머신러닝, 딥러닝을 공부하다보면 항상 먼저 튀어나오는 신경 계층망. 이걸 내가 직접 해야 할 날이 올 줄이야.
빅데이터 동아리에서 어쩌다 머신러닝을 공부하게 돼서, 회귀분류부터 공부하고 있었는데 이쪽 분야는 처음인데다가, 혼자 힘으로는 도저히 힘들어서 학부 연구생인 동기 형에게 배운 내용 위주로 이곳에 정리하고자 한다. 주로 코드를 뜯어보는 식이니, 내 시점으로 이해한 글이므로 양해바란다.
머신러닝 VS 딥러닝
두 개가 다른 개념이다 이것 보다는 머신러닝 안에 속해 있는 분야가 딥러닝이다.
난 이 두개를 이렇게 구별했다.
- 머신러닝 : 특성 추출은 인간이 직접하고, 분류를 컴퓨터가 한다.
- 딥러닝 : 특성 추출과 분류 모두 컴퓨터가 한다.
딥러닝이 확실히 더 인공지능스러운 개념이다. 부끄럽게도, 이 두 개의 개념을 오늘에 이르러서야 명확하게 구별할 수 있었다...
회귀 분류 실습 코드 뽀개기
지금부터 차례차례 볼 코드는 2차원 좌표계를 회귀분석하는 코드다. 회귀분석에 관한 이론적인 내용은 다 안 상태니, 여기서 설명은 생략한다. (이 글 쓴 목적은 이를 실행하는 과정을 단계별로 풀어쓴 걸 기록하기 위해 쓴 것이기 때문이다.)
import torch
import torch.optim as optim
import numpy as np
x_train = torch.FloatTensor(np.array([12, 16, 24, 33, 38, 42]).reshape(-1,1))
y_train = torch.FloatTensor(np.array([3, 5, 8.6, 12, 16, 19]).reshape(-1,1))처음부터 난관이다. .reshape(-1,1)은 알겠다. ? x 1 형태의 텐서로 형바꿈하라는 뜻인데, 도대체 왜?
이 가로로 된 녀석들을 세로로 쭉 세워야 x,y 하나하나 입력층으로 입력이 가능하기 때문이다.
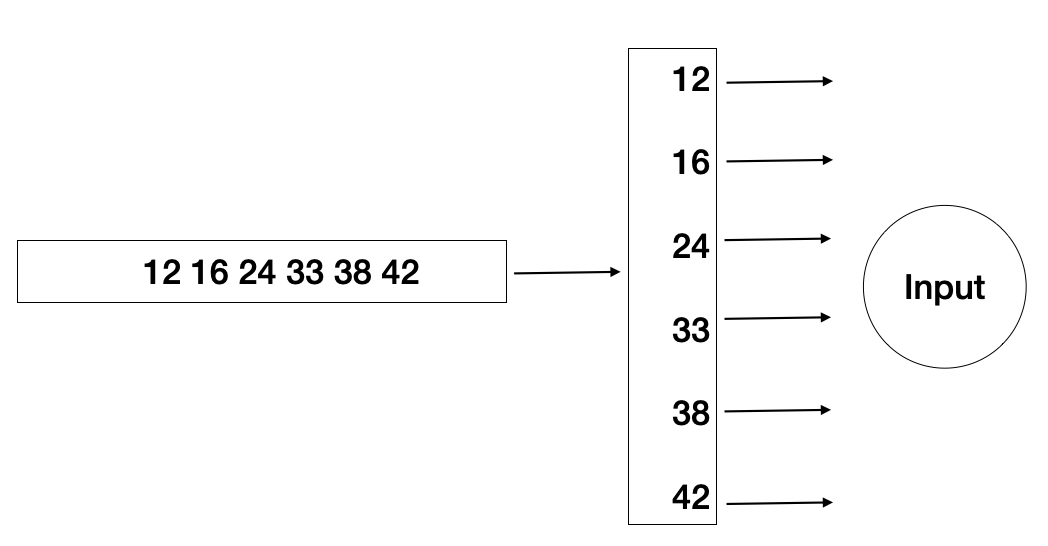
굳이 그림으로 나타내면 이런식이다. 직관적으로 봐도 이렇게 세로로 정렬하는 것이 컴퓨터 입장에서도 개별적으로 입력하기 쉬울 것이다.
optimizer=torch.optim.SGD([W, b], lr=0.00112)
nb_epochs=1000
for epoch in range(nb_epochs+1):
hypothesis=x_train*W+b
cost=torch.mean((hypothesis-y_train)**2)
optimizer.zero_grad()
cost.backward()
optimizer.step()
if epoch%100==0:
print('Epoch {:4d}/{} W: {:.3f} b: {:3f} Cost: {:.6f}'.format(epoch, nb_epochs, W.item(), b.item(), cost.item()))optimizer은 여기서 역전파를 담당하는 녀석이라고 보면 된다. 역전파는 데이터가 신경망을 거쳐 학습이 완료된 후, 다시 역으로 신경망을 거슬러 올라가 가중치들을 조정하는 과정을 의미하며, 이에 따르면 학습을 반복할 수록 원하는 값으로 가중치가 계속 조정되기 때문에 역전파 과정은 매우 중요하다.
Optimizer은 이를 담당하는 녀석이며 zero_grad()는 학습한 가중치가 누적이 되어 가중치가 정상적으로 조정이 되지 않기 때문에 '초기화'를 시켜준다고 생각하면 된다.
cost.backward()는 이름 그대로 역전파를 진행하는 함수다. backward()는 누가 봐도 뒤로 가라는 말인데, 이곳에서 역전파가 이루어진다는 말이다. 그리고 optimizer.step()은 역전파가 끝나고 수집한 정보를 토대로 가중치들을 조정하는 녀석이다. 분명 이 함수 내부에서 일어나는 일은 온갖 복잡한 수학공식으로 뒤덮인 일일텐데, Pytorch, 이 녀석은 아무리 봐도 참 대단한 녀석이다. 단 몇 줄로 이 복잡한 과정을 이루어내다니.
우리가 진행하는 분석은 선형 회귀 분석이기 때문에, H(x) = Wx + b의 W, b를 최적화 시켜야 한다. 최적화가 됐다는 말은 비용, 즉 cost값이 최소화될 때 학습을 완료했다고 한다.
1000번 학습을 시키며, 100번째 학습마다 결과를 출력하면 다음과 같다.
Epoch 0/1000 W: 0.793 b: 0.023744 Cost: 144.826675
Epoch 100/1000 W: 0.425 b: -0.093833 Cost: 2.449679
Epoch 200/1000 W: 0.410 b: -0.197124 Cost: 1.997619
Epoch 300/1000 W: 0.412 b: -0.296705 Cost: 1.908098
Epoch 400/1000 W: 0.415 b: -0.393198 Cost: 1.824839
Epoch 500/1000 W: 0.418 b: -0.486724 Cost: 1.746620
Epoch 600/1000 W: 0.421 b: -0.577375 Cost: 1.673136
Epoch 700/1000 W: 0.424 b: -0.665240 Cost: 1.604100
Epoch 800/1000 W: 0.426 b: -0.750404 Cost: 1.539240
Epoch 900/1000 W: 0.429 b: -0.832951 Cost: 1.478310
Epoch 1000/1000 W: 0.431 b: -0.912960 Cost: 1.421067학습을 거듭할 수록 cost가 줄어들며 W, b가 최적화 되고 있음을 알 수 있다.
with torch.no_grad(): #no_grad => 역전파 X / 평가할 때는 update X
x_test = torch.FloatTensor(np.array([24, 33]).reshape(-1,1))
y_test = W * x_test + b
print(y_test)학습이 제대로 되었는지 평가할 때는 no_grad()를 통해 update를 중지시킨다.
import seaborn as sns
from matplotlib import pyplot as plt
fig, axes = plt.subplots(figsize=(8,4))
sns.regplot(x_train.squeeze().cpu().numpy(), y_train.squeeze().cpu().numpy(), color='blue', ax = axes) # squeeze => 불필요한 차원 제거 (연산 최적화)
sns.scatterplot(x_test.squeeze().cpu().numpy(), y_test.squeeze().cpu().numpy(), color='red', s=100, ax = axes)학습한 결과를 시각화하는 코드인데, 음...이건 일단 넘어간다. 아, squeeze()에 대해서 물어봤는데, 불필요한 차원을 제거하여 연산을 최적화하는 과정이라고 한단다. 쥐어 짜낸다는 뜻의 squeeze()니 뭔가를 압축하는 그런 맥락인데, 예를 들면 5x1x2형태의 텐서에서 1 이 부분이 불필요하면 이걸 제거한다는 그런 과정이라고 한다.
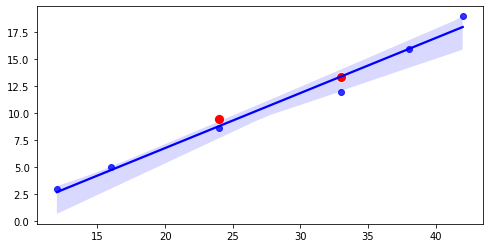
회귀분석이 완료된 모습이다. 파란 점이 초기 입력 값들이며, 빨간 점들은 학습 평가를 위해 새롭게 넣은 입력 값들이다. H(x) = Wx + b에 거의 들어맞는 것을 보아 학습이 비교적 성공적으로 이루어졌음을 알 수 있다.
갈 길은 멀다.
아주아주 생기초에 해당하는 선형 회귀의 코드를 나름 뜯어보았다. 동기 형의 도움 덕에 이제서야 조금씩 이것들이 무엇을 의미하는지는 알 것 같다. Optimizer를 통해 학습을 거듭할 수록 데이터들을 최적화해나가며 조금씩 가중치들을 조정해 나가며 완벽하지는 않지만 나름 적절한 결과를 도출하도록 하는 것이 관건이다. 뜻 그대로 '최적화 하는 녀석'이다.
일단은 임의로 점들을 주면, 최대한 오차를 줄이도록 가장 최적화된 일차 함수를 구하는 녀석을 컴퓨터가 학습을 통해 스스로 찾는 단계를 완성했다. 그리고 역전파를 직접 콘솔로 확인해나가며 가중치가 어떻게 조정해나가는지 눈으로 확인했다. 다른 분들이 하는 것을 보면 뭐가 막 움직이면서 점들을 분류하고, 강아지와 고양이를 분류하는 것들을 만드는데, 지금 선 하나 학습시키는 것도 겨우 한 내 수준은 남들이 보기엔 우스워보일만 하다. 뭐, 처음부터 잘하는 사람은 없으니, 나는 나만의 속도로 나아가면 된다.
