K-평균 알고리즘(K-Means)
K-means알고리즘에서 K는 묶을 군집의 개수를 의미하고 means는 평균을 의미합니다.
각 군집의 평균을 활용해서 k개의 군집으로 묶는다는 걸 말합니다.
1.분류와 군집
-
분류 : 분류는 지도학습에 속하여, 기준이 주어졌을 때 기준을 가지고 데이터를 나누는 방법을 의미합니다. 머신러닝에서 모델을 학습시킬 때 모델이 제대로 분류하는지 평가하기위해 모델이 예측한 기준과 실제 기준을 비교하여 모델의 성능을 파악합니다. K-NN을 떠올리면 됩니다.
-
군집화 : 비지도학습 방법에 속하며 어떤 기준도 주어지지 않았을 떄 데이터를 묶는 방법을 의미합니다. 정해진 기준이 없기 떄문에 어떤 기준에 속할지 예측하기보다는 이렇게 묶일 수 있구나 파악하는데 사용됩니다.
2. 알고리즘 원리
-
- 초기 k 평균값은 데이터 개체 중에서 랜덤하게 선택됩니다.
-
- k를 중심으로 각 데이터의 개체들은 가장 가까이 있는 평균값을 기준으로 묶임
-
- k개의 군집의 각 중심점을 기준으로 평균값이 재조정
-
- k개의 군집의 각 중심점과 각 군집 내 게체들 간의 거리의 제곱 합이 최소가 될 때까지 2, 3의 과정을 반복합니다.
3. 실습
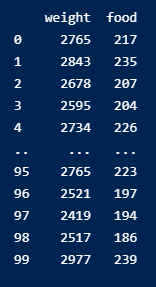
이렇게 되어있는 데이터프레임이 있다고 해봅시다.
breeds는 품종이고 weight는 무게, food는 하루 사료 섭취량입니다. 상식적으로라도 사료를 많이 먹는게 무게가 무거울 것이라고 생각할 수 있습니다.
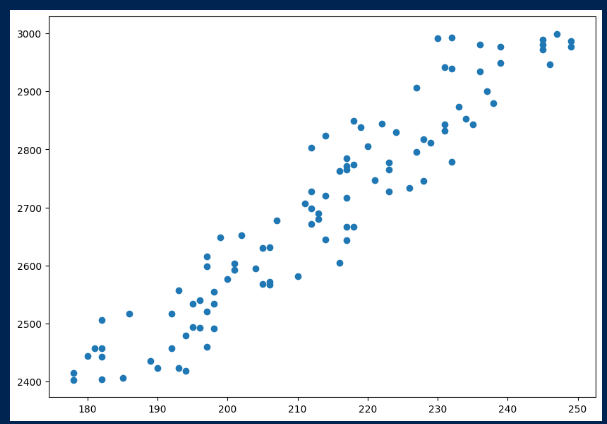
위 데이터프레임을 산점도로 나타내면 이렇습니다
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
cl = pd.read_csv('ch6-3.csv') # 데이터프레임
cl_n = cl.iloc[:, 1:3].values # weight food => 리스트화
cl_kmc = KMeans(n_clusters=3).fit(cl_n) # 학습
plt.figure(figsize=(10, 7))
plt.scatter(x=cl['food'], y=cl['weight'], c=cl_kmc.labels_)
plt.show()데이터프레임의 데이터들만 추려내어 리스트화해 사이킷런에 Kmeans를 사용합니다.
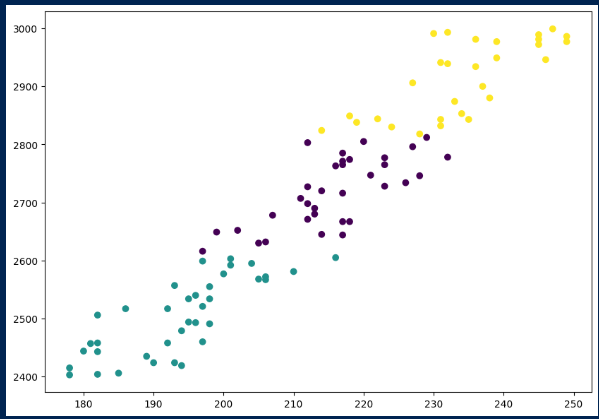
위의 것을 산점도로 나타낸 것입니다. 색깔이 3개로 나누어지면서 군집화가 된 것을 볼 수 있습니다.

읽고 기록하고 고민하고 사용하고 개발하자!