이번 포스트로 아마 자료구조 포스트는 마무리 될 것이다. 물론, 고급 자료구조로 넘어가면 더 자세히 나갈 부분은 남았지만, 이는 그때그때 학습을 하게 되어 저장해야할 일이 생기면 추가 'cs공부' 포스트 내에 입력하도록 하겠다. 이번 포스트에서 다룰 주제는 '그래프'이다.
그래프
그래프 알고리즘은 수학자 '오일러'에 의해서 고안되었다. '쾨니히스베르크의 다리' 문제에서 고안되었다고 보면 된다.
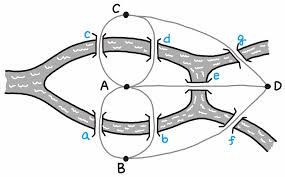
이런 다리가 있을 때 왔던 길을 지나지 않고, 다 통과할 수 있는 방법을 찾는 유형의 문제인데 이 문제를 풀기 위해서는 그래프 알고리즘을 사용할 수 밖에 없다. (물론, 윗 그림에서의 답은 없다는 것을 알 수 있다.)
용어 정리를 먼저 해보도록 하겠다.
-
정점 (vertex) : 연결의 대상이 되는 개체, 위치
-
간선 (edge) : 정점 사이를 연결하는 선
간선에는 방향성이 있을 수도 있고, 없을 수도 있다.
- 무방향 그래프 (undirected graph) : 위 그림처럼 간선에 방향성이 없는 그래프를 말한다.
- 방향 그래프 (directed graph) or 다이그래프 (digraph) : 그래프에 방향성이 있는 그래프
-
가중치 그래프 ( Weight Graph) : 간선에 가중치를 둔 그래프
위 그래프로, 최단거리를 구하거나 시간을 최소하게 갈 수 있는 알고리즘을 구할 수 있다. 거리나 시간을 가중치로 계산하여 문제를 풀 수 있기 때문이다. -
부분 그래프 ( Sub Graph) : 원 그래프의 일부 정점 및 간선으로 이뤄진 그래프
그래프의 ADT
그동안 잠시 자료구조에서 구조를 표현하는데 초점을 둬서 ADT를 정의를 안했었는데, 그래프는 ADT 가 존재한다.
-
그래프의 초기화를 담당하며 두번째 인자로 정점의 수를 전달한다.
void GraphInit(UALGraph * pg, int nv); -
그래프 초기화에 할당한 리소스를 반환하는 기능
void GraphDestroy(UALGraph * pg); -
매개변수 from V 와 to V 로 전달된 정점을 연결하는 간선을 추가함.
void ADDEdge(UALGraph * pg, int fromV, int toV); -
그래프의 간선정보를 출력함.
void ShowGraphEdgeInfo(UALGraph * pg);
그래프의 구현
그래프를 구현하는 방법을 총 2가지를 학습해보았다.
1) 먼저 첫번째는 정방행렬로 하는 인접 행렬(adjacent matrix)기반 그래프이다. 정방행렬은 다음과 같다.

윗 그림을 보고 알 수 있는 정방행렬의 특징은 가로세로의 길이가 같은 행렬인 것이다. 즉, 정점의 개수가 n개일 때, nXn 의 '2차원 배열'을 만든 이후, 정점끼리 연결된 부분에는 1, 안 연결된 부분에는 0을 입력하여 그래프가 연결되어있는지 연결되어있지 않은지 여부를 확인하는 방법이다.
2) 두번째로는 연결리스트를 활용한 방법이다. 인접 리스트(adjacent list)기반 그래프이다. 정점에 연결된 정보를 리스트로 연결해서 담는 방법이라고 생각하면 된다.
그래프의 탐색
깊이 우선 탐색 (Depth First Search : DFS)
: 그래프의 여러 갈래 길에서 한 길을 깊이 파고드는 탐색을 말한다. 그 이후 간선이 없으면 다시 돌아온다.
구현하는 방법에서는 스택과 배열을 사용한다.
- 스택 : 경로 정보를 추적할 때 사용
- 배열 : 방문 정보를 기록할 때 사용
1) 방문한 정점을 떠날 때마다 정점의 정보를 스택에 저장한다.
2) 그 이후 다시 돌아오다가(스택에서 POP 연산을 하다가) 다시 새롭게 연결된 간선이랑 정점이 존재할 때 새롭게 연결된 부분으로 다시 1) 과정을 진행한다. (스택에서 다시 PUSH함)
3) 모든 정보가 스택에서 POP 되었을 때, 알고리즘을 종료한다.
너비 우선 탐색 (Breadth First Search : BFS)
: 자신에게 연결된 모든 정점에게 하나씩 값을 찾아가는 방식
(Breadth 뜻이 폭 인것과 같이 시작되는 정점부터 하나씩 폭을 넓혀 다 보고 넘어간다고 생각하면 된다.)
구현하는 방법에서는 배열은 똑같이 쓰이고, 여기서는 큐를 사용한다.
- 큐 : 방문 차례를 기록하는데 사용
- 배열 : 방문 정보를 기록할 때 사용
1) 큐로 다른 간선으로 이동할 정점의 순서를 기록한다.
2) 다 방문하면 dequeue, 모든 정점을 다 탐색하면 알고리즘을 종료한다.
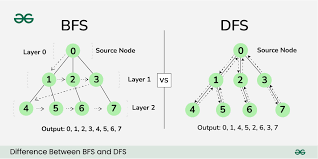
밑에 사진으로 BFS와 DFS 의 차이를 이해하면 좋을 것 같다. 혹시 이 포스트를 보고 학습하는 사람이 있다면 관련 알고리즘을 적용하는 문제들이 백준에 많이 있기에 풀어보는 것도 좋을 것이다.
MST
최소 비용 신장 트리 (Minimum cost Spanning Tree: MST)에 관련해서도 알아보겠다. 그 전에 용어 하나 설명하고 진행하도록 하겠다. 경로(path)란, 두 개의 정점을 잇는 간선을 순서대로 나열한 것을 말한다. 단순 경로(simple path)는 동일한 간선을 중복하여 포함하지 않는 경로를 말하고, 사이클(cycle)은 단순 경로이면서, 시작과 끝이 같은 경로를 말한다.
MST는 그래프의 모든 정점이 간선에 의해 하나로 연결되어 있는 것을 말한다. 그래프 내에 사이클이 형성이 되어있지 않다.
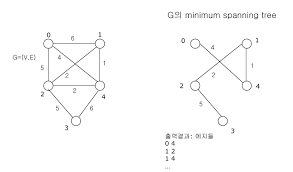
최소비용신장트리를 구성하는데 사용하는 알고리즘을 하나 소개해보고 이 포스트를 마무리해보도록 하겠다. 물론, 지금 설명할 알고리즘을 제외하고도 많은 알고리즘이 존재한다. 대표적인 알고리즘은 크루스칼(Kruskal) 알고리즘이다.
크루스칼 알고리즘
1) 가중치를 오름차순하는 방법
- 가중치를 오름차순하여 정렬한 후, 낮은 가중치부터 하나씩 그래프에 추가를 한다.
- 사이클을 형성하는 가중치는 pass 한다.
- '간선의 수 + 1 = 정점의 수' 를 만족할 때 MST는 완성한다.
: 이렇게 했을 때, 가중치를 낮은 값부터 하나씩 대입하면서 (사이클을 유지하는 가중치는 제외했기에) 그래프를 완성했기에 최소비용신장트리가 될 수 있다.
2) 가중치를 내림차순하는 방법
- 이번에는 가중치를 내림차순으로 정렬 후 높은 가중치부터 하나씩 제거한다.
- 두 정점을 연결하는 다른 경로가 없을 때까지 다른 가중치 높은 간선을 제거한다.
- 마찬가지로 '간선의 수 + 1 = 정점의 수' 를 만족할 때 MST는 완성한다.
(밑에 사진 첫 번째는 가중치 오름차순, 두번 째는 가중치 내림차순 그래프라고 생각하면 될 것이다. )
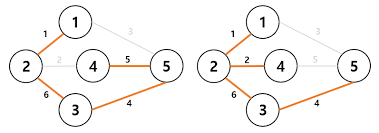
이렇게 자료구조를 약 13챕터로 학습을 마무리하겠다. 물론, 이번에 다룬 자료구조들은 기본이 되는 자료구조이다. 이 자료구조를 활용해서 사용자가 필요에 따라 또 다른 자료구조를 만들 수도 있고, 우리는 이를 만들지는 않더라도 만들어진 자료구조가 있다면 이해를 해야하기 때문에 자료구조에 대한 학습이 꼭 필요하다고 생각한다. CS 챕터는 2-2 컴퓨터 구조에 대한 학습을 하면서 다른 부분으로 다시 올리도록 하겠다.
