학습 데이터 뿐만 아니라 평가용 데이터도 중요한 이유
지난번 문서 분류 모델 중 텍스트 감성평가 모델을 예시로
데이터 형태를 100,000 쌍을 가지고 있다고 하자
("재밌어",1)
("재미없어",0)
("배우가 연기를 잘해",1)
("배우가 연기를 못해",0)
이렇게 100,000쌍의 데이터를 전부 학습용(training data)로 쓰고나서
모델이 얼마나 잘하는지 확인해보면
제대로 된 모델을 선택해서 학습했다면 8~90% 이상의 정확도를 가질 것이다.
이를 학습 데이터에서의 성능, training performance라고 한다.
(틀린 경우를 계산하면 training error라고 한다)
하지만 이미 모델이 본 데이터에 잘 맞춘다면
실제로 이해를 해서 잘 맞춘다기에는 보기 어렵다
그렇기 때문에 학습 데이터뿐만 아니라 평가용 데이터 (evaluation data) 필요하다.
평가용 데이터는 모델 학습할 때 절대 사용하면 안된다.
주로 전체 데이터 중 10~30%를 평가용 데이터로 할당한다.
꽤 큰 부분을 평가용으로 나누어 놓는 이유는 그만큼 평가가 중요하다는 말이다.
이렇게 전체 데이터에서 일부분을 뚝 떼는 방식을 holdout method라고 한다.
연구, 개발 할 때도 평가용 데이터 얼마나 큰지 중요한 부분이다.
선거 여론 조사도 샘플 표본 수가 얼마나 크냐에 따라 오차범위가 결정되는데
이를 신뢰 구간 (confidence level)이라고 한다.
같은 통계학적 원리로 ML 모델의 평가용 데이터도 너무 작으면 결과 신뢰할 수 없다.
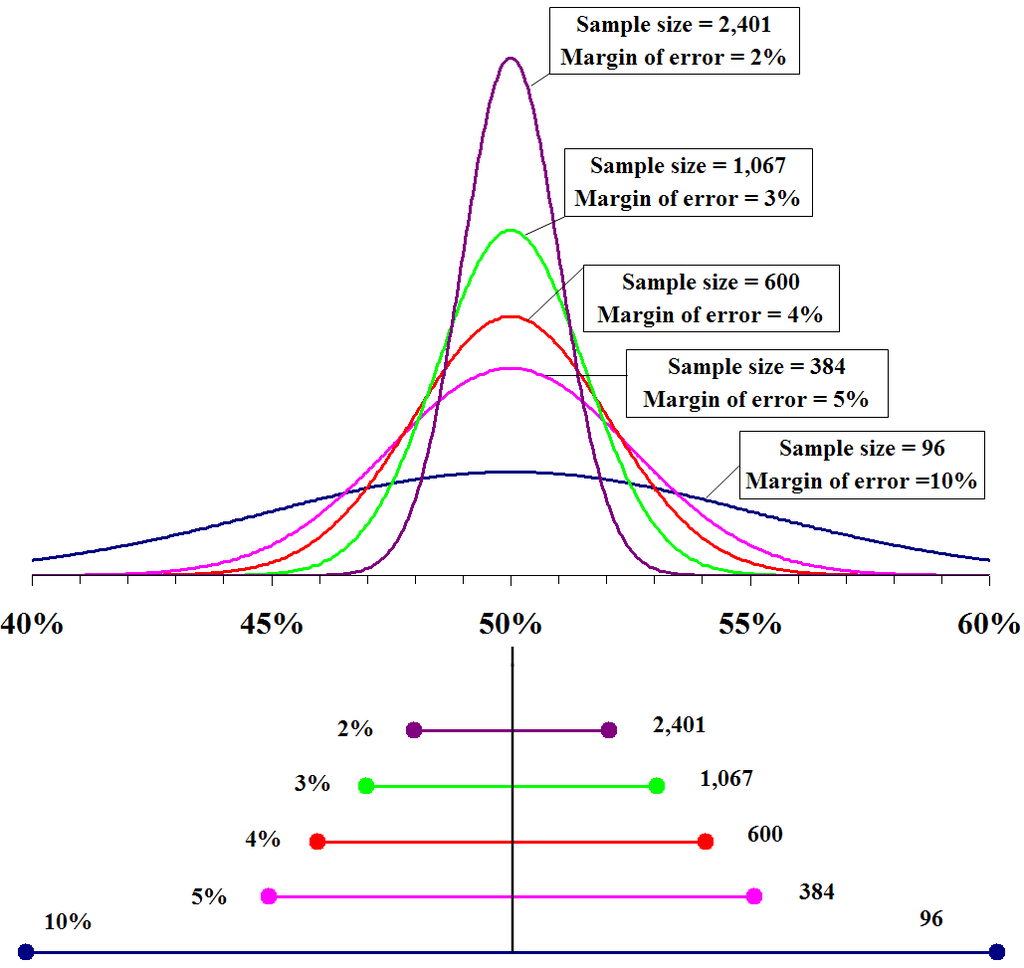
sample size가 커질수록, margin of error 작아지고, confidence level 커진다.
https://en.wikipedia.org/wiki/Margin_of_error
Validation set = 예비 고사, Test set = 수능
평가용 데이터를 두 세트로 나누고는 한다. : Validation과 Test
Validation set 존재 목적
- 어떤 모델 구조, 크기를 사용할지, 모델 변수들은 무엇으로 할지 (model hyperparameter)
- 얼마나 오래, 얼마나 빠르게 학습을 시킬 것인지 (learning hyperparameter)
등을 결정하기 위함이다. Validation set 결과 좋지 않으면
생각보다 낮은 예비 고사 성적을 받아 들고 만족하지 않는 학생과 다음과 같은 고민 해야한다.
공부하는 방식이 잘못 된건가?
영어는 잘 나오니 수학을 좀 더 집중해야하나?
공부시간을 늘려야 하나?
과외를 바꿔야 하나?
영리한 학생들은 자신이 틀린 문제를 보고 분석한다.
어떤 유형의 문제를 잘 틀리면 그 유형을 집중적으로 공략한다.
틀린 유형의 문제를 더 푼다 => 학습 데이터를 늘린다.
문제 접근 사고방식을 바꾼다 => 모델 구조를 바꾼다
단순히 그 유형 문제에 더 오랜 시간을 쓴다 => 학습 시간을 늘린다.
ML 모델의 잘 학습시키는 족집게 과외 선생의 팁
1. 무작위로 잘 나누고 있는지 확인
- 학습, 평가용 나눌 때 무작위(random shuffle)로 나누는게 중요하다.
의외로 데이터의 순서가 학습이나 평가에 큰 영향을 줄 수 있기 때문에
가장 기초적이면서 제일 중요한 부분이다.
2. Validation / Test set에 있는 데이터가 Training과 중복되지 않는지 확인
- 중복을 확인하지 않으면 의도치 않게 커닝하고 있는 모델에 속아 넘어갈 수 있다.
결과가 잘 나온다면 이 의심부터 해본다.
3. 세 부분의 분포가 최대한 비슷하게 만들어라
- 학습용 데이터가 평가용 데이터와 너무 다르면 문제가 생길 수 있다.
특히 여러 개의 정답이 있는 multi-class classification 다룰 때는 class 간의 분포 맞추고, regression을 다룰 때는 평균값이나 표준 편차를 최대한 맞춰주는 게 중요하다.
4. 데이터 수 적으면 k-fold cross validation 이용
- 만약 데이터 수 적으면 평가용 데이터 작아지고 오차 범위가 커진다. 이를 대비해서
f-fold CV라는 방식 존재한다.
예를 들어 데이터를 5묶음(k=5)으로 나누어 한 묶음을 평가용, 나머지를 학습용으로 쓰는 방식으로
총 5번 모델을 학습시킨다. 그러면 총 5번 평과 결과가 나오는데 이를 평균을 내서 신뢰도를 높이는 방식이다.
5. Test set은 마지막까지 보지마라
그래야 결과가 정말 순수하고 신뢰받을 수 있는 결과가 된다는 말이다.
앞서 말한듯, 학습에 관련된 모든 결정은 validation set에서, 예비 고사 결과를 보고 끝내야
진정한 모델의 실력을 측정할 수 있다.
