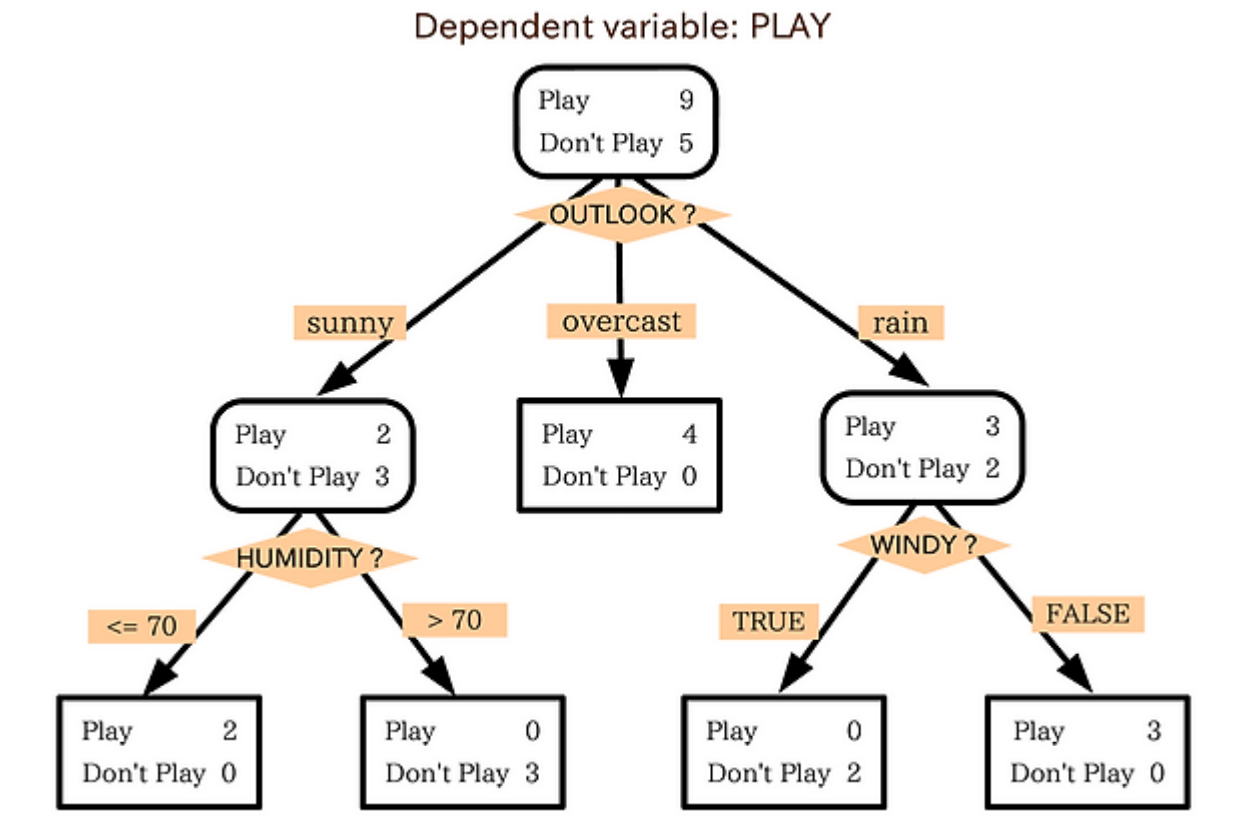
의사 결정 트리(decision tree)
의사 결정 규칙을 트리구조로 도표화하여 분류와 예측을 수행하는 분석 방법입니다.
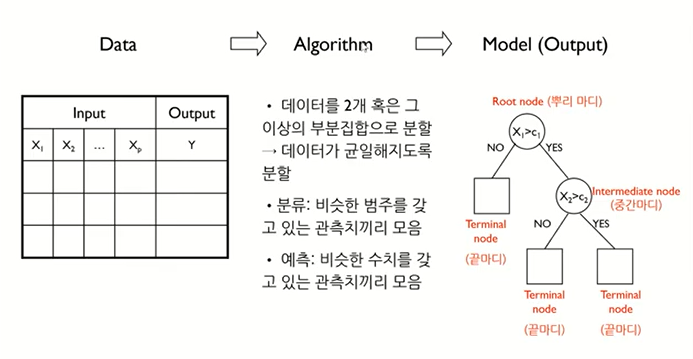
분류하는 방식은 '스무 고개'와 비슷합니다. 해당 조건에 대해 분류하고 그 다음 조건에 분류하고 이를 계속 반복하는 것입니다.
이 질문과 분류 과정을 알고리즘으로 바꿔야합니다.
이를 '재귀적 분할 알고리즘'이라고 합니다.
재귀적 분할 알고리즘에는 CART, C4.5, CHAID 등이 있습니다.
1. CART(Classification And Regression Trees)
대표적 의사결정 나무 알고리즘으로, 분류와 회귀나무 모두에 사용할 수 있습니다.
불순도를 측정할 때는 목표 변수(y)가 범주형인 경우 지니 지니수를 사용하고 이 나무는 '분류 나무'라고합니다.
연속형인 경우 분산을 사용하여 이진 분리를 합니다. 이경우는 회귀 나무라고 합니다.
(1) 분류 나무
분류나무는 영역의 순도가 증가, 불순도 불확실성이 최대한 감소하도록 학습을 진행합니다.
=> 비슷한 범주를 갖고있는 관측차들끼리 분류
이 불확실성을 지표로 엔트로피와, 지니계수 등이 있습니다. 불순도를 엔트로피로 계산하면 ID3 알고리즘이고 지니계수로 계산한 알고리즘이 CART 알고리즘입니다.
A. 지니 계수
- 0 에서 1/c의 범위를 갖습니다.

B. 엔트로피
-
엔트로피 계수는 bit의 개념을 이용해 불순도를 측정합니다.
-
0에서 1의 범위를 갖습니다.
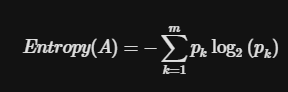
여기서 p는 전체 데이터에서 특정 데이터가 차지하는 비율을 말합니다.
맨 앞의 - 는 지수를 양수로 만들기 위해 사용됩니다.
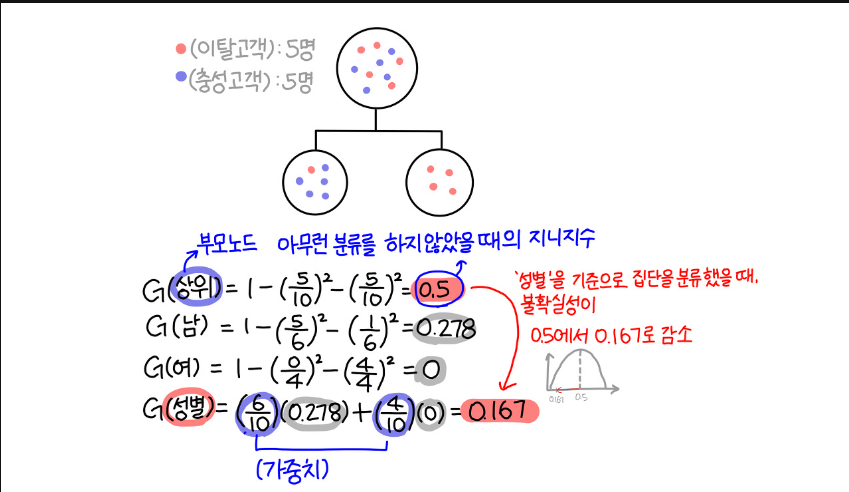
한 범주에 하나의 데이터만 있다면 불순도가 최소이고, 한 범주 안에 서로 다른 두 데이터가 정확히 반반 있다면 불순도가 최대입니다.
(2) 회귀 나무
=> 비슷한 수치를 갖고있는 관측치들끼리 분류
2. 분석 절차
(1) 의사결정나무 형성
(2) 가지치기
과적합을 막기위해 사용합니다.
-
트리의 불필요한 리프 노드를 잘라냅니다
-
재사용 가능한 설명변수의 개수 제한(max_depth)
-
관측값의 최소갯수 제한(minbucket)
오분류된 데이터 수가 minbucket으로 설정해 놓은 값보다 클 경우, 트리가 더 세분화되어 하위 트리로 분리될 수 있습니다.
(3) 최적 Tree 분류
(4) 해석 및 예측
3. 코드
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier , plot_tree
import matplotlib.pyplot as plt
dataset = datasets.load_iris()
X, y = dataset['data'], dataset['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(train_score)
print(test_score)
plot_tree(model)
plt.show()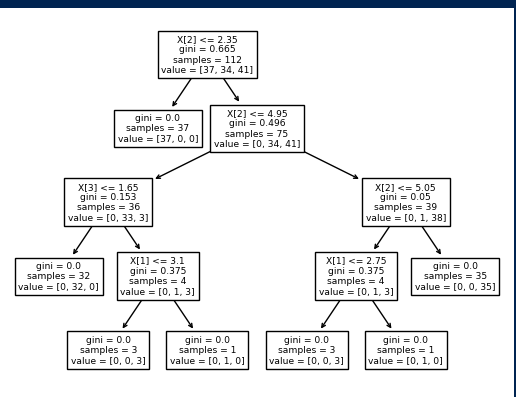
출처
https://bigdaheta.tistory.com/28
https://bluenoa.tistory.com/52
https://todayisbetterthanyesterday.tistory.com/38
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gdpresent&logNo=221717260869
