Deep Learning, ML, Gen AI, LLM 전문성을 갖추기 위해 필요한 학습 경로와 실전 경험을 정리해 드릴게요.
1. Deep Technical Understanding of ML & DL Architectures
📌 핵심 개념 학습
- 기초 수학 및 통계: 선형대수, 미적분, 확률론, 최적화 기법 (SGD, Adam, L-BFGS 등)
- 기계학습: 지도학습, 비지도학습, 강화학습, 베이지안 학습
- 딥러닝 기본 아키텍처: CNN, RNN, LSTM, GRU, GAN, Autoencoder 등
- Transformer & LLM 구조 이해:
- Attention Mechanism (Self-Attention, Cross-Attention)
- Transformer 아키텍처 (Vaswani et al., 2017)
- GPT, BERT, T5, LLaMA, Mistral 등의 내부 구조 분석
- Scaling Laws & Sparse Models (Mixture of Experts)
📖 추천 자료
- 이론:
- "Deep Learning" - Ian Goodfellow
- "Neural Networks and Deep Learning" - Michael Nielsen (무료 온라인)
- "Dive into Deep Learning" - Aston Zhang et al. (PyTorch/TensorFlow 예제 포함)
- Transformer 원 논문: Attention Is All You Need (Vaswani et al., 2017)
- 강의:
- Stanford CS231n (CNN & Vision)
- Stanford CS224n (NLP & Transformers)
- MIT 6.S191 (Deep Learning)
2. Practical Experience with LLM & Generative AI
🛠 핵심 기술 및 실전 경험
1) 최신 모델 및 기술 스택 익히기
- LLM 모델 사용 및 분석
- OpenAI GPT-4, Meta LLaMA, Google Gemini, Mistral, Falcon, Claude 등의 아키텍처 및 특징 비교
- 모델 훈련 및 미세 조정
- LoRA (Low-Rank Adaptation), QLoRA
- PEFT (Parameter-Efficient Fine-Tuning)
- Instruction Fine-Tuning & RLHF (Reinforcement Learning with Human Feedback)
- Multi-modal LLM (CLIP, Flamingo, Kosmos-1 등)
- 최적화 기법
- Zero Redundancy Optimizer (ZeRO)
- FlashAttention, xFormers
- Efficient Transformer Variants (Linformer, Performer 등)
2) 고급 프롬프트 엔지니어링
- Tree-of-Thoughts (ToT): 체계적 사고 과정을 모델에 학습시키는 기법
- Chain-of-Thought (CoT) Prompting: 단계별 추론 강화를 위한 기법
- Self-Consistency: 다양한 답변을 생성한 후 다수결 방식으로 최적화
- Retrieval-Augmented Generation (RAG): 외부 지식 검색을 활용한 모델 성능 향상
3) 실전 프로젝트 경험
- Colab & Kaggle을 활용한 미니 프로젝트
- 🤖 LLM 미세 조정: Hugging Face Transformers + LoRA 사용
- 🏥 의료 AI 프로젝트: 환자 기록 요약, 임상 문서 자동화
- 📚 Retrieval-Augmented Generation (RAG) 구축: FAISS/ChromaDB로 지식 검색 최적화
3. 개발 및 배포 실무 역량
💻 프로그래밍 실력 강화
- Python: PyTorch, TensorFlow, JAX
- ML 라이브러리: Hugging Face Transformers, DeepSpeed, Megatron-LM
- 데이터 엔지니어링: Pandas, NumPy, PyArrow, Spark
- ML Ops & 배포:
- ONNX, TensorRT, vLLM을 활용한 최적화
- FastAPI + Docker + Kubernetes 기반 API 배포
🚀 핵심 프로젝트 경험 쌓기
- End-to-End AI 솔루션 구축:
- 데이터 수집 → LLM 미세 조정 → API 배포 → 사용자 피드백 학습 (RLHF)
- 협업 경험:
- GitHub에 프로젝트 정리 (논문 구현, 모델 미세 조정, AI 서비스 개발)
- 오픈소스 기여 (Hugging Face, DeepSpeed 등)
4. 최신 연구 동향 팔로우업
- Arxiv & 논문 읽기:
- https://arxiv.org/ (AI 관련 최신 논문)
- Papers with Code (코드가 포함된 논문 검색)
- AI 리서치 블로그:
- Hugging Face Blog, OpenAI Blog, Google DeepMind Blog
- 학회 참석:
- NeurIPS, ICML, ICLR, ACL, CVPR 논문 발표 및 튜토리얼 학습
📌 다음 단계
✅ 기초: 수학 & 딥러닝 개념 정리
✅ 실전: LLM 미세 조정, 최신 기법 실습
✅ 응용: 의료 AI, NLP, 대규모 모델 최적화 실무 경험
✅ 배포: API & 클라우드 인프라 활용
✅ 연구: 최신 논문 분석 & 오픈소스 기여
이 경로를 따라가면 GenAI & LLM 전문가로 성장할 수 있어요. 현재 어떤 부분을 더 깊이 다루고 싶은지 알려주면 맞춤형 학습 계획을 더 구체적으로 만들어줄 수 있어요! 🚀
Hugging Face의 transformers 라이브러리와 LoRA (Low-Rank Adaptation) 를 사용하여 LLM을 미세 조정하는 방법을 알려줄게요.
1. LoRA란?
LoRA(Low-Rank Adaptation)는 기존 LLM의 모든 가중치를 업데이트하는 대신, 특정 레이어에 대한 작은 추가 가중치 행렬을 학습하여 메모리 사용을 절약하는 기법이야.
✅ 장점
- 메모리 절약: GPU VRAM 사용량이 줄어듦
- 훈련 속도 향상: 적은 파라미터 업데이트로 빠르게 수렴
- 성능 유지: 기존 모델 성능을 유지하면서 적은 데이터로 적응 가능
2. 설치하기
먼저, 필요한 라이브러리를 설치하자.
pip install transformers peft datasets accelerate bitsandbytestransformers: Hugging Face의 모델 라이브러리peft: LoRA, QLoRA 등을 지원하는 라이브러리datasets: 학습용 데이터셋 로딩accelerate: 멀티-GPU 학습 최적화bitsandbytes: 8-bit / 4-bit 양자화 지원
3. LoRA를 활용한 LLM 미세 조정
1) 모델 & 데이터 준비
LoRA를 적용할 Hugging Face 모델을 불러오자.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-2-7b-chat-hf" # LLaMA-2 모델 사용
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True, # 8-bit 양자화로 메모리 절약
device_map="auto"
)💡 load_in_8bit=True: 모델을 8-bit로 로드하여 VRAM 사용을 줄임.
💡 device_map="auto": 여러 GPU를 자동으로 사용하도록 설정.
2) LoRA 설정
LoRA를 적용하기 위해 peft의 LoraConfig를 사용하자.
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16, # LoRA 랭크 (작을수록 가벼움, 클수록 성능↑)
lora_alpha=32, # Scaling factor
lora_dropout=0.05, # 드롭아웃 적용
bias="none", # LoRA에서 bias 업데이트 여부
task_type="CAUSAL_LM", # GPT 계열 모델은 "CAUSAL_LM" 사용
)
# 모델에 LoRA 적용
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 학습 가능한 파라미터 확인💡 LoRA 설정 설명
r=16: 랭크(LoRA 행렬 크기). 보통 4~64 사이에서 설정.lora_alpha=32: Scaling Factor, r의 2배 정도가 일반적.lora_dropout=0.05: Dropout을 추가해 과적합 방지.
3) 데이터셋 준비
Hugging Face의 datasets 라이브러리로 학습 데이터를 불러오자.
from datasets import load_dataset
dataset = load_dataset("Abirate/english_quotes") # 예제 데이터셋 (텍스트 데이터)
print(dataset)💡 실제 사용 예시:
- 의료 분야 →
PubMed데이터셋 - 금융 → SEC 보고서, 뉴스 데이터
4) 데이터 토크나이징
토크나이저를 사용해 데이터를 모델이 처리할 수 있는 형식으로 변환하자.
def tokenize_function(examples):
return tokenizer(examples["quote"], truncation=True, padding="max_length", max_length=128)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets["train"].shuffle(seed=42).select(range(1000)) # 데이터 샘플링💡 데이터 샘플링 이유: 작은 데이터로 빠르게 테스트하기 위해
5) 모델 학습 (Fine-Tuning)
이제 실제로 LoRA가 적용된 모델을 학습해보자.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
per_device_train_batch_size=4, # 작은 배치 사이즈 사용 (VRAM 절약)
gradient_accumulation_steps=8, # 배치 사이즈가 작을 때 효과적
warmup_steps=100,
learning_rate=2e-4, # LoRA는 일반적으로 2e-4 ~ 5e-4 사용
fp16=True, # 16-bit 연산 사용하여 속도 향상
logging_steps=10,
output_dir="./lora_llama2", # 모델 저장 경로
save_strategy="epoch",
)
trainer = Trainer(
model=model,
train_dataset=tokenized_datasets,
args=training_args,
)
trainer.train()💡 중요한 설정
per_device_train_batch_size=4: GPU 메모리를 절약하기 위해 작은 배치 사용gradient_accumulation_steps=8: 배치 크기를 늘리는 효과fp16=True: 연산 속도 향상을 위해 16-bit float 사용
6) 모델 저장
훈련이 끝난 후 LoRA 모델을 저장하자.
model.save_pretrained("lora-llama2-model")
tokenizer.save_pretrained("lora-llama2-model")4. LoRA 적용된 모델 사용하기
훈련한 모델을 로드하고 문장을 생성해보자.
from transformers import pipeline
lora_model = AutoModelForCausalLM.from_pretrained("lora-llama2-model")
lora_model.to("cuda") # GPU로 로드
pipe = pipeline("text-generation", model=lora_model, tokenizer=tokenizer)
prompt = "The future of AI is"
result = pipe(prompt, max_length=50)
print(result[0]["generated_text"])5. 최적화 & 추가 개선
✅ 추가적인 최적화 방법
- QLoRA (Quantized LoRA) 적용 → VRAM 절약
- RAG (Retrieval-Augmented Generation) 결합 → 정보 검색 최적화
- Multi-LoRA Adapters → 한 모델로 여러 작업 수행
✅ 실전 적용 분야
- 의료 AI: 환자 기록 요약
- 법률 AI: 판례 분석
- 금융 AI: 투자 전략 생성
🔹 마무리
LoRA를 사용하면 기존의 거대한 LLM을 VRAM 적게 사용하면서도 빠르게 미세 조정할 수 있어.
1. Hugging Face 모델 로드
2. LoRA 적용 (peft 라이브러리 활용)
3. 데이터셋 준비 & 토크나이징
4. 미세 조정 (Trainer 사용)
5. 모델 저장 및 테스트
이제 LLM을 직접 미세 조정해서 다양한 도메인에 적용해볼 수 있어! 🚀
추가적으로 QLoRA나 RAG 같은 고급 기법도 도전해볼래? 😃
🔹 Hugging Face + LoRA 기반 LLM 미세 조정 및 배포 가이드
기초부터 배포까지 차근차근 설명할게. 🚀
📌 1. 기초: 수학 & 딥러닝 개념 정리
1.1. 핵심 수학 개념
✅ 선형대수
- 행렬 곱셈 → 모델의 가중치 연산
- 고유값 분해 (SVD) → LoRA에서 저차원 근사 활용
- 미분 & 그래디언트 → 역전파(Backpropagation)에 활용
✅ 확률 & 통계
- 소프트맥스 (Softmax) → LLM의 출력 확률 계산
- KL Divergence → 모델의 분포 차이 측정
✅ 최적화 기법
- SGD, Adam → 모델 학습을 위한 주요 옵티마이저
- Learning Rate Scheduler → 최적의 학습 속도 조정
1.2. 딥러닝 & Transformer 핵심 개념
✅ 딥러닝 기본 개념
- 신경망 (Neural Networks) → LLM의 기본 구조
- CNN vs RNN vs Transformer 비교
✅ Transformer 이해
- Self-Attention: 문맥을 고려한 단어 처리
- Multi-Head Attention: 여러 시각에서 문맥 분석
- Positional Encoding: 문장의 순서 정보 유지
✅ LLM 훈련 과정
1. 대규모 코퍼스로 사전 훈련 (Pretraining)
2. 특화된 데이터로 미세 조정 (Fine-tuning)
3. 사용 사례에 맞게 추가 튜닝 (Instruction Fine-tuning)
📌 2. 실전: LLM 미세 조정, 최신 기법 실습
2.1. LoRA 개념 & Hugging Face 적용
✅ LoRA (Low-Rank Adaptation)
- 기존 모델의 가중치를 고정하고, 작은 적응 행렬 추가
- GPU 메모리 절약 (VRAM 소비 ↓)
✅ LoRA 적용 시나리오
- 제한된 자원에서 LLM 미세 조정
- 의료, 금융, 법률 등 도메인별 특화 튜닝
✅ Hugging Face peft 활용 예제
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
# 모델 불러오기
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, device_map="auto")
# LoRA 설정
lora_config = LoraConfig(r=16, lora_alpha=32, lora_dropout=0.05, bias="none", task_type="CAUSAL_LM")
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()2.2. 최신 미세 조정 기법 적용
✅ PEFT (Parameter Efficient Fine-Tuning) 기법
- LoRA: 기존 가중치 보존, 작은 추가 행렬 훈련
- QLoRA: 양자화를 추가하여 VRAM 더 절약
- Prefix Tuning: 프롬프트에 특정 가중치 추가
✅ 고급 프롬프트 엔지니어링
- Tree-of-Thoughts: 단계적 사고를 위한 프롬프트 설계
- Self-Consistency Decoding: 여러 번 생성 후 최적 선택
- RAG (Retrieval-Augmented Generation): 검색과 결합된 LLM
📌 3. 응용: 의료 AI, NLP, 대규모 모델 최적화 실무 경험
3.1. 의료 AI 적용 사례
✅ 임상 기록 요약
- 환자 데이터를 요약하는 LLM 튜닝
✅ 의료 챗봇
- GPT 모델을 활용한 환자 상담 AI
✅ 생물의학 논문 요약
- PubMed 논문을 요약하는 모델 구축
dataset = load_dataset("ncbi_disease")
tokenized_datasets = dataset.map(lambda x: tokenizer(x["text"]), batched=True)3.2. 대규모 모델 최적화 (Scaling LLMs)
✅ 효율적인 메모리 사용
- 8-bit, 4-bit 양자화 적용
bitsandbytes라이브러리 활용
✅ 분산 학습 & GPU 최적화
DeepSpeed,FSDP로 다중 GPU 최적화accelerate로 손쉬운 분산 학습 적용
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
per_device_train_batch_size=2, # VRAM 절약
gradient_accumulation_steps=8,
fp16=True, # 16-bit 연산 최적화
output_dir="./lora_llama2"
)📌 4. 배포: API & 클라우드 인프라 활용
4.1. LLM API로 배포 (FastAPI 활용)
✅ API 엔드포인트 설정
from fastapi import FastAPI
from transformers import pipeline
app = FastAPI()
pipe = pipeline("text-generation", model="lora-llama2-model")
@app.post("/generate")
def generate_text(prompt: str):
result = pipe(prompt, max_length=100)
return {"generated_text": result[0]["generated_text"]}✅ 실행 방법
uvicorn app:app --host 0.0.0.0 --port 80004.2. 클라우드 배포 (AWS, GCP, Azure)
✅ AWS Lambda + API Gateway
- 경량 API 배포
- Serverless 환경에서 저비용 운영
✅ Docker로 컨테이너화
FROM python:3.9
WORKDIR /app
COPY . .
RUN pip install -r requirements.txt
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]docker build -t lora-llm .
docker run -p 8000:8000 lora-llm✅ Kubernetes + KServe 활용
- 대규모 배포에 최적화
- GPU 인프라 자동 스케일링
🔹 마무리: 전체 과정 요약
1️⃣ 기초: 수학, 확률, Transformer 개념 익히기
2️⃣ 실전: Hugging Face + LoRA로 LLM 미세 조정
3️⃣ 응용: 의료 AI, NLP, 대규모 모델 최적화
4️⃣ 배포: FastAPI + Docker + 클라우드 배포
이제 LLM을 최적화 & 배포하는 전체 흐름을 익혔어!
더 깊게 들어가려면 DeepSpeed, RAG, MoE 등을 추가로 공부해보는 것도 좋아. 🚀
추가로 궁금한 점 있어? 😃
🔹 DeepSpeed, RAG, MoE 심화 학습 가이드
LoRA와 Hugging Face로 LLM 미세 조정을 배웠으니, 더 고급 기술인 DeepSpeed, RAG (Retrieval-Augmented Generation), MoE (Mixture of Experts) 를 다뤄볼게. 🚀
📌 1. DeepSpeed: 대형 모델 최적화 & 분산 학습
✅ DeepSpeed란?
- 마이크로소프트가 개발한 대규모 모델 훈련 최적화 라이브러리
- ZeRO (Zero Redundancy Optimizer) 로 메모리 사용량 절감
- 3D 병렬화 (데이터, 모델, 파이프라인) 지원
✅ DeepSpeed 적용 이점
- 100B+ 모델도 소규모 GPU 환경에서 훈련 가능
fp16,bf16지원으로 연산 속도 개선DeepSpeed-Inference로 서빙 최적화
1.1. DeepSpeed 적용 예제
🔹 DeepSpeed로 Hugging Face 모델 학습
from transformers import TrainingArguments
from deepspeed import DeepSpeedConfig
# 학습 설정
training_args = TrainingArguments(
output_dir="./deepspeed_llm",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
deepspeed="ds_config.json", # DeepSpeed 설정 적용
fp16=True,
)
# DeepSpeed 설정 파일 (ds_config.json)
ds_config = {
"train_micro_batch_size_per_gpu": 4,
"zero_optimization": {"stage": 2}, # ZeRO-2 적용
"fp16": {"enabled": True},
}
import json
with open("ds_config.json", "w") as f:
json.dump(ds_config, f)✅ 핵심 기능 요약
| 기능 | 설명 |
|------|------|
| ZeRO-2 | 옵티마이저 메모리 절감 |
| ZeRO-3 | 전체 모델 파라미터 샤딩 |
| DeepSpeed-Inference | 서빙 최적화 |
| Activation Checkpointing | VRAM 절약 |
✅ 추가 학습 포인트
DeepSpeed-Inference로 추론 속도 개선FSDP (Fully Sharded Data Parallel)와 비교 분석
📌 2. RAG (Retrieval-Augmented Generation)
✅ RAG란?
- LLM이 사전 학습된 데이터 외에 실시간 검색으로 최신 정보 활용
- 기존 LLM 대비 메모리 사용량↓, 정확도↑
FAISS,ChromaDB같은 벡터 데이터베이스 활용
✅ RAG 적용 사례
- 의료 챗봇 → 최신 연구 논문 검색 후 응답
- 법률 AI → 법률 문서에서 관련 판례 검색 후 응답
- 기업 문서 검색 → 내부 위키에서 정확한 정보 제공
2.1. RAG 적용 예제
🔹 FAISS를 활용한 문서 검색
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
# 임베딩 모델 불러오기
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 벡터 데이터베이스 구축
documents = ["LLM이란?", "RAG 개념 정리", "DeepSpeed 적용 방법"]
db = FAISS.from_texts(documents, embeddings)
# 검색 실행
query = "RAG란?"
docs = db.similarity_search(query)
print(docs[0].page_content)✅ 핵심 기능 요약
| 기능 | 설명 |
|------|------|
| FAISS | 빠른 벡터 검색 |
| ChromaDB | 오픈소스 벡터 DB |
| LangChain | 검색 기반 LLM 응답 생성 |
| Hybrid Search | 벡터 + 키워드 검색 조합 |
✅ 추가 학습 포인트
LangChain을 활용한 RAG 파이프라인 구축BM25,Dense Retrieval등 검색 기법 비교
📌 3. MoE (Mixture of Experts)
✅ MoE란?
- 여러 개의 전문가 모델을 조합하여 최적의 응답 생성
- 전체 모델이 아니라 일부 전문가(Experts)만 활성화 → 메모리 절약 & 성능 향상
- Google의
Switch Transformer, OpenAIGPT-4에도 사용
✅ MoE 적용 사례
- 다국어 모델 → 한국어, 영어, 일본어 전문가 분리
- 의료 AI → 영상 분석 전문가, 텍스트 분석 전문가 구분
- 멀티태스킹 모델 → 코드 생성, 문서 요약, 대화 모델 결합
3.1. MoE 모델 구축 예제
🔹 Hugging Face + MoE 적용
from transformers import GPT2Model, GPT2Config
# MoE 모델 설정
config = GPT2Config(
num_experts=4, # 전문가 수
num_selected_experts=2, # 한 번에 활성화되는 전문가 수
)
# 모델 불러오기
model = GPT2Model(config)
print(model)✅ 핵심 기능 요약
| 기능 | 설명 |
|------|------|
| GShard | Google의 MoE 학습 라이브러리 |
| Switch Transformer | Google의 MoE 기반 모델 |
| Sparse MoE | 일부 전문가만 활성화하여 효율 개선 |
| Expert Routing | 입력에 따라 최적 전문가 선택 |
✅ 추가 학습 포인트
- MoE와 기존 Transformer 비교 → 장점 & 단점 분석
- MoE 최적화 기술 (
Top-K Routing,Load Balancing) 적용
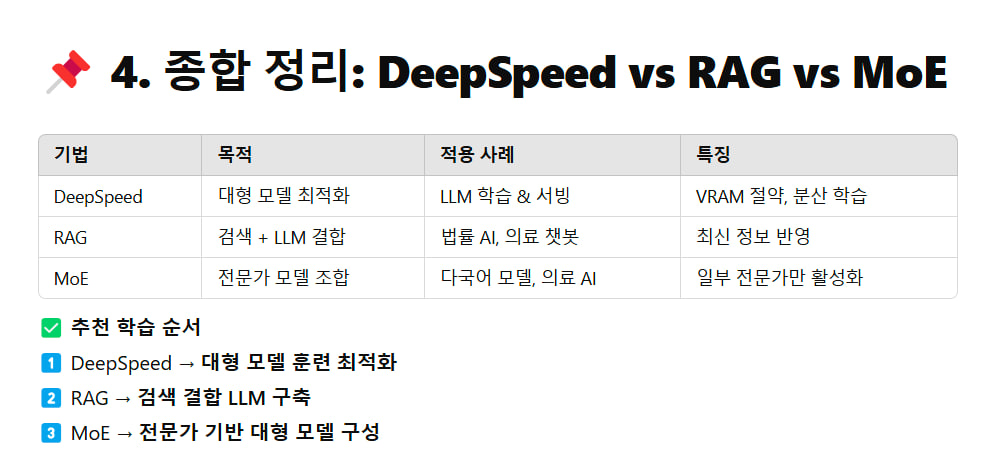
📌 4. 종합 정리: DeepSpeed vs RAG vs MoE
| 기법 | 목적 | 적용 사례 | 특징 |
|---|---|---|---|
| DeepSpeed | 대형 모델 최적화 | LLM 학습 & 서빙 | VRAM 절약, 분산 학습 |
| RAG | 검색 + LLM 결합 | 법률 AI, 의료 챗봇 | 최신 정보 반영 |
| MoE | 전문가 모델 조합 | 다국어 모델, 의료 AI | 일부 전문가만 활성화 |
✅ 추천 학습 순서
1️⃣ DeepSpeed → 대형 모델 훈련 최적화
2️⃣ RAG → 검색 결합 LLM 구축
3️⃣ MoE → 전문가 기반 대형 모델 구성
📌 5. 마무리: 실전 적용 방안
💡 DeepSpeed로 LLM을 학습하고, RAG로 검색 기능을 추가하며, MoE로 전문화된 AI 구축하기
🚀 GPU 최적화 + 실시간 검색 + 전문가 기반 AI 를 결합하면 강력한 모델이 완성됨.
✅ 실습을 위한 추천 과제
- DeepSpeed 적용해 Llama 2 미세 조정
- FAISS로 벡터 검색 + LLM 연동하여 RAG 구현
- MoE로 다국어 챗봇 (한국어/영어) 학습
이제 DeepSpeed, RAG, MoE의 핵심 개념과 실전 적용법을 익혔어!
이 중에서 어떤 걸 먼저 실습해볼까? 😃
🔹 RAG (Retrieval-Augmented Generation) 실전 가이드 🚀
LLM이 단순히 사전 학습된 데이터만으로 응답하는 것이 아니라, 실시간 검색을 통해 최신 정보를 반영하는 AI를 만들 수 있는 기법이 RAG야.
💡 주요 개념 정리
✔ LLM: 학습된 데이터에서 답변 생성
✔ RAG: 검색된 외부 데이터 + LLM 결합하여 답변 생성
✔ 벡터 데이터베이스: 문서를 벡터로 변환해 저장 & 검색
📌 1. RAG 기본 원리
1.1. RAG vs 기존 LLM 비교
| 방식 | 기존 LLM | RAG |
|---|---|---|
| 데이터 원천 | 사전 학습된 지식 | 최신 검색 정보 포함 |
| 정보 최신성 | 고정된 데이터 | 실시간 검색 반영 |
| 모델 크기 | 대형 모델 필요 | 상대적으로 작은 모델도 가능 |
💡 RAG는 미세 조정(Fine-Tuning) 없이도 LLM의 성능을 강화할 수 있음!
📌 2. RAG 구현 단계
✅ 1️⃣ 데이터 임베딩 (Embedding)
✅ 2️⃣ 벡터 데이터베이스 구축 (FAISS, ChromaDB)
✅ 3️⃣ 검색(Query) + 생성(LLM) 결합
📌 3. RAG 실습: FAISS + LangChain 활용
3.1. 라이브러리 설치
pip install transformers langchain faiss-cpu sentence-transformers3.2. 문서 임베딩 (Embedding) & 벡터 저장
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
# 문서 데이터 예제
documents = [
"Hugging Face는 자연어 처리(NLP) 라이브러리를 개발하는 회사다.",
"DeepSpeed는 대규모 모델 학습을 위한 최적화 라이브러리다.",
"RAG는 검색과 LLM을 결합한 생성 모델이다."
]
# 임베딩 모델 불러오기
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 벡터 데이터베이스 구축
vector_db = FAISS.from_texts(documents, embedding_model)
# 저장
vector_db.save_local("faiss_index")3.3. 쿼리 실행 (검색 + 응답 생성)
from langchain.chat_models import ChatOpenAI
# 벡터 DB 로드
vector_db = FAISS.load_local("faiss_index", embedding_model)
# 검색 실행
query = "RAG가 뭐야?"
retrieved_docs = vector_db.similarity_search(query)
# 가장 유사한 문서 출력
print("🔍 검색된 문서:", retrieved_docs[0].page_content)
# LLM 응답 생성 (OpenAI API 사용)
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
response = llm.predict(f"검색 결과를 기반으로 질문에 답변해줘: {retrieved_docs[0].page_content}")
print("🤖 LLM 응답:", response)✅ 실행 결과 예시
🔍 검색된 문서: RAG는 검색과 LLM을 결합한 생성 모델이다.
🤖 LLM 응답: RAG는 검색 기반 정보를 활용하여 더 정확한 답변을 생성하는 AI 모델입니다.📌 4. RAG 성능 개선 방법
1️⃣ 검색 최적화: Hybrid Search 활용
FAISS→ 벡터 기반 검색 (유사한 문장 찾기)BM25→ 키워드 기반 검색 (정확한 용어 포함 문장 찾기)- 두 가지를 조합하면 검색 성능 향상!
🔹 Hybrid Search 적용 예제
from langchain.vectorstores import Chroma
from langchain.retrievers import BM25Retriever
# BM25 기반 키워드 검색
bm25_retriever = BM25Retriever.from_texts(documents)
# FAISS 기반 벡터 검색
vector_db = FAISS.from_texts(documents, embedding_model)
# 하이브리드 검색 실행
query = "Hugging Face란?"
bm25_results = bm25_retriever.get_relevant_documents(query)
faiss_results = vector_db.similarity_search(query)
# 결과 결합
combined_results = bm25_results + faiss_results
print("🔍 Hybrid Search 결과:", [doc.page_content for doc in combined_results])2️⃣ 최신 문서 추가 & 실시간 업데이트
- 크롤링된 최신 문서를 벡터 DB에 추가하는 방법
vector_db.add_texts(["새로운 문서 내용"])실행
new_docs = ["GPT-4는 OpenAI가 개발한 대형 언어 모델이다."]
vector_db.add_texts(new_docs)3️⃣ LLM과 검색 결과 결합 최적화
💡 Prompt Engineering
- 검색된 문서를 활용하여 LLM 답변을 더 정교하게 생성
🔹 검색 결과를 Prompt에 포함
retrieved_text = " ".join([doc.page_content for doc in combined_results])
prompt = f"검색된 문서를 참고하여 질문에 답해주세요: {retrieved_text}"
response = llm.predict(prompt)
print(response)📌 5. RAG 응용 사례
✅ 1️⃣ 의료 AI 챗봇
💡 최신 연구 논문 검색 후 답변 생성
✔ 벡터 DB에 의학 논문 저장
✔ 사용자 질문과 가장 유사한 논문 검색
✔ LLM이 논문 내용을 참고하여 응답
✅ 2️⃣ 법률 AI
💡 법률 판례 검색 후 답변 생성
✔ 법률 문서를 벡터 DB에 저장
✔ 유사한 판례 검색
✔ LLM이 검색된 정보를 바탕으로 답변
✅ 3️⃣ 기업 문서 검색 AI
💡 사내 문서를 검색해 정확한 정보 제공
✔ 벡터 DB에 내부 위키 문서 저장
✔ 직원이 질문하면 LLM이 적절한 문서를 찾아 응답
📌 6. 마무리 & 다음 학습 방향
🚀 RAG 핵심 요약
✅ 벡터 DB 활용 (FAISS, ChromaDB)
✅ Hybrid Search (BM25 + FAISS)
✅ Prompt Engineering으로 응답 최적화
📌 다음으로 공부하면 좋은 것
1️⃣ DeepSpeed + RAG 결합 → 대형 모델 최적화 & 검색
2️⃣ RAG + API 배포 → FastAPI로 AI 서비스 만들기
3️⃣ LangChain + RAG 고급 응용 → 멀티모달 검색 AI
이제 직접 실습해보면 더 이해가 잘 될 거야! 어떤 부분을 더 깊이 알고 싶어? 😃
