본 글은 이 포스팅과 이어집니다.
모델 평가 지표는 다양하게 존재하기 때문에 여러 가지 출력물을 살펴볼 수 있다.
그 중 몇 가지만 골라서 살펴볼 것이다.
1. 파이프라인

파이프라인을 보면
Raw Data -> SimpleImputer -> SimpleImputer -> OrdinalEncoder -> OneHotEncoder -> GradientBoostingRegressor
인 것을 확인할 수 있다.
SimpleImputer가 2번 나온 이유는 앞 글의 사진을 보면
연속형 변수에 대해서는 평균값으로 대체하였고
범주형 변수에 대해서는 최빈값으로 대체한 것을 알 수 있다.
각각의 열에 다른 대체값을 사용하였기 때문에 2번의 과정이 이름은 같지만 다른 과정임을 확인할 수 있다.
{kind=link}
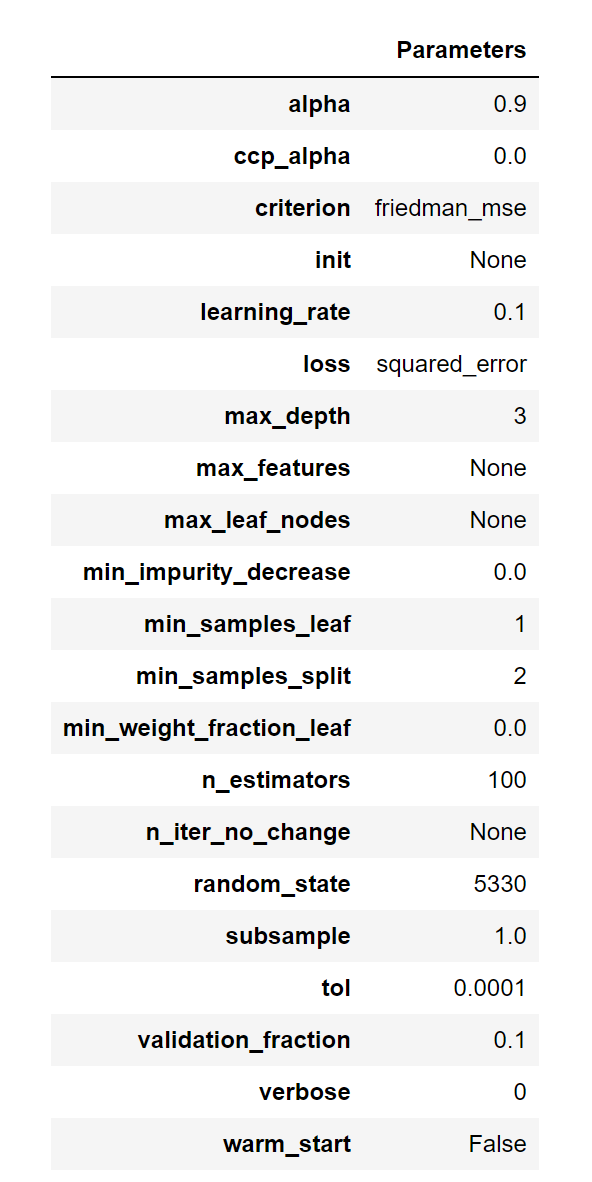
2. 하이퍼파라미터 정보
생성된 모델의 하이퍼파라미터를 어떻게 설정되었는지를 확인할 수 있다.
3. 잔차 분포
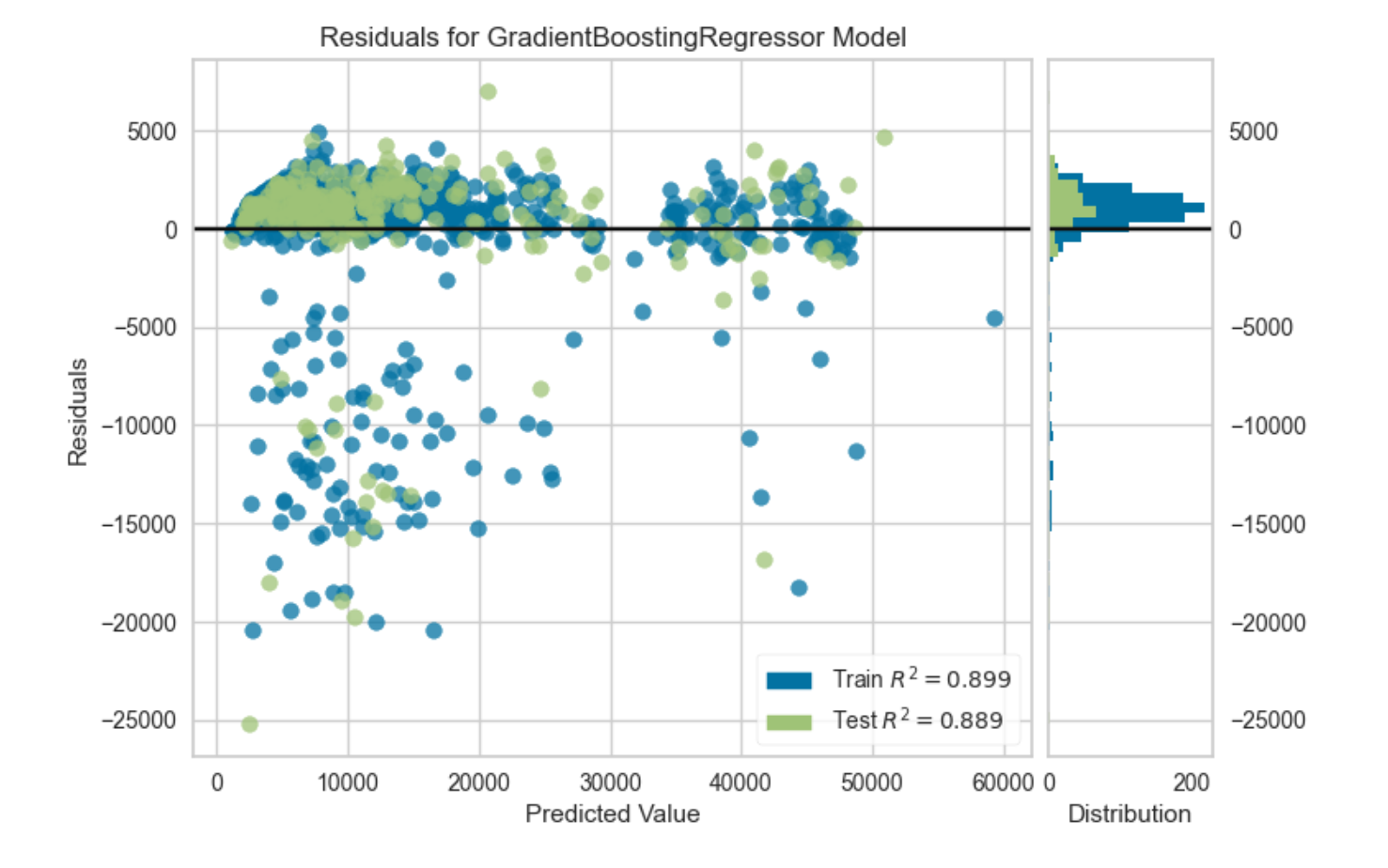
훈련 데이터 셋과 테스트 데이터 셋의 결정 계수도 확인 가능하다.
4. 예측 오류
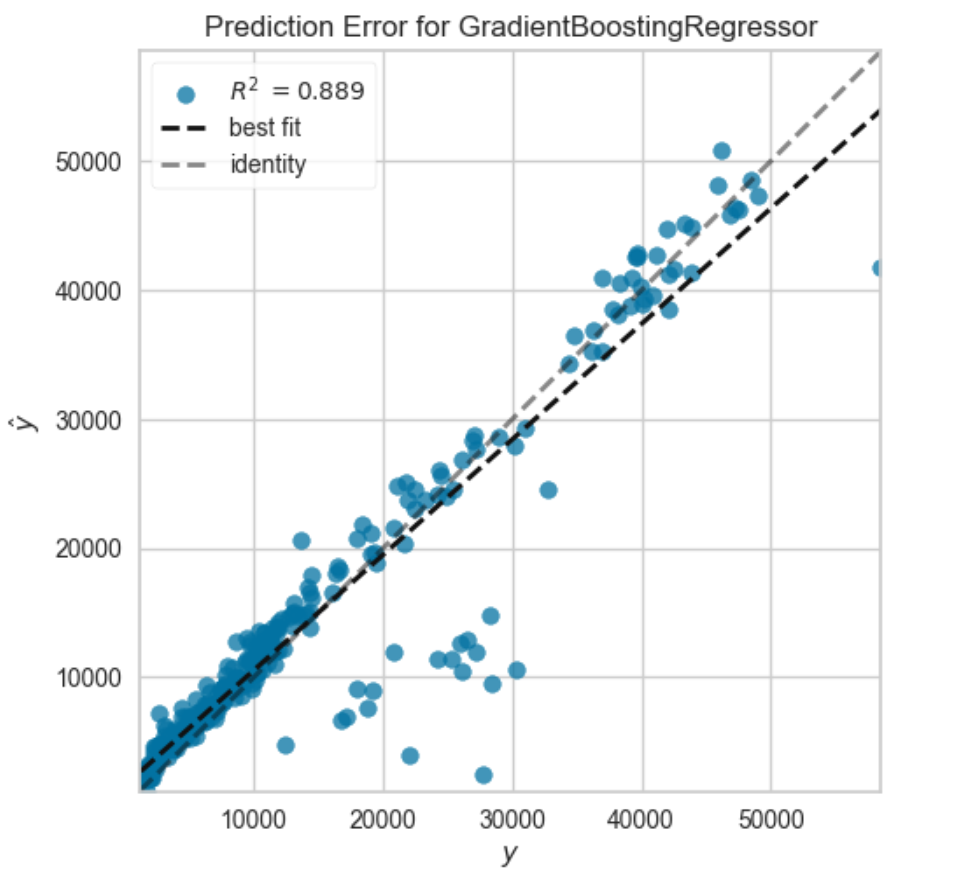
3번과 4번 그래프가 둘 다 실제값과 예측값을 가지고 모델 적합도를 판별하지만
잔차 분포도는 잔차의 분포를 통해 모델 적합도를 판별하고
예측 오류 그래프는 실제값과 예측값의 관계를 직접적으로 시각화한다는 점에서 차이가 난다.
5. 특성 선택과 특성 중요도
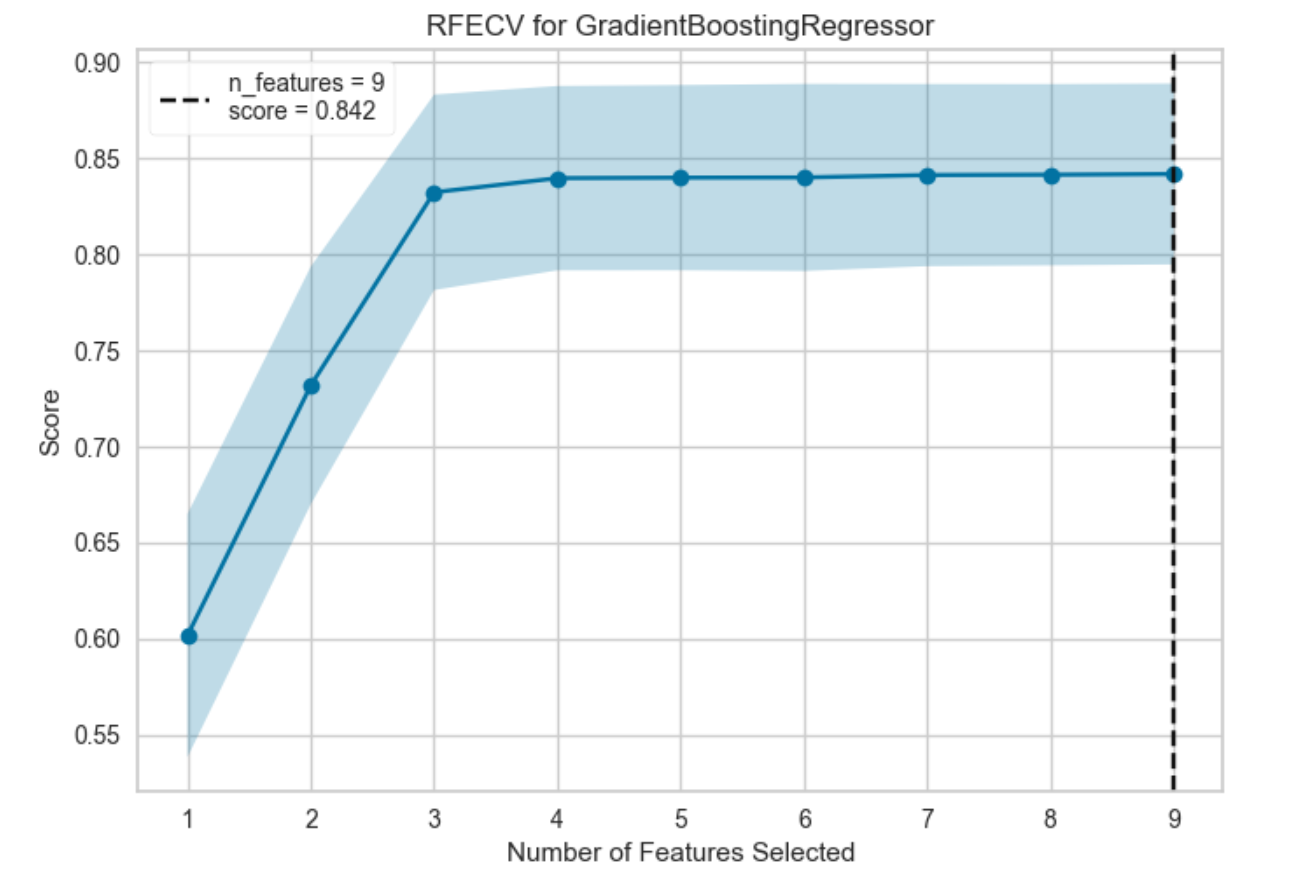
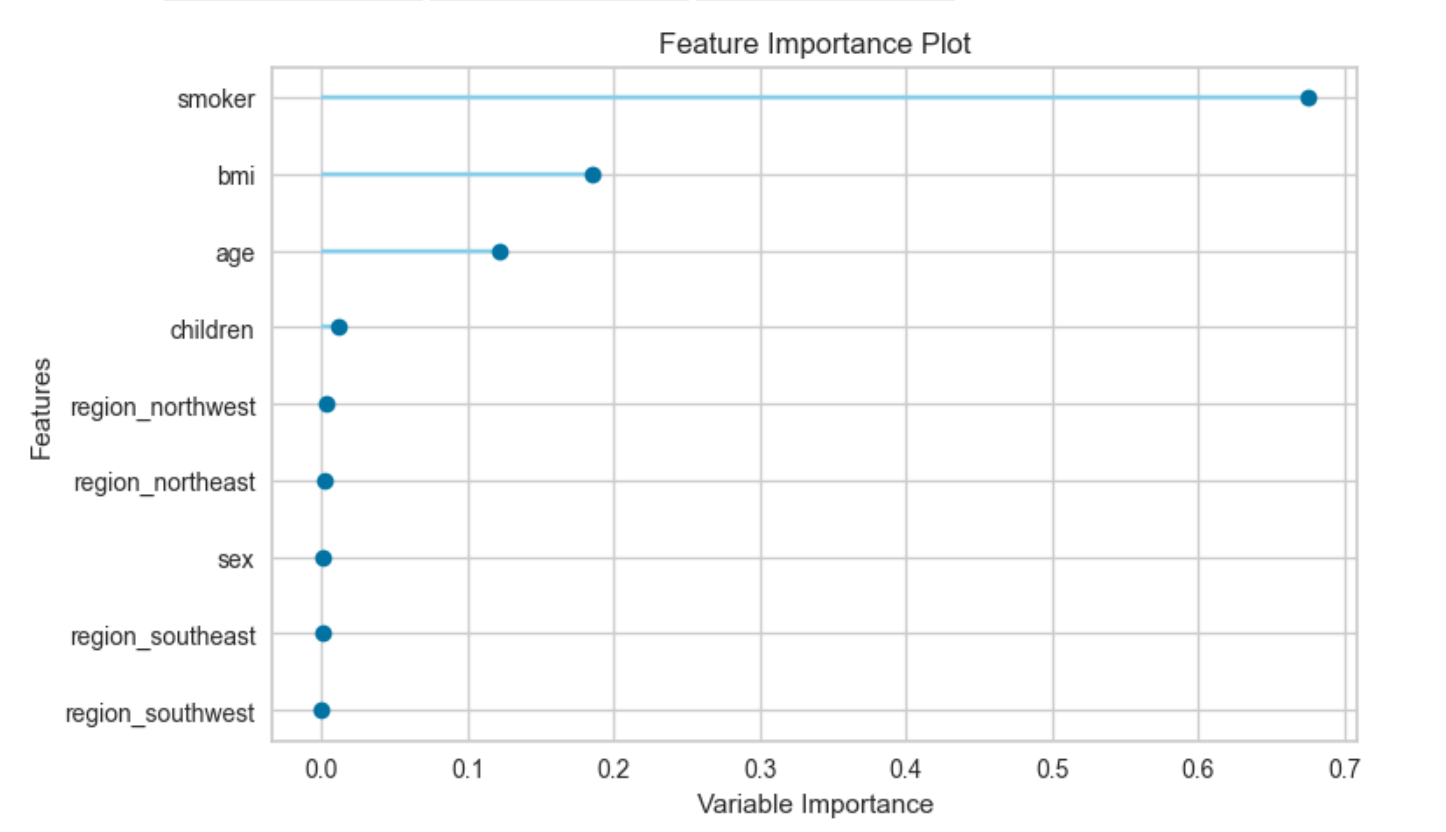
위 두 그래프로 예측에 필요한 최적 변수의 종류와 개수를 확인해 볼 수 있다.
6. 학습 곡선
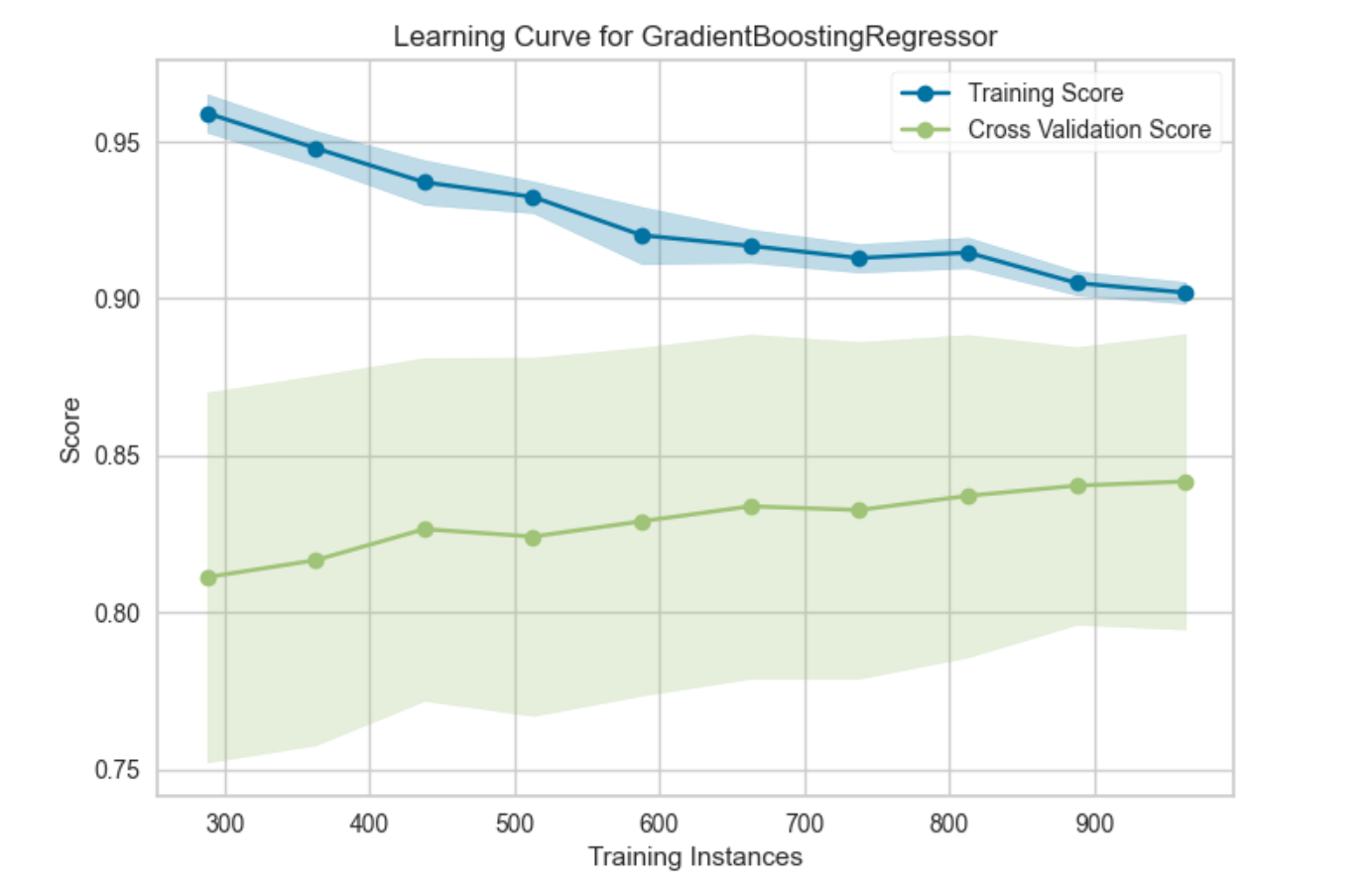
훈련을 진행할 수록 검증 데이터 셋의 성능이 어떻게 향상하는지를 확인할 수 있다.
6. 만든 모델로 예측해보기
⌨ 입력
pred=predict_model(gbr_model)
pred.head(20)💻 출력
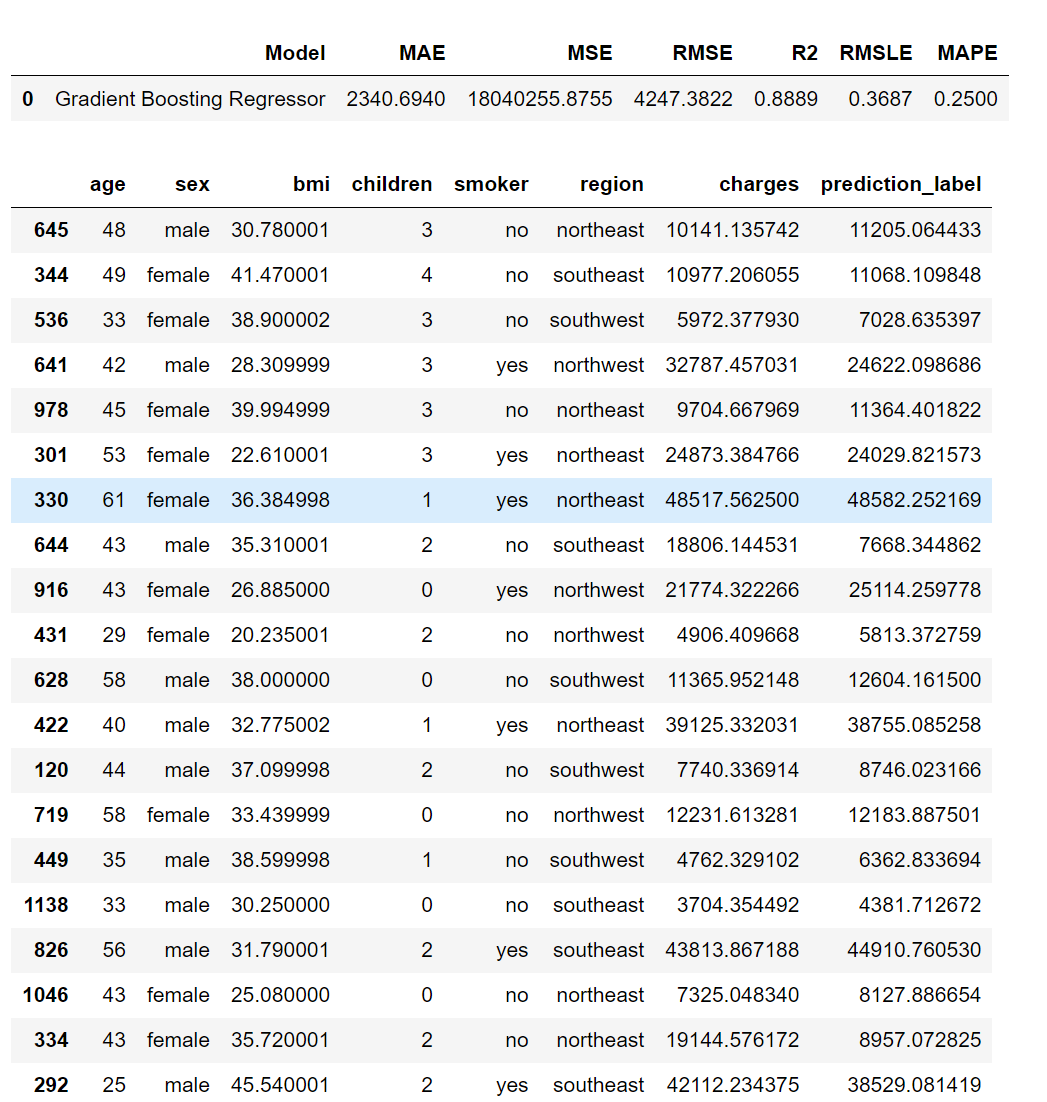
위의 시각화 자료들과 모델 성능 지표를 토대로 이 높은 편이고 나머지 지표 또한 높지 않으며 예측 결과도 실제값과 너무 차이나지 않는 것을 확인할 수 있다. 모델 성능이 준수하다고 할 수 있을 것 같다.
하이퍼파라미터 튜닝을 한 모델의 결과는 또 어떻게 다를지도 확인해보고 각 평가 지표에 대해서도 깊게 공부해서 나중에 글을 작성해보겠다.
