선형 회귀
데이터의 관계를 가장 잘 표현하는 직선을 어떻게 그릴 것인가
1. 단순선형
우리의 첫 번째 목표는 '기울기'를 구하는게 목표입니다.
이 기울기를 통해서 다음의 수를 '예상'할 수 있습니다. 이 기울기를 구해야하기 때문에 'y=ax+b'라는 식이 계속해서 나옵니다. 다들 중등 수학에서 이 식에 대해서 보았을 것입니다.
위의 영상이 가장 단순선형의 예시를 잘보여줍니다.
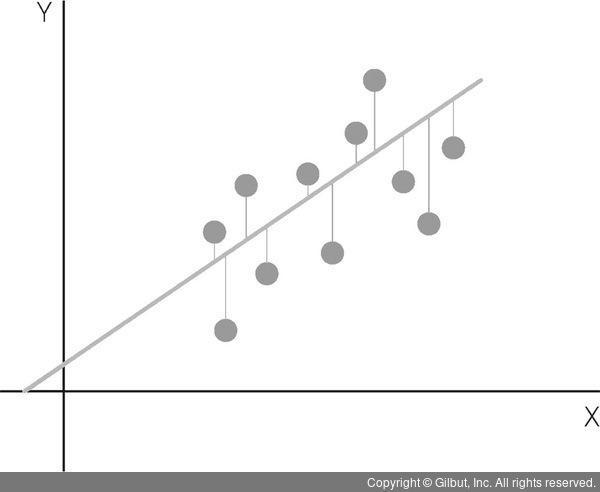
위의 영상에서 여러 선이 그어질 때 각 선마다, 각 점과 차이는 다 다를 것입니다.
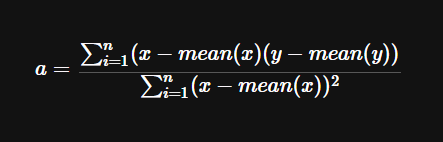
위의 식을 통해서 각 선이 그어질 떄마다, a, b를 구할 수 있습니다. a와 b가 구해진다면 다음에 올 수(y)가 무엇인지 예상하고, 다음에 숫자가 들어오면 예상한 숫자와 실제 들어온 숫자를 비교합니다.
그 비교를 잔차 제곱의 합이라고 합니다. 
식은 이렇게 됩니다. 이렇게 제곱하는 이유는 양수가 나올 수도, 음수가 나올수도 있기 때문입니다.
이식에서 데이터 샘플 수로 나눈다면 MSE(평균 제곱 오차)라고 합니다.
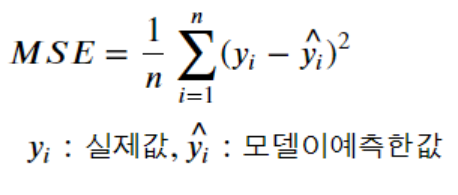
잔차가 제일 적은 y의 값이 데이터 관계를 가장 잘표현하는 직선 일 것입니다.
주어진 수와 기울기에 대해서 생각하고 그 후에, 이 기울기를 통해서 예상한 수와 실제 수를 비교함으로 오차를 찾아내는 것 이게 첫번째 입니다. 이 오차를 구하는게 핵심입니다!
2. Gradient Descent
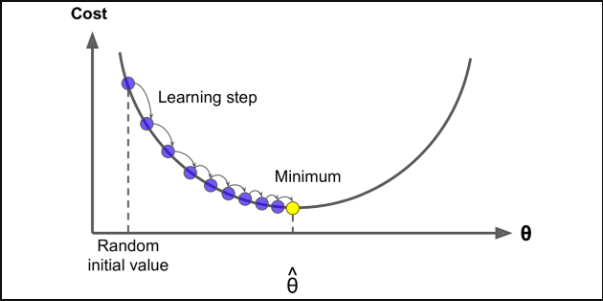
위의 MSE를 구하는 대표적 방법 중 하나는 '경사 하강법' 입니다. 위의 방법이 있음에도 이걸 사용하는 방법은 이게 계산속도가 더 빠르기 때문입니다.
함수의 기울기를 구하고 경사의 반대방향으로 계속 이동시켜 극값에 이를 때까지 반복하는 것입니다.
이렇게 함으로 오차가 작아지는 방향으로 가중치를 이동시켜 기울기가 0인 지점을 찾는 것입니다.
3. Code
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=100)
dataset = datasets.load_boston()
X, y = dataset['data'], dataset['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train) # 학습과 적용 동시에
X_test_std = scaler.transform(X_test) # 적용만
model = LinearRegression() # 선형 회귀모델 객체
model.fit(X_train_std, y_train)
train_score = model.score(X_train_std, y_train) # 점수
test_score = model.score(X_test_std, y_test)
y_predicted = model.predict(X_test_std)
number_of_sample = 40
plt.plot(range(number_of_sample), y_test[:number_of_sample], label='real target')
plt.plot(range(number_of_sample), y_predicted[:number_of_sample], label='predicted target')
plt.ylabel('price')
plt.legend()
plt.show()결과
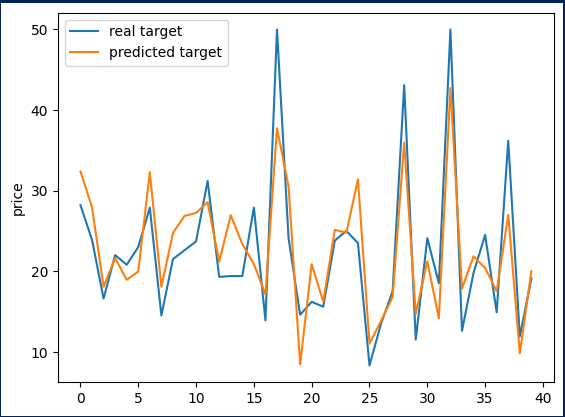
출처
https://justweon-dev.tistory.com/m/12#:~:text=%EC%84%A0%ED%98%95%20%ED%9A%8C%EA%B7%80(Linear%20Regression)%EB%9E%80,%ED%95%98%EB%8A%94%20%ED%9A%8C%EA%B7%80%EB%B6%84%EC%84%9D%20%EA%B8%B0%EB%B2%95%EC%9E%85%EB%8B%88%EB%8B%A4.&text=x%EC%99%80%20y%EC%9D%98%20%EA%B4%80%EA%B3%84,%EC%A7%81%EC%84%A0%EC%9D%84%20%EA%B7%B8%EB%A6%AC%EB%8A%94%20%EA%B2%83%EC%9D%84%20%EB%A7%90%ED%95%A9%EB%8B%88%EB%8B%A4.
https://bigdaheta.tistory.com/21
