y = f(x)
x는 input, y는 output
예를 들어 x는 영화 대사, y는 반말(o), 존댓말(1)이라고 한다.
만약 어떤 관객이 x를 들었을 시, 즉시 y를 결정할 수 있을 것 이다.
(x,y)
("라면 먹고 갈래요?",1),
("혼자니?",0),
("싱글이야",0),
("눈사람 같이 만들어요",1)
영화 몇 편만 보면 몇 백개, 몇 천개의 (x,y) 쌍을 만들 수 있다.
이런 데이터가 있으면 우리는 존댓말과 반말을 판단할 수 있는 NLP 모델 학습시킬 수 있다.
함수 f(x)는 input이 어떻게 표현되느냐에 따라 달라진다.
텍스트인 x가 word2vec처럼 100-demension vector로 표현된다면 f(x)는 100차원 방정식 또는 그 이상이 되어야 한다.
하지만 100차원을 쉽게 이해하기 힘드니, 간단한 2차원으로 생각해보자
위 데이터에서 각 x는 이런 식으로 평면에 표현될 수 있을 것이다.
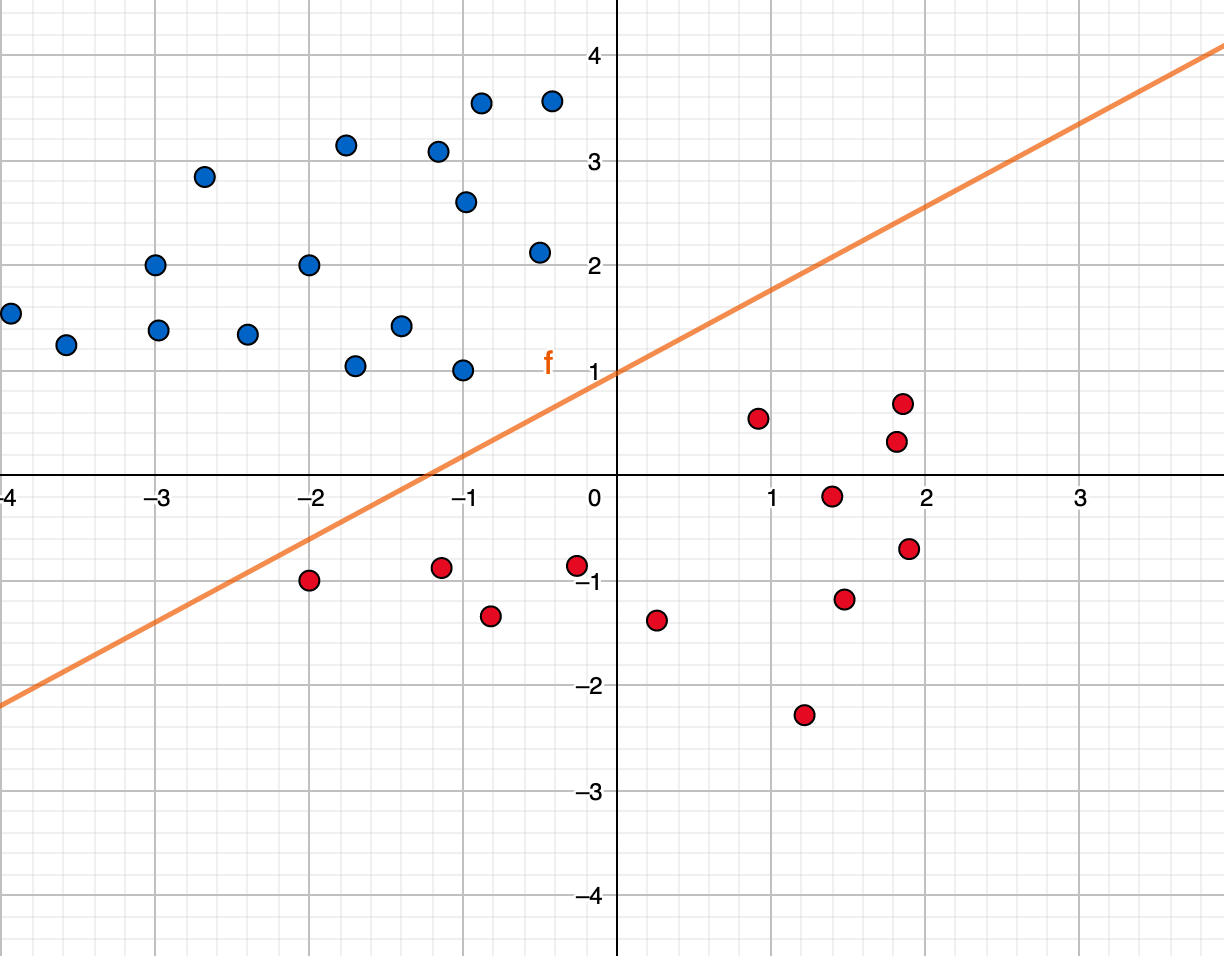
존댓말 데이터 = 파란색, 반말 데이터 = 빨간색
만약 우리가 존댓말 데이터와 반말 데이터 분리하는 경계선을 그린다면
위에 오랜지 선으로 표현될 수 있다. 하지만 문제는 ML 모델이 데이터를 전부
살펴 보고 계산하기 전에는 저 오렌지 선을 그리기 쉽지 않다는 점이다.
처음 시작할 때는 데이터를 보지 않아 아무런 정보 없기 때문에
아래처럼 대충 아무렇게 긋는다.
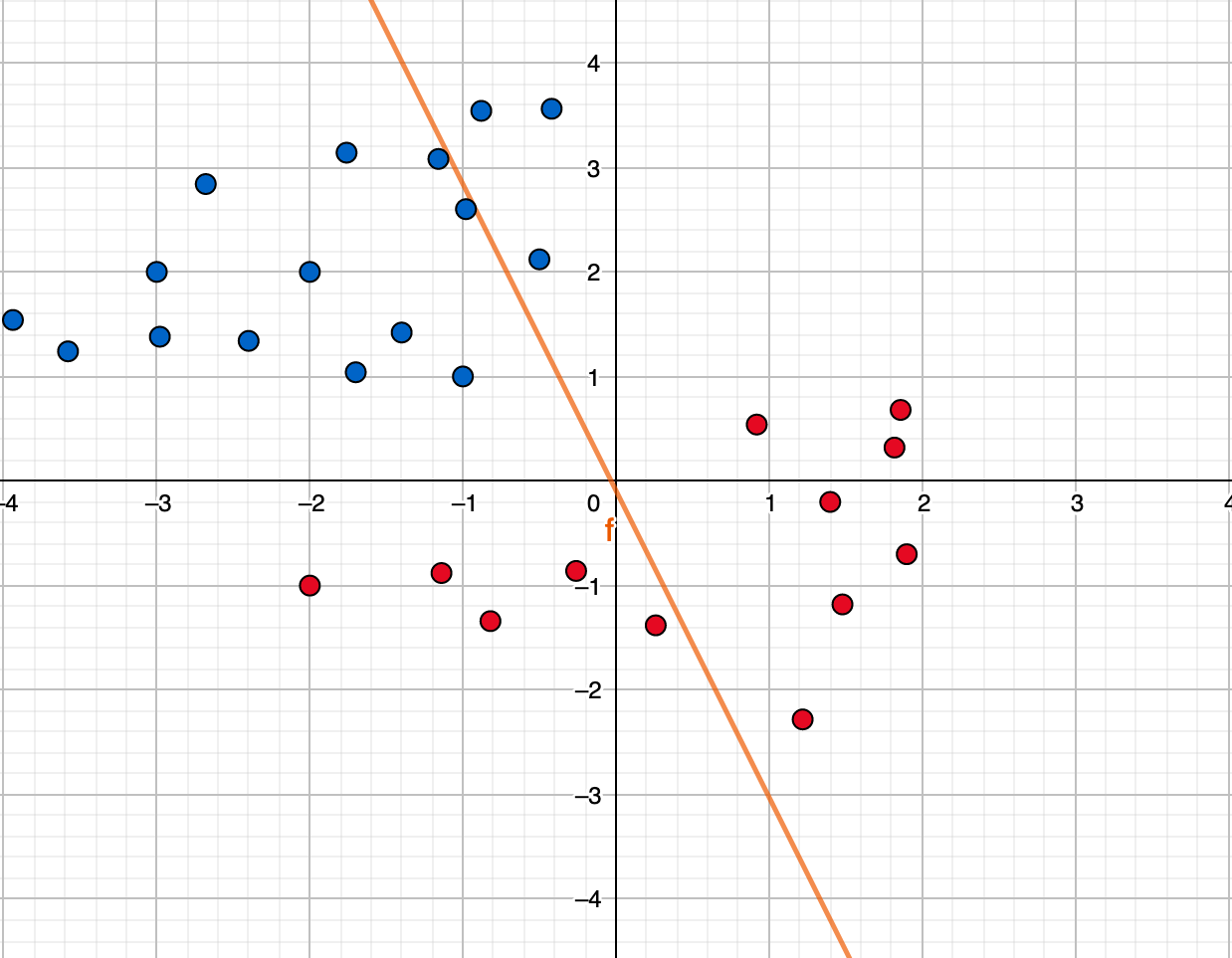
ML 모델은 이렇게 대충 그어놓고 데이터 하나하나 보면서 고쳐 나간다.
이걸 모델이 학습한다고 표현한다
점차적으로 우리가 원하는 첫번째 그래프의 이쁘게 가운데에 그어진 오렌지 선이
최종 목표이다.
근데 문제는 ML은 똑똑하지 못해 모든 데이터를 한눈에 파악하지 못한다.
모든 데이터가 저렇게 2차원의 나타난 예시처럼 쉽게 경계선이 보이지도 않는다.
ML 모델은 어떻게 학습을 통해 알맞은 경계선을 찾아가는 걸까?
Cost function을 그려 나아가자
ML 모델이 학습을 하는 과정도 우리가 등산을 하는 것과 비슷하다.
다만 다른 점은 우리처럼 지도를 볼 수 없고, 시력도 좋지 않아 정상인지 알지 못한다.
ML모델은 어떤 목표를 가지고 앞으로 나아가는 걸까?
핵심은 cost function (비용함수)이다.
경제 과목에서 비용은 줄여나가는 것이 좋은 것이라고 배운다.
ML에서 현재 모델이 얼마나 목표(objective)와 멀어져 있냐를 cost function으로 계산한다. (loss function, objective function 이라고 한다)
ML의 본질은 cost를 최소화 하는데 있다.
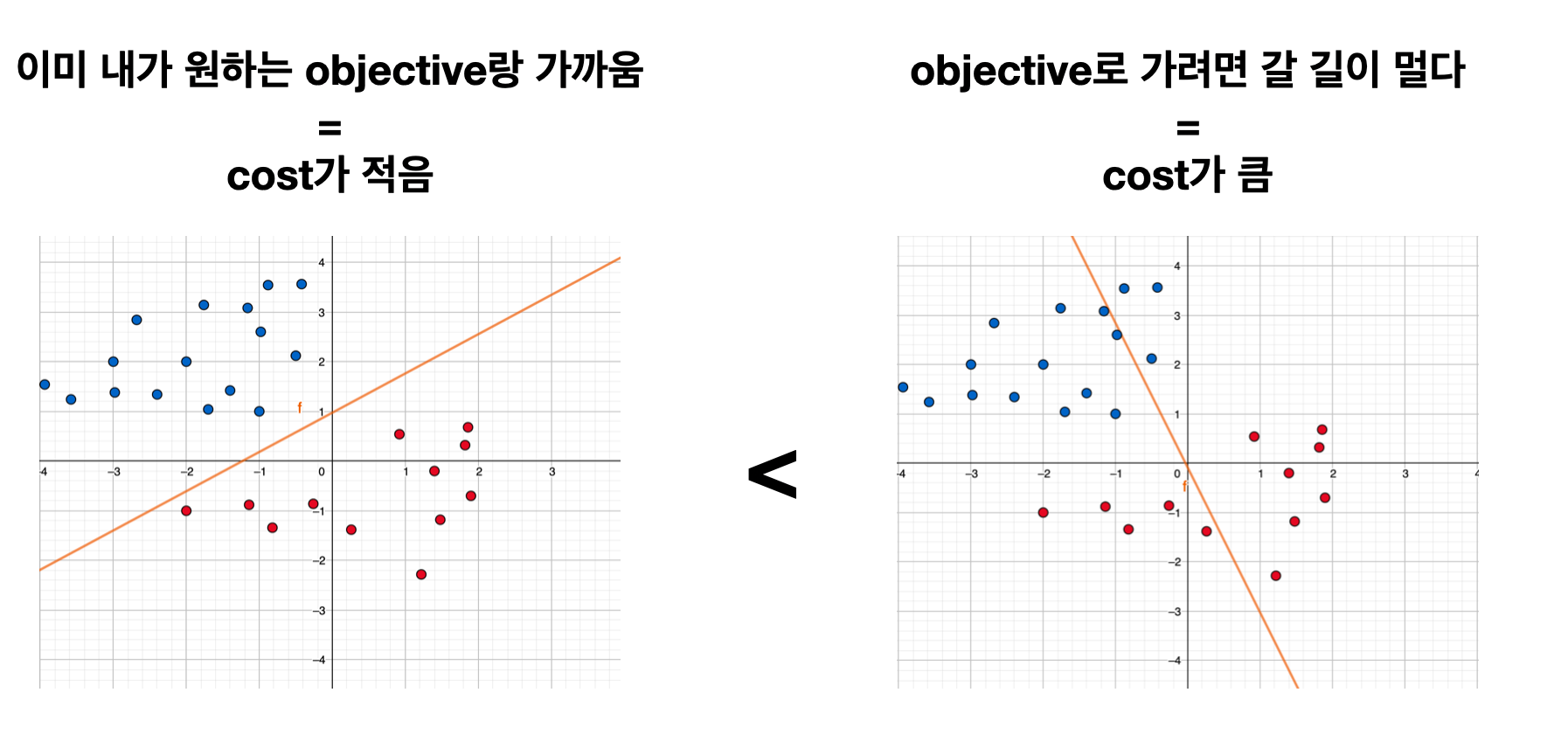
Cost는 현재 그려진 선이 얼마나 학습 데이터에 잘 맞는지 계산하여 합한 것이다.
다시 위 그래프 두개를 보면, 첫 번째 그래프의 선이 두 번째 보다 더 학습 데이터에 잘 맞기에 cost가 첫 번째가 더 작을 것입니다.
f(x)는 어떻게 바뀌냐면 함수의 파라미터를 조금씩 변형해 가며 바꾼다.
2차원 방식에는 함수가 2가지다. 기울기a와 y절편 b
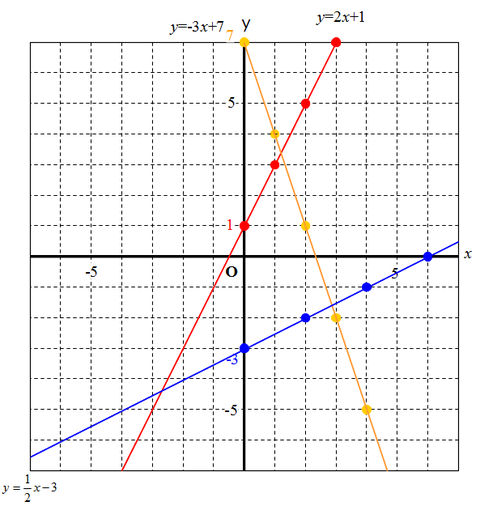
우리는 a와b를 합쳐서 function weight(w)라고 부른다.
2차원 함수는 w가 두개지만,더 복잡한 함수는 w가 많다.
최신 deep learning 모델들은 w가 몇 백만 개,몇 억개까지 늘어나기도 한다.
w가 바뀌면 그때그때 같이 바뀌는 cost function를 또 다른 그래프로 그리면 아래처럼 표현할 수 있다.
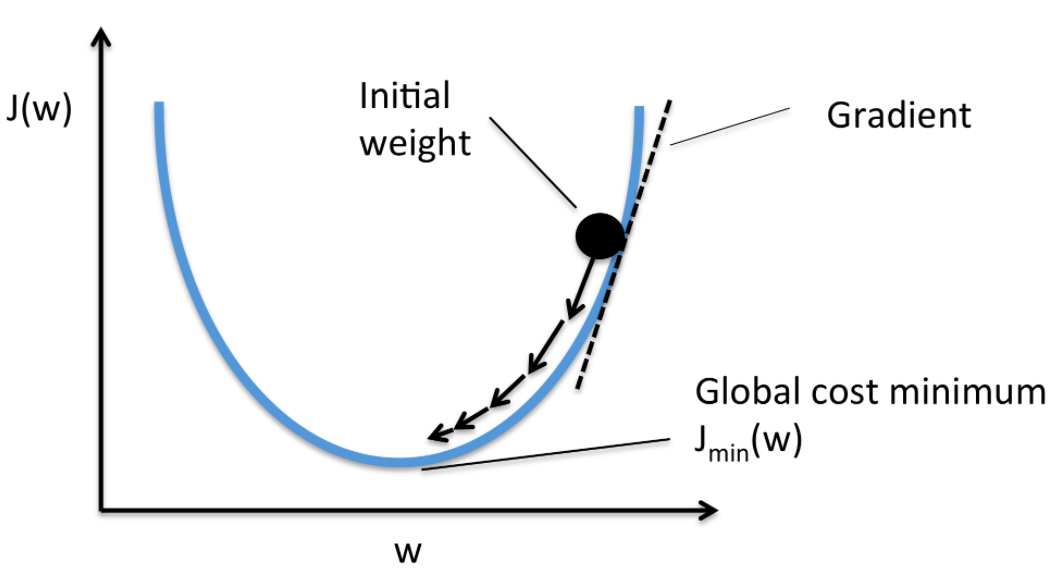
우리의 목표는 Cost가 가장 낮은 지점 (global cost minimum)을 찾아야 합니다.
데이터를 하나하나 보고 계산해보면서 시행착오를 통해 도달하는 것이다.
또 다른 문제는 한 발자국 움직일 때 자기가 가진 모든 데이터를 다 계산해보고 결정하는 것은 너무나 시간이 오래 걸린다.
그래서 중간중간 틀린 방향으로 가도 결국 목적지에 도달하는 방식으로
minimum을 찾는 방식을 Stochastic Gradient Descent(SGD) 라고 한다.
