K-NN 알고리즘 (K-Nearest Neighbor) (K-최근접이웃)
인접한 주변 데이터의 타깃 정보를 바탕으로 새로운 입력 데이터에 대한 타깃을 추론하는 알고리즘을 말합니다.
쉽게말하면 근처에 있는 데이터를 바탕으로, 해당 데이터가 어떤 데이터인지 파악하는 겁니다.
2. K-NN Regression
주변의 가장 가까운 K개의 샘플을 통해 값을 예측하는 방법을 말합니다.
코드
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
dataset = datasets.load_boston()
X, y = dataset['data'], dataset['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
# test와 train으로 분할, 자동 suffule!
scaler = StandardScaler() #표준화 객체를 학습
scaler.fit(X_train)
X_train_std = scaler.transform(X_train)
X_test_std = scaler.transform(X_test)
model = KNeighborsRegressor(n_neighbors=5)
model.fit(X_train_std, y_train) # 모델 학습
# 학습 세트에서의 결정계수와 테스트 세트에서의 결정계수를 계산
train_score = model.score(X_train_std, y_train)
test_score = model.score(X_test_std, y_test)
# 학습된 모델에 테스트 세트의 입력 데이터를 다시 넣고 타깃을 추론
y_predicted = model.predict(X_test_std)
(1) 데이터

먼저 위 데이터는 boston 집값이고 column은 그 집값에 영향을 미치는 요소를 나타낸 것입니다. Target이 집값 입니다.
(2) StandarScaler
K-NN 알고리즘 경우, 근처에 있는 데이터를 가지고 오기 때문에, 만일 근처에 있는 데이터가 차이가 많이 날 경우 값이 크게 차이가 나 잘못된 데이터를 반환할 수 있습니다.
이를 해결하기 위해서 비슷한 데이터 범위로 조정해줄 필요가 있는데 이를 데이터 스케일링 이라고합니다.
데이터에 스케일링 방법을 적용하기 위해서 StandardScaler를 사용합니다.
왜 fit을 왜 하나에만 사용할까?
fit은 머신러닝을 학습시키는 메서드입니다. 그리고 trnasform은 학습된 기계를 가지고 적용시켜 scale하는데 사용됩니다.
두 번째 데이터에도 또 fit을 한다면 별개의 기계가 만들어져서 테스트 데이터의 의미가 사라집니다. 하나의 기준을 가지고 적용시킨 각각의 데이터를 비교분석해야 의미를 가지게 되기 떄문입니다.
-
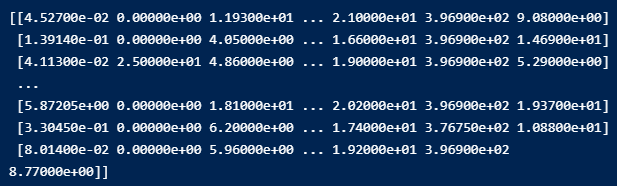
적용 전
-
적용 후
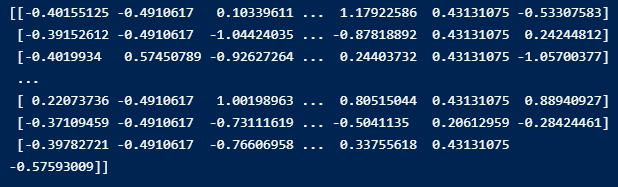
0 ~ 1로 모두 균등하게 값이 배분되었습니다.
StandardScaler() : 표준화
평균과 표춘편차를 이용해 정규분포 형태로 변환하는 걸 말합니다.(평균: 0, 분산1)
=> 각 데이터가 평균에서 얼마만큼의 표준편차만큼 떨어져있는지를 기준으로 삼게됩니다
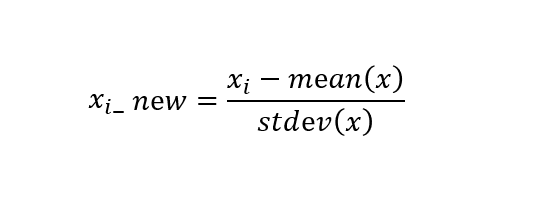
(3) KNeighbotsRegressor Class
class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, weights='uniform', algorithm='auto',
leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
-
n_neighbors : 이웃의 수를 결정합니다. default값은 5입니다
-
weights : 예측에 사용되는 가중 방법을 결정합니다.
- uniform : 각각 이웃이 모두 동일한 가중치를 갖습니다
- distance : 거리가 가까울수록 더 높은 가중치를 가져 더 큰 영향을 미치게됩니다
- 사용자가 직접 정의한 함수 사용할 수 있음
-
algorithm : 가장 가까운 이웃들을 계산하는데 사용하는 알고리즘을 결정합니다
- auto : 입력된 훈련데이터에 기반하여 가장 적절한 알고리즘을 사용
- ball_tress : Ball-Tree 구조를 사용합니다
- brute : Brute-Force 탐색을 사용합니다.
-
leaf_size : Ball-Tree나 KD-Tree의 leaf size를 결정합니다.
-
p : 민코프스키 미터법의 차수를 결정합니다.
위의 경우 인접한 5개의 데이터를 사용합니다.
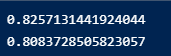
A .결정계수
훈련 시킨 후에, 결정계수를 구해 정확도를 확인합니다.

결정계수를 구하는 식입니다. 결정계수가 평균 정도를 예측한다면 0에 가까워지고, 예측이 타깃에 가까워지면 1에 가까워져 정확도를 판단합니다.
과대적합, 과소적합
- 과소적합 : 훈련 셋보다 테스트 셋의 점수가 높거나 (훈련 < 테스트) 둘다 모두 낮은 경우를 말합니다.
- 과대적합 : 훈련 셋의 점수보다 테스트 셋의 점수가 지나치게 낮은 경우를 말합니다. (훈련 >> 테스트)
(4) 결과

출처
머신러닝 & 딥러닝 입문(홍승백, 루비페이퍼)
https://rebro.kr/183
https://deepinsight.tistory.com/165
