Likeliness - 그럴듯함?
Likeliness 직역하면 '그럴듯하다'
누가 어떤 일이 일어났다고 설명해줄 때, 우리는 "그럴듯하네" 반응한다.
우리가 문장을 읽을 때도 그렇다.
딱 읽고 자연스러운 문장은 "그럴 듯"하기에 술술 읽힌다.
조금이라도 이상한 단어 쓰이거나 문법 틀리면 우리는 바로 부자연스러움을 느낀다.
우리 뇌는 이미 LM을 구축해 놓은 상태다.
몇십 년 동안 읽은 책, 나눈 대화, 듣고 본 TV, 영상 등 매체를 통해
엄청나게 많은 데이터를 처리하며 하나의 언어에 대한 감과 지식을 쌓아왔던 것이다.
그래서 국어/논술 시험 잘 보려면 독서를 많이 해야하는 것도 데이터가 많을수록
한 사람의 LM은 더 우수해진다.
하지만 어떤 문장 주어졌을 때 "얼마나 그럴듯한가요, 숫자로 표현해보세요"
라고 말한다면 계산하기는 힘들다.
우리의 뇌는 어떻게든 열심히 계산을 하지만, 우리가 직접적으로 숫자를 생각해내기는 힘들다.
다만 분명한건 그 숫자는 존재한다. 왜냐면 두 문장이 주어졌을 때 어떤 게 더 그럴듯하냐고
물어보면 비교할 수 있기 때문이다.
통계학 기초를 공부한 사람들은 likeliness(가능도) 낯설지 않은 용어다.
확률과 비슷하지만 조금은 다른 가능도는 말 그대로 얼마나 가능한지의 정도를 나타낸 숫자이다.
인간의 뇌에 자연스럽게 쌓아 올리는 LM 모방하려면 통계학적 접근을 해야 한다.
이렇게 statistical langauge modeling 소개 하려고 한다.
문장은 단어의 연속
예전에 NLP에서 어떻게 문장 이해하고 표현하는지 대해 배웠다
단어들의 하나의 문장을 구성한다고 보고, 하나의 가방 또는 조합으로 표현해
ML 모델에 넣는다고 배웠다. LM 역시 이와 크게 다르지 않다.
문장을 단어의 연속으로 보는 것이다.
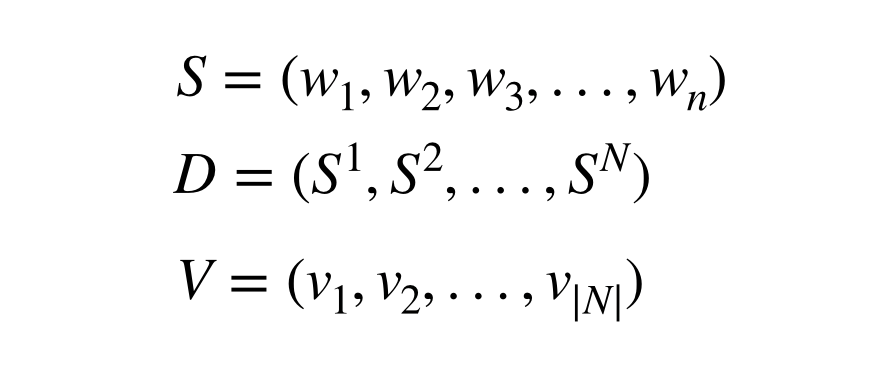
S:문장, D:데이터, V:단어 리스트
S(Sentence)는 단어 n개가 들어가 연속으로 들어 있는 리스트, w는 문장에 들어가 있는 단어, D는 N개의 문장이 포함된 데이터, 그리고 V는 가능한 모든 단어들의 리스트인 vocabulary입니다.
한 문장이 그럴듯함은 어떻게 계산할 수 있을까?
바로 단어들의 joint probability (동시 확률분포) 를 계산한다.
4개의 단어가 있다면 4개가 함께 발생할 확률을 계산한다.
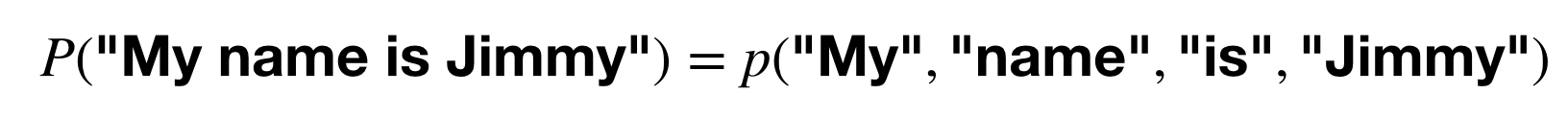
이 문장이 발생할 확률은?
이걸 어떻게 계산하냐면 가지고 있는 데이터로부터 계산하는 것입니다.
사람이 평생 읽고 듣고 보며 모은 데이터를 통해 단어의 감을 익히듯,
NLP에서 데이터(corpus)를 통해 language model을 학습한다.
