결과를 먼저 말씀드리자면, 메모리 부족으로 인해, user_logs.csv에서는 2개월 데이터만 추출하였고, user_logs_v2.csv에 있는 1개월 데이터와 Concat을 하여 총 3개월 데이터를 사용하기로 하였다.
이로써, 사용할 데이터의 파일 크기는 총 3.77gb가 되었다.
Intro
user_logs.csv의 크기는 28기가로, 약 13gb의 메모리를 지원해주는 Colab에서는 활용하기 어려운 데이터였다. 나는 이 데이터를 Pandas로 읽기 위해 다양한 시도를 해보았지만, 결국 실패로 돌아가게 되었다. 이번에는 내가 시도한 방법들에 대한 회고와 함께 개선 방안에 대해 도출해보고자 한다.
Chunksize를 활용하여 6개월치 데이터만 읽어보자.
chuncksize는 데이터의 크기가 너무 큰 경우, 반복문 내에서, 행 수를 Chunksize만큼 잘라내어 데이터를 조금씩 조금씩 읽는 방법이다.
User_logs.csv는 3.92억행이라는 어마무시한 행으로 구성되어 있기 때문에, Chunksize를 100만으로 조정하여 데이터셋을 생성하였다.- 그럼에도 불구하고,
User_logs.csv를 읽기에는 메모리가 버티지 못하였다. 따라서, 5천만행을 읽을때마다 데이터를 저장하였고, 16년 10월부터 17년 2월까지 총 5개월치 데이터만 긁어올 수 있도록 코드를 수정하였다.
df_members = pd.read_csv('data/l0/members_v3.csv')
members = pd.DataFrame(df_members['msno'])
user_data = pd.DataFrame()
for i, chunk in enumerate(pd.read_csv('data/l0/user_logs.csv', chunksize=1000000)):
print(i)
chunk = chunk[chunk['date']>=20161001]
merged = members.merge(chunk, on='msno', how='inner')
user_data = pd.concat([user_data, merged])
if (i+1) % 50 == 0:
ver = (i+1) // 50
file_name = 'data/l0/user_logs_1610_1702_v' + str(ver) + '.csv'
user_data.to_csv(file_name, index=False)
print('{0}번째 파일 생성 완료!'.format(ver))
del user_data
user_data = pd.DataFrame()
print(str(ver))
if chunk is None: # 읽을 파일이 없으면 반복 종료
break;
file_name = 'data/l0/user_logs_1610_1702_v' + 'last' + '.csv'
user_data.to_csv(file_name, index=False)데이터를 Concat해보자.
16년 10월부터 17년 2월까지 데이터와 17년 3월 데이터를 Concat하여 총 6개월치 데이터를 활용할 수 있도록, 시도하였다. 하지만 5개월치 데이터를 Concat하는 것부터 막히게 되었다...! 죽일 놈의 메모리... 이는 좌절의 시작이었다.
왜 메모리가 부족할까 고민하였다.
3억 9천 2백만행이라는 어마무시한 행이지만, 총 5개월치, 그것도 members_v3에 있는 id의 log만 가져오기 때문에 13기가의 메모리는 충분하다고 생각했다.
Pandas의 한계 (RDBMS의 필요성)
메모리가 부족한 첫 번째 이유로, msno가 매우 길기 때문이라고 생각하였다. msno는 총 44글자로 구성되어있기 때문에 메모리에 매우 큰 영향을 줄 것이라 생각하였다. 하지만 이 생각은 보기 좋게 틀려버렸다.
Pandas는 데이터 타입을 지정하지 않은채 데이터를 load한다. 즉, 모든 데이터를 int64와 object(char와 비슷한 데이터 타입)으로 가져오기 때문에 차지하는 메모리가 매우 크다.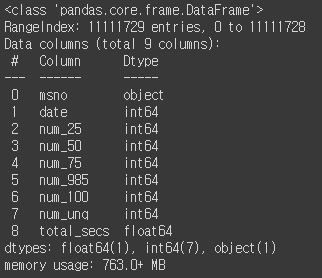
이를 방지하기 위해, load를 할 때, dtype이라는 옵션을 사용하게 되면, 컬럼별로 데이터 타입을 새로 지정할 수 있다. 하지만, 이 옵션을 사용하게 될 경우 pandas가 타입을 변환하는 과정에서 메모리를 많이 사용하게 되기 때문에, 메모리가 부족한 상황이 발생하게 된다.
결국 이 옵션은 데이터를 전처리, 집계하는 상황 외에는 사용할 수 없다고 판단하였다.
(RDBMS를 사용하는 이유가 있다는 것을 이때 깨닫게 되었다. 메타데이터의 중요성이랄까.)
할 수 없이 3개월치 데이터만 Concat하기로 하였다.
Python 데이터 전처리 툴로 Pandas밖에 사용하지 못하기 때문에, 행수를 줄이는 방법 외에는 방법이 없었다. 물론 SQLite와 같은 DB 모듈이 있기도 하지만, 내가 해당 모듈을 잘 사용해 본적이 없고, Pandas와 같은 메모리 이슈가 발생되지 않을 것이라는 장담또한 할 수 없기 때문에, 더이상의 시도는 어렵다고 판단하였다. (실제로 이 이슈때문에 15일 가량, 컴피티션을 미루게 되었다.. 정신적으로 너무나 힘들었다 ㅠ)
Outro
데이터 엔지니어링의 중요성에 대해 깨달을 수 있었다. 컴퓨팅 파워가 부족하여 시도조차 못한다는 것이 매우 아쉽기도 했다.
툴에 대한 이해가 부족한 점도 매우 아쉬웠다. Spark를 써서 해결하라는 Notebook이 많았었는데, 툴에 대한 이해가 부족하여, Colab에서 구현을 못했다는 점도 아쉬운 점으로 꼽힌다.
데이터 전처리가 중요한 컴피티션이 아니라서, 조금 미루기는 하지만, 언젠가 64gb의 램을 수용할 수 있는 환경을 구성하여 많은 컴피티션을 원활하게 수행하고 싶다.
