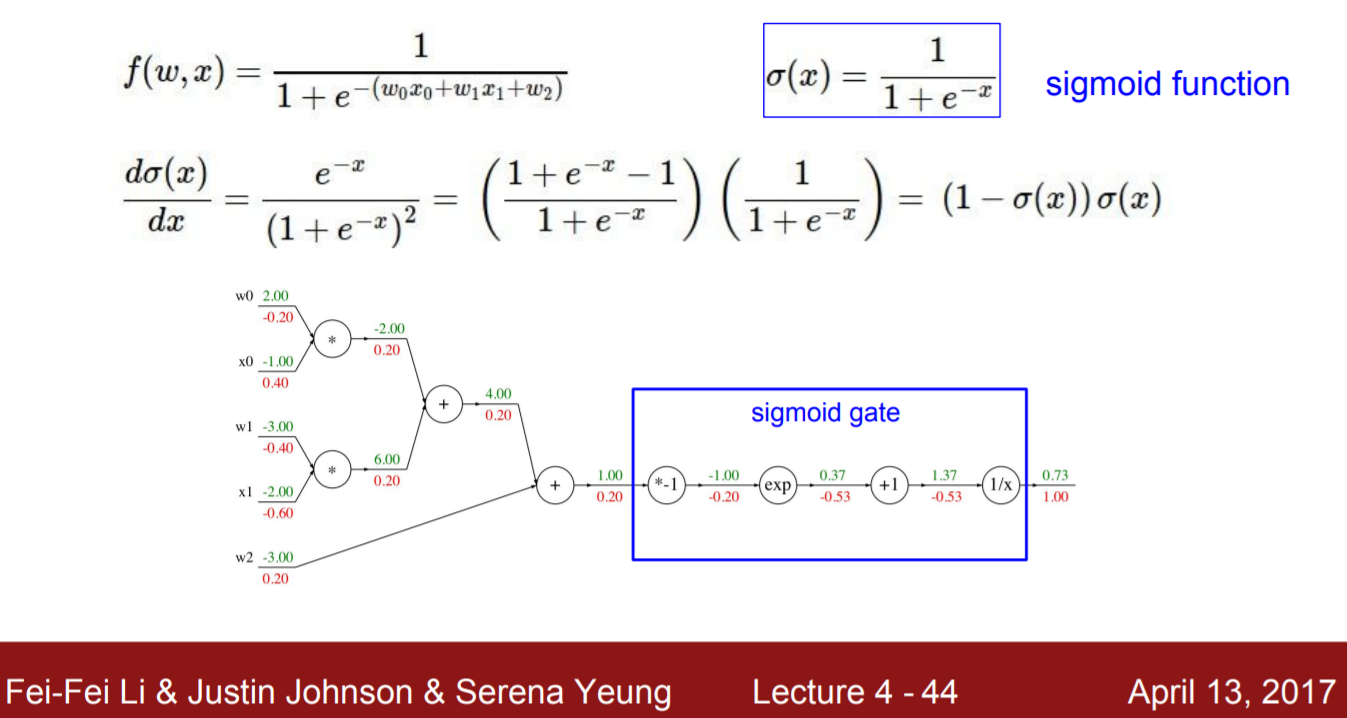
위 예시를 기준으로 sigmoid 게이트가 들어가기 전 gradient 는 시그모이드 값인 0.73을 기준으로 (1-0.73)(0.73)으로 구할 수 있다.
Pattern in backward flow
-
add gate: gradient distributor
-
local gradient가 1이다.
-
global gradient * local gradient를 하면 global gradient가 나온다
-
(
distributor로 불림 → gradient를 전달해주는 역할이라서)
-
- max gate: gradient router
- 큰 값에게 gradient를 그대로 전하고 작은 값은 0으로 만들어서 보낸다.
- mul gate: gradient switcher
- 서로의 값을 교환함
- 만약 앞에서 온 gradient가 복수라면 복수의 gradient를 더해줌
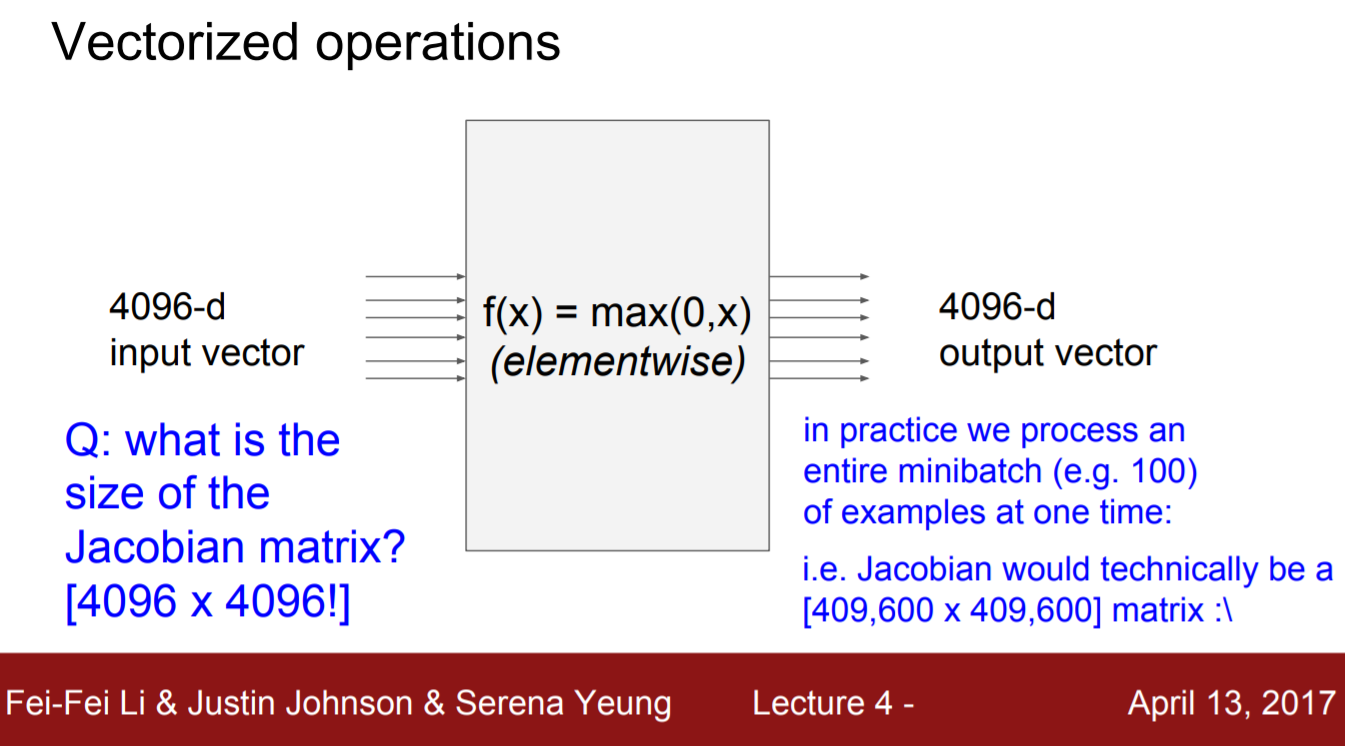
Jacobian matrix
다변수 함수 일 때의 미분값을 행렬로 표현한 것
-
jacobian matrix의 활용
- input이 d차원의 벡터가 들어감 → output도 d차원
-
jacobian matrix의 크기
-
input이 4096이고 output이 4096이라면 4096x 4096
-
minibatch를 추가하면 그 수를 곱함
ex) minibatch:100 → 409600x409600
-
-
실제로는 자코비안 행렬을 계산하지 않음(전체 자코비안 행렬을 작성하고 공식화할 필요 X)
-
요소별로 보기 때문에 입력의 각 요소 즉 첫번째 차원은 오직 출력의 해당 요소에만 영향을 준다→ 이 때문에 자코비안 행렬은 대각행렬이 됨
2. Neural Networks

입력층과 출력층 사이에 있는 은닉층(h)는 하나의 분류기라고 생각할 수 있다.
즉, 히든 노드의 개수 = 서로 다른 분류기의 개수로 생각해볼 수 있다.
실제 생물학적 뉴런과 뉴럴 네트워크는 같다고 볼 수 없다 (많은 차이가 있다).
그렇기 때문에 같다고 판단해서는 안된다.
참고 자료
