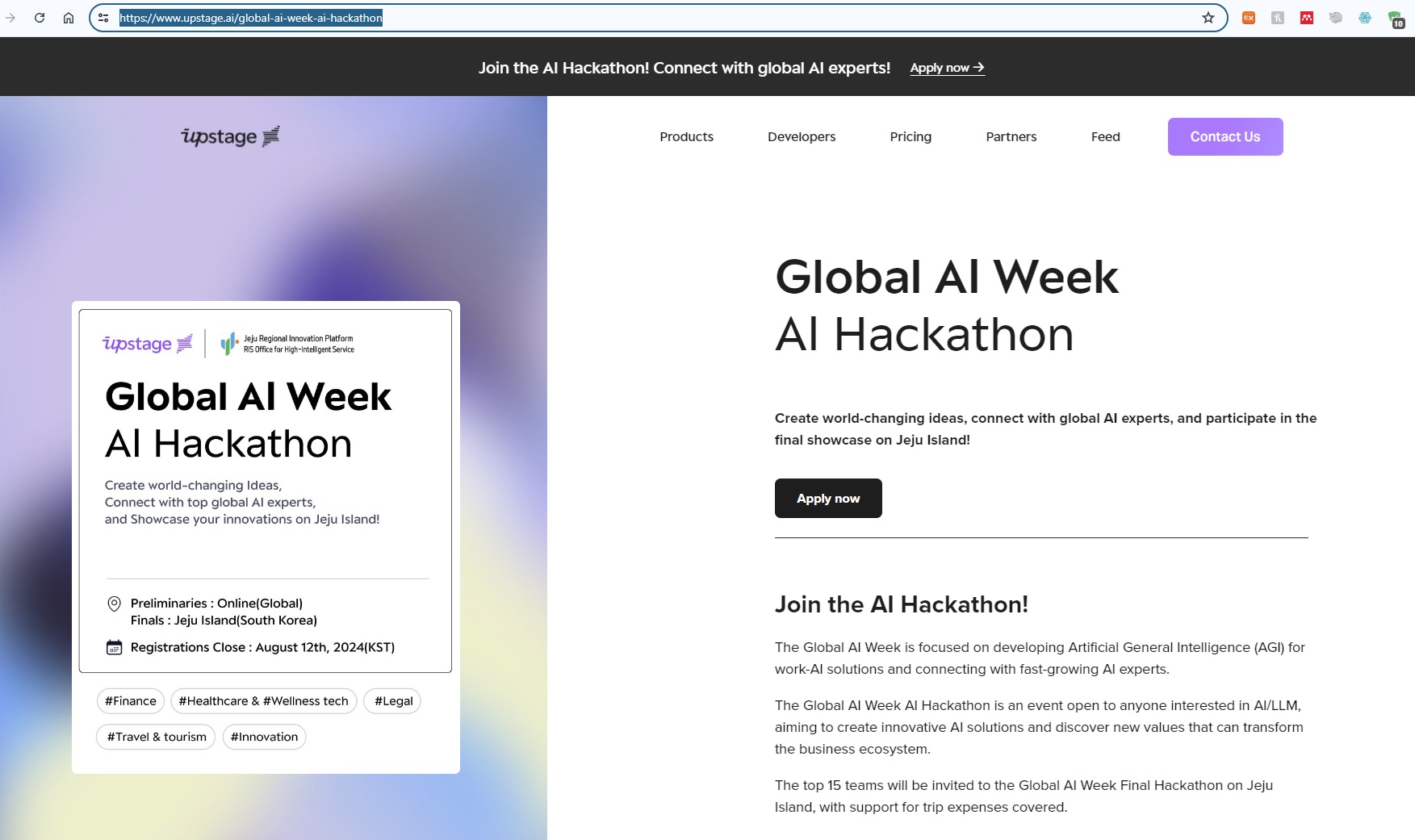
글로벌 개발자들을 위한 교류의 장, '글로벌 AI 해커톤' 결선이 9월 27일부터 3일간 제주도에서 열립니다.
학생, 프리랜서, 직장인도 참여 가능하니 아래 링크 클릭 후 신청서 작성해 주세요.
👉모집페이지: https://go.upstage.ai/4cKUquD
1. How to develop advanced data analysis app utilizing low code
log메세지는 어떻게 남겨야하고,
에러 핸들링은 어떻게 해야하고,
쿼리는 어떻게 작성해야하고,
SQL 인젝션, XSS 공격 등을 왜 막아야하고,
한정된 서버 자원을 어떻게 활용해야 할까?
로그 메시지를 남기고, 에러 핸들링, 쿼리 작성, SQL 인젝션 및 XSS 공격 방어, 서버 자원 활용에 대한 과정
1) 로그 메시지 작성:
로그는 애플리케이션의 동작 및 상태를 추적하는 데 중요합니다.
로그 레벨에 따라서 디버깅, 정보, 경고, 오류 등을 나눌 수 있습니다.
예를 들어, Python에서는 logging 모듈을 사용하여 로그를 남길 수 있습니다.
2)에러 핸들링:
예외처리를 통해 프로그램의 안정성을 높일 수 있습니다.
try, except 구문을 사용하여 예외를 처리하고, 적절한 에러 메시지를 제공합니다.
중요한 정보를 로그에 남겨 예외의 원인을 추적할 수 있습니다.
3)쿼리 작성:
데이터베이스 쿼리는 보안 측면에서도 중요합니다.
매개변수화된 쿼리를 사용하여 SQL 인젝션을 방지합니다.
ORM(Object-Relational Mapping)을 활용하여 쿼리를 더욱 안전하게 작성할 수 있습니다.
4)SQL 인젝션 및 XSS 방어:
SQL 인젝션은 입력값을 필터링하고, 매개변수화된 쿼리를 사용하여 방어합니다.
XSS 공격을 방지하기 위해 사용자 입력값을 적절히 이스케이핑하거나 필터링합니다.
웹 애플리케이션에서는 Content Security Policy (CSP)를 사용하여 외부 스크립트의 실행을 방지할 수 있습니다.
5)서버 자원 활용:
적절한 캐싱 전략을 사용하여 서버 부하를 줄입니다.
데이터베이스 인덱싱을 최적화하고, 쿼리를 튜닝하여 효율적으로 자원을 활용합니다.
필요한 경우, 서버 클러스터링이나 로드 밸런싱을 통해 자원을 확장합니다.
이러한 단계를 따르면 안전하고 효율적인 데이터 분석 애플리케이션을 개발할 수 있을 것입니다.
2. 데이터 분석 애플리케이션을 개발하는 코드
데이터 분석 애플리케이션을 개발하는 코드는 상당히 복잡하고 프로젝트에 따라 다양하다. 간단한 예제를 통해 일반적인 구조를 보자. 이 예제에서는 Python과 Flask 웹 프레임워크를 사용하여 기본적인 데이터 시각화 웹 애플리케이션을 만들어 보자.
필요한 패키지를 설치:
pip install flask pandas matplotlib
간단한 데이터 분석 애플리케이션을 만들기:
from flask import Flask, render_template
import pandas as pd
import matplotlib.pyplot as plt
from io import BytesIO
import base64
app = Flask(name)
Sample data for demonstration
data = {
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May'],
'Sales': [100, 150, 200, 120, 180]
}
Convert data to DataFrame
df = pd.DataFrame(data)
@app.route('/')
def index():
# Generate a simple bar chart
plt.bar(df['Month'], df['Sales'])
plt.title('Monthly Sales')
plt.xlabel('Month')
plt.ylabel('Sales')
# Save the plot to a BytesIO object
img = BytesIO()
plt.savefig(img, format='png')
img.seek(0)
# Encode the image to base64 for embedding in HTML
plot_url = base64.b64encode(img.getvalue()).decode()
# Render the template with the plot
return render_template('index.html', plot_url=plot_url)if name == 'main':
app.run(debug=True)
그리고 템플릿 파일 (templates/index.html)을 작성합니다:
Data Analysis App
이 코드는 간단한 Flask 애플리케이션을 만들어 데이터를 시각화한 그래프를 웹 페이지에 표시합니다. 실제 프로젝트에서는 데이터베이스와의 연동, 복잡한 분석 및 시각화, 보안 및 성능 최적화 등이 필요할 것입니다.
3. ChatGPT의 advanced data analysis
ChatGPT은 텍스트 기반의 대화 모델로, 고급 데이터 분석에 직접적으로 활용되기보다는 데이터와 관련된 자연어 처리(Natural Language Processing, NLP) 작업에 사용될 수 있습니다. 여러 분야에서 ChatGPT를 활용하여 데이터 분석에 도움을 주는 몇 가지 방법은 다음과 같습니다:
1)질문 응답 시스템:
ChatGPT를 활용하여 데이터에 관한 질문에 대한 응답을 생성할 수 있습니다. 예를 들어, "매출 데이터에서 최근 성장한 제품은 무엇인가?"와 같은 질문에 자연스러운 방식으로 응답을 생성할 수 있습니다.
2) 데이터 설명 및 해석:
ChatGPT를 사용하여 데이터의 특성, 패턴, 또는 이상치에 대한 설명을 생성할 수 있습니다. 이는 비전문가에게도 데이터 분석 결과를 쉽게 이해시키는 데 도움이 됩니다.
3) 보고서 및 문서 생성:
ChatGPT를 활용하여 데이터 분석 보고서나 문서를 작성하는 데 사용할 수 있습니다. 요약, 결과 해석, 향후 전략에 대한 제안 등을 생성할 수 있습니다.
4) 데이터 전처리 및 정제:
ChatGPT를 사용하여 데이터 전처리에 관련된 질문에 답하거나, 데이터 정제 작업에 대한 조언을 얻을 수 있습니다.
5)분석 방법 및 모델 선택:
ChatGPT를 활용하여 어떤 분석 방법이나 머신러닝 모델을 선택해야 하는지에 대한 조언을 얻을 수 있습니다.
6)쿼리 생성:
ChatGPT를 사용하여 데이터베이스 쿼리 또는 데이터 질의 언어를 생성할 수 있습니다.
그러나 ChatGPT는 전문적인 데이터 분석 도구나 머신러닝 모델의 대체물로 사용되어서는 안 됩니다. 대신, 자연어 이해와 생성 능력을 활용하여 데이터 과학자 또는 분석가가 효과적으로 작업할 수 있도록 보조 역할을 수행합니다.
4. 데이터 전처리와 정제 예제
데이터 전처리와 정제는 데이터 분석에서 매우 중요한 단계입니다. 아래는 Python과 pandas를 사용하여 간단한 데이터 전처리 및 정제 예제입니다. 이 예제에서는 특정 컬럼의 누락된 값과 이상치를 처리하는 방법을 보여줍니다.
import pandas as pd
가상의 데이터 프레임 생성
data = {
'이름': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'나이': [25, 30, None, 22, 35],
'성별': ['여', '남', '남', '여', '여'],
'평점': [4.2, 3.8, 5.0, 3.5, 4.9]
}
df = pd.DataFrame(data)
데이터 프레임 내용 출력
print("데이터프레임 내용:\n", df)
누락된 값 처리 (NaN을 평균값으로 대체)
average_age = df['나이'].mean()
df['나이'].fillna(average_age, inplace=True)
이상치 처리 (평점이 1 미만이거나 5 초과인 경우 1 또는 5로 대체)
df['평점'] = df['평점'].clip(lower=1, upper=5)
정제된 데이터프레임 출력
print("\n누락값 및 이상치 처리 후 데이터프레임:\n", df)
이 코드에서는 먼저 누락된 값(NaN)을 해당 열의 평균값으로 대체하고, 그 다음으로는 특정 조건을 충족하지 않는 이상치를 처리합니다. 이상치 처리에서는 clip 함수를 사용하여 특정 범위를 벗어나는 값을 최솟값 또는 최댓값으로 대체합니다.
이러한 전처리 단계를 통해 데이터의 일관성을 유지하고 분석에 적합한 형태로 데이터를 가공할 수 있습니다.
5.머신러닝 모델 정리
머신러닝 모델은 데이터에서 학습하여 패턴을 인식하고 예측, 분류, 군집 등의 작업을 수행하는 알고리즘입니다. 다양한 머신러닝 모델이 존재하며, 아래에 몇 가지 대표적인 머신러닝 모델을 간단히 정리해보겠습니다.
- 지도 학습 (Supervised Learning) 모델:
1) 선형 회귀 (Linear Regression):
용도: 연속적인 종속 변수를 예측하는 회귀 문제에 사용.
특징: 입력 특징과 가중치의 선형 조합을 통해 예측을 수행.
2) 로지스틱 회귀 (Logistic Regression):
용도: 이진 또는 다중 클래스 분류 문제에 사용.
특징: 시그모이드 함수를 사용하여 확률을 계산하고, 임계값에 따라 클래스를 할당.
3) 의사결정 트리 (Decision Trees):
용도: 분류 및 회귀 문제에 사용.
특징: 데이터를 기반으로 결정 규칙을 학습하고 트리 구조로 표현.
4) 랜덤 포레스트 (Random Forest):
용도: 안정적인 분류 및 회귀 성능을 위한 앙상블 모델.
특징: 여러 의사결정 트리를 구성하여 다양한 관점에서 학습하고 결과를 결합.
5)서포트 벡터 머신 (Support Vector Machines, SVM):
용도: 이진 및 다중 클래스 분류, 회귀 문제에 사용.
특징: 결정 경계와 클래스 간의 최대 마진을 찾는데 중점을 둔 모델.
- 비지도 학습 (Unsupervised Learning) 모델:
1)K-평균 군집화 (K-Means Clustering):
용도: 데이터를 K개의 클러스터로 그룹화하는 군집화에 사용.
특징: 각 데이터 포인트를 가장 가까운 중심에 할당하여 군집을 형성.
2)계층적 군집화 (Hierarchical Clustering):
용도: 계층적 구조로 데이터를 그룹화.
특징: 유사성에 따라 계층적 트리를 형성하여 클러스터를 만듦.
3)PCA (주성분 분석, Principal Component Analysis):
용도: 데이터 차원 감소 및 주요 특성 추출.
특징: 데이터의 주성분(Principal Component)을 찾아 차원을 축소.
4)자기조직화 지도 (Self-Organizing Maps, SOM):
용도: 다차원 데이터를 2D 또는 3D 그리드에 매핑하여 시각화.
특징: 인접한 유사한 데이터 포인트를 비슷한 위치에 매핑.
- 강화 학습 (Reinforcement Learning) 모델:
1)Q-Learning:
용도: 에이전트가 특정 환경에서 행동을 선택하고 보상을 받는 강화 학습 문제에 사용.
특징: Q-값을 업데이트하여 최적의 정책을 학습.
2)Deep Q Network (DQN):
용도: 딥러닝을 사용하여 Q-값을 근사화하는 강화 학습 모델.
특징: 경험 재생(replay)과 타겟 네트워크를 통한 안정성 개선.
이외에도 다양한 머신러닝 모델이 있으며, 모델의 선택은 주어진 문제에 따라 다릅니다. 또한, 딥러닝 모델들도 이미지, 텍스트, 시계열 등 다양한 데이터 유형에서 사용됩니다.
Machine learning models are algorithms that learn patterns from data and perform tasks such as prediction, classification, clustering, etc. Various machine learning models exist, and here's a brief overview of some representative ones:
- Supervised Learning Models:
Linear Regression:
Purpose: Used for predicting a continuous dependent variable in regression problems.
Features: Predictions are made by a linear combination of input features and weights.
Logistic Regression:
Purpose: Employed for binary or multiclass classification problems.
Features: Uses the sigmoid function to calculate probabilities and assigns classes based on a threshold.
Decision Trees:
Purpose: Used for both classification and regression problems.
Features: Learns decision rules based on the data and represents them in a tree structure.
Random Forest:
Purpose: Ensemble model for stable classification and regression performance.
Features: Constructs multiple decision trees, learning from diverse perspectives and combining results.
Support Vector Machines (SVM):
Purpose: Used for binary and multiclass classification, as well as regression problems.
Features: Focuses on finding the decision boundary with the maximum margin between classes.
- Unsupervised Learning Models:
K-Means Clustering:
Purpose: Groups data into K clusters.
Features: Assigns each data point to the nearest centroid, forming clusters.
Hierarchical Clustering:
Purpose: Forms a hierarchical structure while grouping data.
Features: Builds a hierarchical tree based on similarity, creating clusters.
Principal Component Analysis (PCA):
Purpose: Reduces data dimensions and extracts principal features.
Features: Identifies principal components to achieve dimensionality reduction.
Self-Organizing Maps (SOM):
Purpose: Maps multidimensional data to a 2D or 3D grid for visualization.
Features: Assigns similar data points to nearby positions on the map.
- Reinforcement Learning Models:
Q-Learning:
Purpose: Addresses reinforcement learning problems where an agent selects actions in an environment and receives rewards.
Features: Learns optimal policies by updating Q-values.
Deep Q Network (DQN):
Purpose: Applies deep learning to approximate Q-values in reinforcement learning.
Features: Improves stability through experience replay and target networks.
These are just a few examples, and the choice of a model depends on the specific problem at hand. Additionally, deep learning models are widely used for various data types, including images, text, and time series data.
5.timezone naive & non-naive
"Timezone naive"와 "timezone non-naive"는 날짜와 시간 데이터를 처리할 때 시간대(timezone) 정보의 존재 여부를 나타내는 용어입니다.
Timezone Naive (시간대 무관):
날짜와 시간 정보가 시간대를 고려하지 않고, 단순한 형태로 저장되거나 다루어지는 경우를 나타냅니다.
이러한 데이터는 어떤 특정한 지역의 시간대 정보를 갖지 않으며, 주로 로컬 시간이나 표준 시간을 기준으로 합니다.
예를 들어, "2023-12-07 12:00 PM"은 어떤 특정 지역의 시간대 정보가 없는 timezone naive한 표현입니다.
Timezone Non-Naive (시간대 관련):
날짜와 시간 정보가 특정 시간대와 연관되어 있는 경우를 나타냅니다.
이러한 데이터는 특정 지역의 시간대를 고려하여 저장되거나 처리됩니다.
예를 들어, "2023-12-07 12:00 PM UTC"는 timezone non-naive한 표현으로, 시간대 정보(여기서는 협정 세계시, UTC)가 명시되어 있습니다.
Timezone naive 데이터는 주로 간단한 응용프로그램이나 시스템에서 사용되며, 시간대 변환에 대한 고려가 필요하지 않을 때 적합합니다. 그러나 실제 다양한 지역과 관련이 있는 경우에는 timezone non-naive 데이터를 사용하여 정확한 시간 정보를 다루는 것이 중요합니다. 파이썬에서는 datetime 모듈을 사용하여 이러한 날짜 및 시간 데이터를 처리할 수 있으며, pytz 라이브러리 등을 활용하여 시간대 정보를 관리할 수 있습니다.
6.AI 회사 취업 인터뷰와 코딩 테스트 준비
AI 회사에서 취업을 원한다면, 아래의 단계와 조언을 따라가면 도움이 될 것입니다. 이 과정은 주로 채용 과정에서 기대되는 스킬과 자세한 준비에 중점을 두고 있습니다.
필수 기술 및 지식 습득:
인공지능 및 기계학습 분야에 대한 기본적인 이해와 지식을 쌓아야 합니다.
주요 머신러닝 프레임워크 및 도구들 (TensorFlow, PyTorch 등)에 익숙해지세요.
프로젝트 경험 쌓기:
개인 프로젝트나 학교, 업무 관련 프로젝트를 통해 실제로 AI를 적용해보는 경험을 쌓습니다.
GitHub 등을 통해 프로젝트 코드를 공유하면 자신의 능력을 보여줄 수 있습니다.
학업 업데이트:
최신 기술 동향을 파악하고, 필요한 경우 온라인 강의나 MOOCs를 통해 역량을 증진시킵니다.
AI 및 머신러닝 관련 분야의 논문들을 읽고 이해하려 노력하세요.
이력서 및 포트폴리오 구성:
프로젝트 경험, 학력, 기술 스택 등을 강조하는 이력서를 작성합니다.
관련된 경험과 성과를 포트폴리오로 첨부하여 실력을 입증하세요.
인터뷰 준비:
AI 회사에서는 기술적인 인터뷰와 문제 해결 능력을 측정하는 인터뷰가 흔합니다.
대표적인 주제로는 알고리즘, 자료 구조, 통계, 머신러닝 이론 등이 있습니다.
프로젝트 경험에 대한 설명과 머신러닝 관련 질문에 대한 답변을 신중하게 준비하세요.
코딩 테스트:
코딩 테스트는 주로 알고리즘과 자료 구조에 대한 것이며, LeetCode나 HackerRank와 같은 플랫폼을 통해 연습할 수 있습니다.
회사마다 다르지만, 효율적인 코드 작성 및 문제 해결 능력을 강조하는 경향이 있습니다.
기술 면접:
기술 면접에서는 주로 이론적인 부분에 대한 질문이 주어집니다.
머신러닝 모델 설계, 성능 향상, 과적합 방지 등에 대한 깊은 이해가 요구됩니다.
팀 프로젝트 경험 강조:
AI 회사에서는 팀에서 협업하는 능력이 중요합니다. 팀 프로젝트나 협업 경험을 강조하세요.
면접 전 조사:
회사의 프로젝트, 연구, 문화 등에 대한 충분한 조사를 통해 면접에 임하세요.
스스로 질문을 준비하고 회사에 대한 특별한 관심을 표현하세요.
자기소개 및 경력 설명 연습:
간결하면서 핵심적인 내용을 강조하는 자기소개와, 경력에 대한 설명에 대한 연습이 필요합니다.
위의 단계를 따라가면서 끊임없는 학습과 적극적인 태도로 AI 분야에서의 취업에 대한 기회를 높일 수 있을 것입니다.
To land a job at an AI company, follow these steps and advice, focusing on the skills and preparations often expected in the hiring process:
Acquire Essential Skills and Knowledge:
Gain a fundamental understanding of artificial intelligence and machine learning.
Familiarize yourself with major machine learning frameworks and tools such as TensorFlow and PyTorch.
Build Project Experience:
Work on personal or academic projects that involve applying AI concepts.
Share your project code on platforms like GitHub to showcase your abilities.
Stay Updated with Education:
Keep track of the latest trends in AI and machine learning.
Take online courses or MOOCs to enhance your skills if necessary.
Craft Your Resume and Portfolio:
Create a resume that highlights your project experience, education, and technical skills.
Showcase relevant experiences and achievements in a portfolio.
Prepare for Interviews:
Expect technical interviews focusing on problem-solving skills.
Be ready to discuss your project experiences and answer questions related to algorithms, data structures, statistics, and machine learning theories.
Coding Test Preparation:
Practice coding problems on platforms like LeetCode or HackerRank.
Efficient coding and problem-solving skills are often emphasized.
Technical Interview Readiness:
For technical interviews, be prepared for theoretical questions, especially related to machine learning model design, performance improvement, and overfitting prevention.
Team Project Emphasis:
Highlight experiences of collaborating in a team, as teamwork is valued in AI companies.
Discuss any team projects or collaboration experiences.
Company-Specific Research:
Research the company's projects, research work, and culture thoroughly.
Prepare questions to show your genuine interest during the interview.
Self-Introduction and Career Story Practice:
Practice a concise and impactful self-introduction and describing your career story.
Be ready to discuss your achievements and experiences in a clear and engaging manner.
Following these steps, continually learning, and maintaining a proactive attitude will increase your chances of securing a position in the AI field.
