CNN #2 (Player Contact Detection Detect Player Contacts from sensor & video data
Deep-Learning
✅ ResNet
- Residual Neural Network의 줄임말로 이름을 보면 잔차와 관련이 있음을 알 수 있다.
- Residual representation 함수를 학습함으로써 152개의 layer에 달하는 신경망을 학습할 수 있다.
- ResNet 사용 시 layer의 인풋이 다른 layer로 곧바로 건너 뛰어 버리게 됌. (skip connection을 사용하여)
🎈 Plain Network
🎈 skip connection in ResNetskip(shortcut) connection을 사용하지 않는 일반적인 CNN(AlexNet, VGGNet) 신경망을 의미. layer가 깊어질수록 gradient vanish exploding 문제가 발생
(작은 미분 값들이 여러 번 곱해지면 0에 가까워지는 문제 발생) >> "기울기 소실 문제"
(큰 미분 값들이 여러 번 곱해지면 값이 매우 커지는 문제 발생) >> "기울기 폭발 문제"
🎈 ResNet Architecture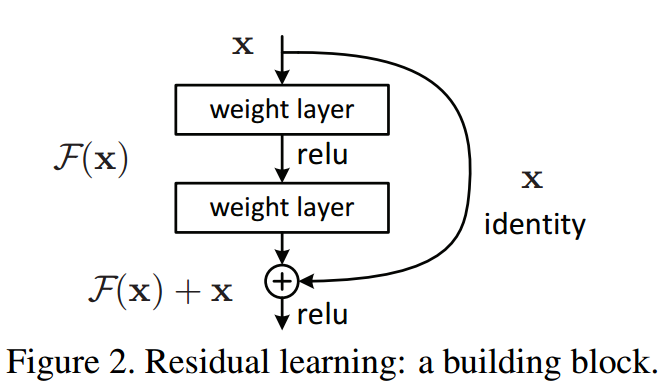 기존 신경망은 H(x) = x가 되도록 학습했으나, skip connection에 의해 출력값에 x를 더하는 H(x) = F(x) + x로 정의하여 최적화를 쉽게 함.
기존 신경망은 H(x) = x가 되도록 학습했으나, skip connection에 의해 출력값에 x를 더하는 H(x) = F(x) + x로 정의하여 최적화를 쉽게 함.
위 사진은 ResNet의 가장 기본적인 구조인 Residual Block, BottleNeck Architecture로 불린다.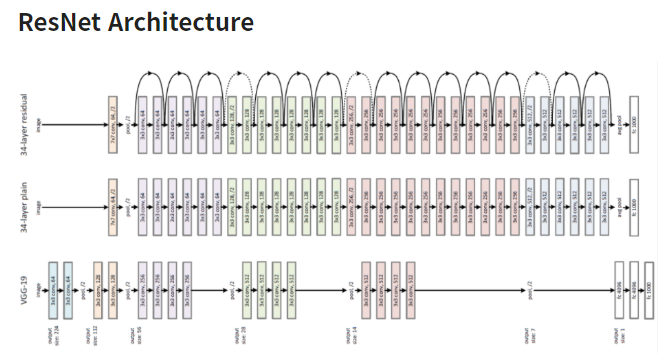 🎈 layer stack bloack 해당
🎈 layer stack bloack 해당
: 1x1, 3x3, 1x1 conv layer로 구성
맨 위부터 34-layer ResNet (plain network + skip connection)
중간은 VGG-19가 깊어진 34-layer plain network
맨 아래는 VGG-19skip connection을 위해 더해지는 값 x와 출력값의 차원이 동일해야 한다. ResNet에서는 입력 차원이 출력차원보다 작을 경우(입력값, 출력값 차원이 다른 경우)
아래 3종류로 connection을 진행한다.- shortcut은 증가하는 차원에 대해 추가적으로 zero padding을 적용해 identity mapping을 수행하여 추가적인 파라미터 없앰. (연산량 제일 적음)
- 차원이 증가하는 경우에만 Projection shortcut을 사용, 다른 shortcut은 identity로 추가적인 파라미터 필요 (연산량 보통)
- 모든 shortcut을 Projection (연산량 제일 많음)
✍️ Implement ResNet by Code
"1st and Future - Player Contact Detection Detect Player Contacts from Sensor and Video Data" kaggle 대회에 참여하며 ResNet 모델을 활용하여 프로젝트를 진행하였고 기본적인 모델 이해와 구현 코드를 설명하며 작성하고자 한다.

🎈 albumentations 이해하기
- fast image augmentation library로 TorchVision에서 제공하는 torchvision.transforms이외에 이미지를 쉽게 augmentation 해주는 python 라이브러리
- 이미지외에도 영상변환 알고리즘을 제공해 처리속도가 매우 빨라 딥러닝 전처리 용으로 유용하게 사용할 수 있다.
- 뿐만 아니라 이미지 기반 딥러닝 어플리케이션 중 대표적인 세그멘테이션(Masks), 2D object detection(BBoxes) 그리고 Keypoints를 자동으로 augmentation에 적용 가능.
< 기본적인 작동 방법 >
- opencv 혹은 입력할 이미지를 RGB형태로 변환한다.
- transform = A.compose([])로 이미지, 라벨에 augmentation 적용할 객체 생성
- augmentations = transform(image=image, mask=mask)를 이용하여 실제 Augmentation을 적용
- augmentation_img = augmentations["image"]를 이용하여 Augmentation된 이미지를 얻음
- augmentation_mask = augmentations["mask"]를 이용하여 Augmentation된 마스크를 얻음
< 구현 코드 >
import albumentations as A
transform = A.compose([
A.HorizontalFlip(p = 0.5)
A.ShiftScaleRotate(p = 0.5)
A.RandomBrightnessContrast(brightness_limit = (-0.1, 0.1), contrast_limit = (-0.1, 0.1), p = 0.5)
A.Normalize(mean=[0,], std=[1.]
ToTensorV2()
])위 코드를 통해 data augmentation이 가능하고 이미지를 좌우반전, 색변환, 회전, 노이즈 등을 넣어 모델이 데이터를 학습할 수 있게 변환해준다(뒤에 p는 확률값을 의미). 추가적인 함수를 이해하면 다음과 같다.
< albumentation transforms 적용 시 내장 함수 >
- HorizontalFlip() : 좌우
- Vertical() : 상하반전
- Rotate() : 회전
- scale() : 0보다 큰 값을 넣어 이미지 확대 가능
- ShiftScaleRotate() : 이미지를 확대하고 이동시키며 회전
- Crop() : 이미지 영역 설정 가능 // 이후 resize()로 고정
- RandomBrightnessContrast() : 밝기brightness_limit(), 대비contrast_limit() 변경
- HueSaturtationValue() : 색상, 채도 변경
- GaussNoise() : 가우시안 분포를 갖는 노이즈 추가, Cutout(): 정사각형 노이즈 추가
기존 oversampling, undersampling을 이용해 데이터를 축소 및 확대 시키는 과정은 진행해보았지만, 이미지의 경우 albumentations을 통해 데이터를 증강시킬 수 있는 부분을 학습할 수 있었다.
🎈 BBX (Bounding Box)
네 변이 이미지 상 수직/수평 방향을 향한(axis-aligned) 직사각형 모양의 박스로 아래 그림과 같은 형태의 박스를 지칭하며 바운딩 박스라고 부른다.
- Coordinate
- center coordinates : anchor, MSE를 다룰 때 사용
- corner coordinates : loss(loU)

< Type >
- YOLO
Guess object's type and location from seeing image just one time that regard bounding box in an image and class probability as single regression problem.
- DOTA(A large-scale dataset for object detection in Aerial images)
is a large-scale dataset for object detection in Aerial images. It can be used to develop and evaluate object detectors in Aerial images. We will continue to update DOTA, to grow in size and scope and to reflect evolving real-world conditions
CNN 모델 중 하나인 ResNet을 구현해보면서 이미지, 영상 처리에 대한 전처리, transform도 학습하며 이해를 키울 수 있었다.
내일부터 Pytorch를 학습해보려 한다😊
