🔹 1. 데이터 증강(Data Augmentation) 구현
데이터 증강은 모델이 더 일반화(generalize)되도록 도와주는 기술로, 이미지 데이터를 회전, 자르기, 색상 변화 등으로 인위적으로 늘리는 방법입니다.
예: PyTorch에서 CIFAR-10용 데이터 증강
from torchvision import transforms
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 무작위 자르기
transforms.RandomHorizontalFlip(), # 좌우 반전
transforms.ColorJitter(brightness=0.2, contrast=0.2), # 밝기/대비 변화
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 정규화
])🔹 2. 다중 GPU 훈련 코드 (DataParallel 또는 DistributedDataParallel)
예: PyTorch에서 DataParallel 사용
import torch
import torch.nn as nn
model = AlexNet() # 예시로 AlexNet 사용
if torch.cuda.device_count() > 1:
print("Using", torch.cuda.device_count(), "GPUs")
model = nn.DataParallel(model)
model = model.cuda()더 나은 성능을 원하면 DistributedDataParallel을 권장합니다.
🔹 3. AlexNet의 특정 레이어 분석
AlexNet은 2012년에 ImageNet 대회에서 우승한 CNN 구조입니다. 주요 특징은 큰 필터와 ReLU, 드롭아웃, 병렬 GPU 사용입니다.
예: 첫 번째 컨볼루션 레이어 분석
import torch
from torchvision.models import alexnet
model = alexnet(pretrained=True)
first_conv = model.features[0] # 첫 번째 conv layer
print(first_conv)
# 출력: Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))- 입력 채널 수: 3 (RGB)
- 출력 채널 수: 64
- 커널 크기: 11x11 (굉장히 큼)
- 스트라이드: 4 (크게 점프함 → 다운샘플링 효과 큼)
🔸 보충 설명
| 기술 | 설명 |
|---|---|
| 데이터 증강 | 과적합 방지, 데이터 다양성 확보 |
| 다중 GPU 훈련 | 대규모 데이터/모델 훈련 속도 향상 |
| AlexNet 분석 | CNN 구조의 이해 기반 제공, 비교적 단순한 구조로 학습에 적합 |
좋습니다. 아래는 요청하신 세 가지 주제에 대한 심화 설명, 코드 예시, 시각화, 비교표입니다:
✅ 1. DistributedDataParallel (DDP) 설명
🔹 개념
DistributedDataParallel (DDP)는 PyTorch에서 멀티 GPU 학습 시 가장 효율적인 방법입니다. 각 GPU에 모델의 복사본을 만들고, 각자 독립적으로 forward/backward 계산 후 gradient를 동기화(sync) 합니다.
🔹 주요 특징
- 속도:
DataParallel보다 빠름 - 스케일링: 노드 간 분산 학습 가능
- 안정성: NCCL backend 사용으로 통신 최적화
🔹 코드 예시 (1 machine, 2 GPUs)
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
def train(rank, world_size):
setup(rank, world_size)
model = AlexNet().cuda(rank)
ddp_model = DDP(model, device_ids=[rank])
# loss, optimizer 정의 후 훈련 루프 구현 가능
def run_training():
world_size = torch.cuda.device_count()
mp.spawn(train, args=(world_size,), nprocs=world_size)
run_training()✅ 2. AlexNet 전체 아키텍처 시각화
🔹 아키텍처 요약
| Layer Type | Parameters |
|---|---|
| Conv1 (ReLU) | 11x11, 96 filters, stride 4 |
| MaxPool1 | 3x3, stride 2 |
| Conv2 (ReLU) | 5x5, 256 filters |
| MaxPool2 | 3x3 |
| Conv3 (ReLU) | 3x3, 384 filters |
| Conv4 (ReLU) | 3x3, 384 filters |
| Conv5 (ReLU) | 3x3, 256 filters |
| MaxPool3 | 3x3 |
| FC1 (Dropout) | 4096 |
| FC2 (Dropout) | 4096 |
| FC3 (Output) | 1000 classes (ImageNet) |
🔹 시각화 (의사 코드)
Input: 224x224x3
↓ Conv(11x11, 96) + ReLU
↓ MaxPool(3x3)
↓ Conv(5x5, 256) + ReLU
↓ MaxPool(3x3)
↓ Conv(3x3, 384) + ReLU
↓ Conv(3x3, 384) + ReLU
↓ Conv(3x3, 256) + ReLU
↓ MaxPool(3x3)
↓ FC(4096) + Dropout
↓ FC(4096) + Dropout
↓ FC(1000)
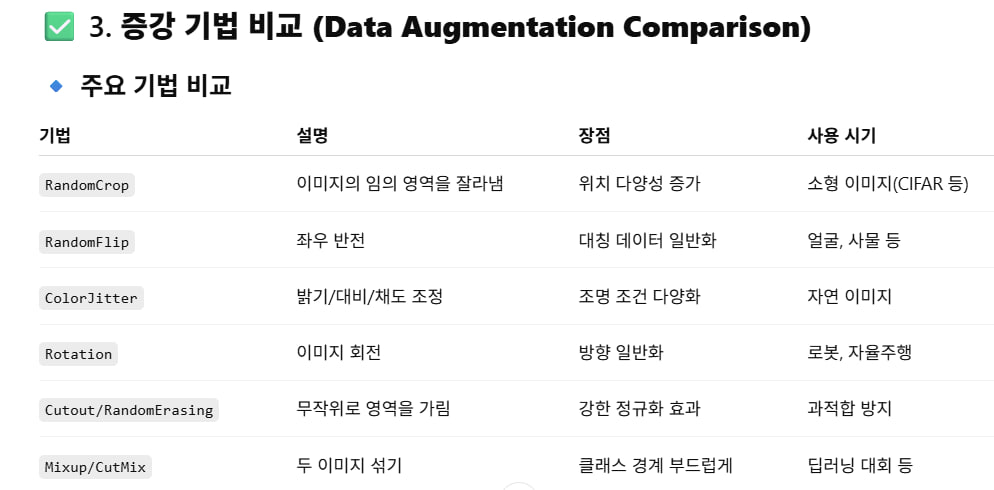
↓ Softmax✅ 3. 증강 기법 비교 (Data Augmentation Comparison)
🔹 주요 기법 비교
| 기법 | 설명 | 장점 | 사용 시기 |
|---|---|---|---|
RandomCrop | 이미지의 임의 영역을 잘라냄 | 위치 다양성 증가 | 소형 이미지(CIFAR 등) |
RandomFlip | 좌우 반전 | 대칭 데이터 일반화 | 얼굴, 사물 등 |
ColorJitter | 밝기/대비/채도 조정 | 조명 조건 다양화 | 자연 이미지 |
Rotation | 이미지 회전 | 방향 일반화 | 로봇, 자율주행 |
Cutout/RandomErasing | 무작위로 영역을 가림 | 강한 정규화 효과 | 과적합 방지 |
Mixup/CutMix | 두 이미지 섞기 | 클래스 경계 부드럽게 | 딥러닝 대회 등 |
🔹 PyTorch 예시 조합
from torchvision import transforms
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])🧠 요약 정리
| 항목 | 설명 |
|---|---|
| DDP | GPU별로 병렬 학습 수행, 빠르고 안정적 |
| AlexNet 구조 | 초기 CNN 모델로 큰 커널, 드롭아웃 사용. 8개의 레이어 구조 |
| 증강 기법 비교 | 이미지 다양성을 증가시켜 모델의 일반화 성능 향상 |

더 나은 세상은 가능하다를 믿고 실천하는 활동가