오늘은 데이터 베이스에 관한 기본 개념에 대해 설명해보려고 한다.
이런식으로 복잡한 ER 다이어그램을 그려보기 전에 필요한 개념들에 대해 한 번 정리해보려고 한다.
Database
데이터베이스(DB)란, 여러 사람이 공유하여 사용할 수 있도록 구조화된 데이터의 집합입니다. 그러면 일반 DB와 우리가 사용하는 엑셀과 같은 다른 SW와의 차이점은 무엇일까? DB는 다음과 같은 특징으로 다른 소프트웨어와의 차이점이 있다고 설명할 수 있다.
DB의 특징
1. Real-time accessibility (실시간성)
2. Data redundancy (데이터 중복성)
3. Data inconsistency (일관성)
4. Atomicity (원자성)
다음은 DB에서 데이터를 정의하는 방법으로 Data Model 들이다. 여러가지가 있지만, 이 블로그에서는 Relation Model, Entity-realtionship model 크게 2가지(제일 많이 사용됨)에 집중하려고 한다.
- DBMS란?
DBMS(Database Management System)는 데이터베이스를 관리하고 운영하는 소프트웨어로, 데이터베이스에 저장된 데이터를 정의, 조작, 제어하는 기능을 제공합니다.
데이터를 추상화하는 관점은 크게 3가지로 나뉜다.
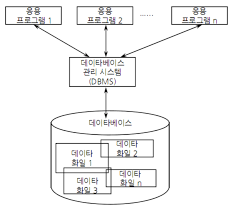
누가 그 데이터를 보는지에 대한 view Level의 관점, 그 데이터에 대한 추상화를 진행하는 Logical Level, 마지막으로 사용자들은 관심없고 개발자들이 주로 관심을 가지는 Physical Level이다. 세 개는 각각 스키마라고 부른다.
External Schema (외부 스키마)
Conceptual Schema (개념 스키마)
Physcial Schema (내부 스키마)
순서를 이렇게 작성한 이유는 외부 스키마에서 내부 스키마로 이동할 수록 점점 reality에서 specifics 의 단계에 대한 이해로 보면 된다.
DB를 사용자들이 왜 사용할까? 바로 시스템이 단단하기 때문이다. 쉽게 예를 들어 많은 회사들이 사용하는 오라클이라는 DB는 비용이 많이 들긴하지만, 사용하게 되면 데이터에 대한 안전함은 보장된다고 감히 장담할 수 있다고 한다. 또한 완전성을 높여주는 트랜잭션 (Transaction) 때문인데, 자세한 내용은 따로 블로그를 통해 다시 다루기로 해보고 지금은 개념에 대한 정의만 확인하고 넘어가도록 하겠다.
트랜잭션이란?
DB의 상태를 변경시키는 작업의 단위
즉, 한꺼번에 수행되어야 할 연산을 모아놓은 것이다.
Relational Model
DB는 감히 relation의 집합체라고 불러도 된다. 그 중에서 제일 많이 사용되는 relational model(관계형 모델)에 대한 설명을 해보도록 하겠다.
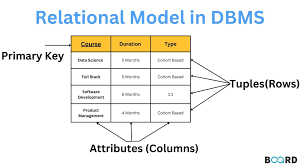
(*출처 : A Quick Guide to Relational Model in DBMS)
Relational model data structure
위 사진을 보면서 relational model에 대한 설명을 하겠다.
relational model은 relation을, 즉 2차원 형태로 나타내는 집합이다. 위에 노란색으로 칠해져있는 부분은 Head 라고 릴레이션 스키마 라고도 부른다. Realtion Intenscion 이라고도 하며, head에 있는 인스턴스들은 고정되어있는 특징을 가진다. 흔히 우리는 열,속성 (Attribute)라고도 하는 부분이 위쪽 부분이다.
다음은 몸체 부분이다. 몸체는 Body라고 하며 Relation Extension으로 Time-varying 의 속성을 가진다. 즉, 시간에 따라서 바뀌는 값들을 적어놓을 수 있다. 우리는 이 부분을 행 또는 튜플(Tuple)이라고 부른다.
또한 각 relation은 relation name도 존재한다.
Tuple의 수 = Cardinality
Attribute의 수 = Degree
Cardinality는 튜플의 수라고 정의되어 있지만, 사실 여기에서는 한 가지의 특징이 더 존재한다. Tuple에는 여러개의 데이터가 저장될 수 있고 Time-varying의 속성을 가지기에 겹치는 값들이 존재할 수 있지만, 이 부분에서는 unique 한 튜플, 즉 중복이 되지 않는 값들의 tuple의 수를 기준으로 Cardinality라고 한다. 이 Cardinality를 활용해 어떤 SQL문이 효과적인지에 대한 지표로 쓰이는 Selectivity를 구할 수 있다. Selectivity (선택도) 는 전체 대비에 얼마나 일치하는지에 대한 지표로, 만약 선택도가 100%라면 그것은 중복된 값이 없다는 것을 보여준다.
Selectivity (선택도 ) = cardinality / the number of tuples
키(Key)
다음은 키에 대한 설명을 하겠다.
키 (Key)
키는 유일하게 식별할 수 있는 identify를 위한 식별자이다.
키는 Super Key, Candidate Key, Primary Key가 존재한다. Super Key는 전체 튜플을 유일하게 식별할 수 있는 키이다. 그리고 우리가 흔히 말하는 키라고 하는 것은 Candidate Key를 말하는 것과 같은데, Candidate Key는 Super key의 특성을 가지면서 최소(minimum)이라는 성질도 가진다. 그랬을 때 우리는 Candidate Key라고 한다. 그 후보키 중에서 선택된 것을 Primary Key라고 한다. 이 키는 개발자의 자의적인 판단에 의해 선택된 것이기에 개발자의 선택 영역이다.
그 외엥 선정되지 않은 후보 키는 대체 키(Alternate Key)라고 하고, 다른 테이블들 간에 참조할 수 있는 키를 외래 키(Foreign Key)라고 한다.
Data Integrity
Data Integrity (데이터 무결성) 에 대해 살펴보도록 하겠다. 데이터 무결성은 크게 3가지가 존재한다. Entity, Referential, Domain Integrity가 있고 각각 한국 말로 개체 무결성, 참조 무결성, 도메인 무결성이라고 한다.
- Entity Integrity (개체 무결성)
개체 무결성에는 크게 3가지의 특징이 존재한다.
- PK는 null 값이 될 수 없다.
- PK는 모든 개체 (tuple)에 유니크함의 보장되어야 한다.
- PK는 속성의 minimal set 이여야 한다.
- Referential Integrity (참조 무결성)
참조 무결성에는 크게 2가지의 특징이 존재한다.
- 피 참조 테이블의 PK로부터 PK를 설정해야 한다.
- Anomaly(이상)이 3가지 존재한다.
Anomaly(이상) 종류 3가지
- Insert Anomaly, Update Anomaly, Delete Anomaly
- Update, Delete 에는 (Restirct, Cascade, Set null)이 존재
이상에 대한 부분은 정규화를 다루는 블로그에서 다시 자세히 설명하도록 하겠다.
- Domain Integrity (도메인 무결성)
- 모든 데이터 타입은 일정해야한다.
사실 이렇게 데이터 무결성이 존재해도, 실무 규칙(Business Rule)과 다를 수 있다. 협업에서 실제적으로는 어떻게 사용하는지는 모르기 때문이다. 다만, 이 3가지가 기본적으로 주어지는 무결성 파트이다.
다음 블로그에서는 relational model에서으ㅣ algebra, calculus 에 대한 내용을 다루도록 하고, 그 이후에 SQL문을 다루도록 하겠다.
