1장 데이터 분석 개요
1.1 데이터 분석 기법의 이해
데이터 처리
- DW(Data Warehouse) / DS ( Data Store ) 에서 분석 데이터를 가져와 처리
- 이외의 데이터는 기존 운영시스템 , 스테이징 영역 , ODS 에서 가져와 처리
- 기존 운영시스템의 데이터를 직접 활용하는 것은 위험
시각화
- 빅데이터 분석에서 시각화는 필수
- SNA(사회연결망 분석)에 활용
공간분석(GIS)
- 지도 위에 속성들을 생성하고 인사이트를 얻는 방법
탐색적 자료 분석( EDA )
- 데이터의 특징과 내재하는 구조적 관계를 알아내기 위한 과정
- 저항성의 강조 / 잔차 계산 / 자료변수의 재표현 / 그래프를 통한 현시성
통계분석
- 기술통계 - 표본이 가지고 있는 정보를 쉽게 파악하도록 정리 ( 평균 , 표준편차 --)
- 추측통계 - 표본의 표본통계량을 통해 모수를 통계적으로 추론
데이터 마이닝
- 대표적인 고급 데이터 분석법
- 대용량의 자료로부터 정보를 요약하고 자료에 내재한 관계를 탐색하여 가치 창출
데이터 마이닝의 방법론
- 데이터 베이스 탐색
- 기계학습
- 패턴인식 ( 장바구니분석 , 연관규칙 )
평가 기준
- 정확도 (accuracy)
- 정밀도 (precision)
- 디텍트 레이트 (detect rate)
- 리프트 (lift)
2장 R 프로그래밍 기초
R은 2년전에 데이터분석을 위해 잠깐 사용해본 적이 있다. python으로 다루면 내용이 더 쉬웠을 것 같지만 원리는 비슷할테니 새로 배운다는 생각으로 공부하면 될 것 같다.
2.1 R 소개
R은 오픈소스
- 오픈소스
- 다양한 분석기능 제공
- 오픈소스이므로 다양한 예제 공유 / 다양한 패키지 업데이트
R의 특징
- 오픈소스 / 좋은 성능 및 그래픽
- 시스템 데이터 저장 방식 ( 매번 데이터를 로딩할 필요가 없다 )
- 모든 운영체제 사용 가능
- 표준 플랫폼 ( S 통계 언어를 기반으로 구현 )
- 객체 지향 / 함수형 언어
2.2 R 기초 - 1
프로그램 파일 실행
source(file_name) - 스크립트 파일 실행
sink(file,append,split) - R 실행 결과를 특정 파일에서 출력
appendFalse = 덮어쓰기splitFalse= 파일에만 표기 ( True일 경우 콘솔에도 표기 )
pdf(file_name) - 그래픽 출력을 pdf 파일로 지정
dev.off() - 파일 닫기
배치모드
- 인터렉션이 필요하지 않은 방식
- 매일 돌아가는 시스템에서 프로세스 자동화
$R CMD BATCH batch.R
변수와 벡터 생성
- 숫자 -
integer / double - 논리값 -
True(T) / False(F) - 문자 -
"a" / "abc"
2.2 R 기초 -2
기초 기능
print() - 출력
a <-1 / a=1 - 값 할당
ls() / ls.str() - 변수 목록확인
rm() - 변수 삭제 rm(list=ls()) - 모든 변수 삭제
c() - 벡터 생성 ( 하나라도 문자면 모든 원소는 문자 )
function() 함수 정의
예시
a<-1 a=1 / 할당
a, print(a) / 출력
x <- c(1,2,3,4)
x <- c(6.2,3.1,2.2)
x <- c("fee","fe","faa")
x <- c(x,y,z)
1:5 / (1,2,3,4,5)
9:-2 / (9,8,7,--- 0,-1,-2)
seq(from=0,to=20,by=2) / (0 , 2, 4 , --- , 18 , 20 )rep(1,time=5)
rep(1:4,each=2)
rep(c,each=2) - time에 지정한 횟수만큼 반복

paste(arg,arg,sep=) - 문자열 구분자로 붙이기

substr(string,st,en) - substr 추출

T, True, F, False - 논리값
V[n], V[-n] - n을 통해 벡터의 원소 선택 / -n을 통해 벡터의 원소 제외하고 선택

당연히 원래 벡터는 변하지 않는다.
연산자 우선순위
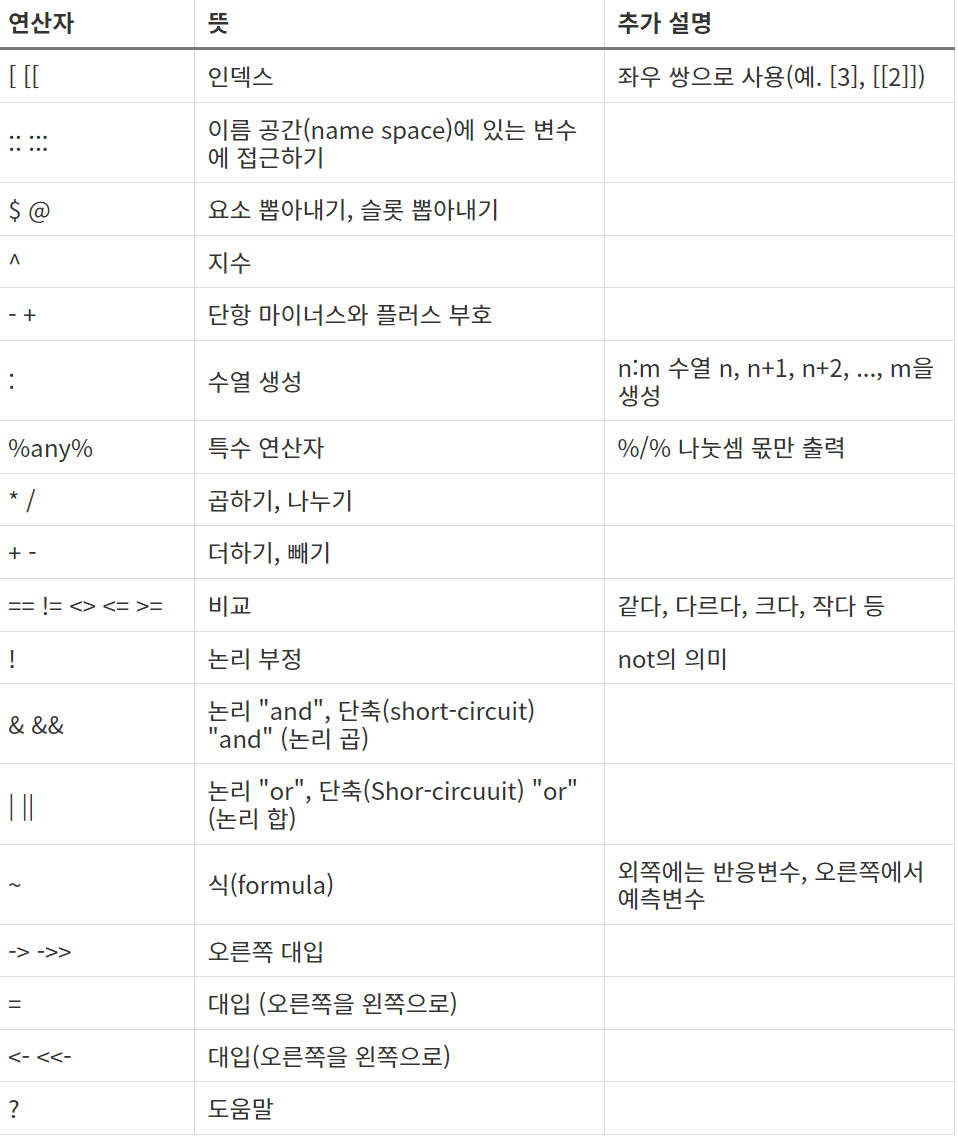
기초 통계
mean() , sum() , median() , log() , sd() - 표준편차
var() - 분산 , cov( value1 , value2 ) - 공분산
cor( value1 , value2 ) - 상관관계 , length() - 길이
2.3 입력과 출력
데이터 분석 과정
INPUT -> ANALYSIS -> OUTPUT
R의 데이터 입출력
print(val,digits=num) - 출력 자리수 지정 가능
cat('출력할 내용',변수,file='파일이름') - 파일에 출력
list.files() - 파일 목록 보기
read.fwf() - 고정 자리수 데이터 파일 읽기
read.table() - table 데이터 파일 읽기
read.csv() - 웹에서 csv 읽어오기 가능
write.csv()
library(XML)
url<-"http://dataurl.html"
t<-readHTMLTable(url)HTML에서 table 읽기
2.4 데이터 구조와 데이터 프레임 - 1
Vector
- 모두 같은 자료형을 가짐
- V[2] -> vector의 2번째 자료
- V<-c(1,2,3) / names(V)<-c('a','b','c') 이름 부여 가능
- V[1] = V['A']
List
- 다른 자료형 가질 수 있음
- 하위리스트 추출 가능 L[c(2,3)]
- 이름 부여 가능
Dataframe
- df[1] , df['name'] , df[[1]] , df[['name']] , df$name 으로 접근 가능
scalar
- 길이가 1인 vector
matrix
- 차원을 가진 vector
a <- 1:9
dim(a)<- c(3,3)array
- 행렬을 n차원으로 확장
b <- 1:12
dim(b) <- c(2,3,2)재활용 규칙

배수를 맞춰주지 않으면 경고가 발생하지만 실행은 된다.

재활용 규칙을 통한 연산
기능들
L[[n]] - 원소선택을 위해서는 [] 두번 사용
2.5 데이터 구조와 데이터 프레임 - 2
기능
data.frame(v1,v2,v3) - dataframe 생성
rbind(df1,df2) - df를 행으로 결합 ( 아래로 이어붙인다 )
cbind(df1,df2) - df를 열로 결합 ( 옆으로 이어붙인다 )
df[df$gender=='m'] - 성별이 m인 데이터만 조회
subset(df,select=gender,subset=gender=='m') - 위와 같음
subset(df,select=-gender) - gender를 제외하고 선택
merge(df1,df2,by='gender') - gender를 공통으로 하여 병합
na.omit(df) - na가 존재하는 행 삭제
sapply(a,log) - a변수에 log 함수 적용
2.6 데이터 변형
기능
lapply(l,func) , sapply(a,func) - list에 함수 적용
apply(mat,1,func) , apply(mat,2,func) - matrix에 함수 적용 / 1을 하면 transpose결과임
lapply, sapply - df에 함수 적용
apply - df에 적용시 데이터프레임이 모두 문자거나 모두 숫자일때만 가능
문자열
nchar("단어") - 길이 반환
substr("abcdefg",1,4) -> abcd substring 추출
