[CS231] Lecture 1. Introduction to Convolutional Neural Networks for Visual Recognition 정리
CS231

cs231 강의를 듣고 이해한 내용 정리하기
(이미지는 모두 강의에서 가져온것이고, 번역 과정에서 정확하지 않을 수 있다.)
computer vision ?
- 인터넷 트래픽 중 80% 지분이 비디오 데이터
-> 인터넷 데이터 대부분이 시각 데이터
segmentation : 이미지의 각 픽셀을 의미있는 방향으로 군집화하는 방법
face detection은 발전이 빨랐다.
AdaBoost를 이용한 실시간 얼굴인식(2001)
siftfeature - 객체에서 중요한 특징을 찾아내고 그 특징을 다른 객체에 매칭 -> 이미지 전체를 매칭하는것보다 쉬움
표지판에서 sift 특징을 추출하고, 또 다른 표지판에서도 특징을 추출, 식펼 & 매칭
이미지에 존재하는 '특징'을 사용
-> 이 특징을 잘 뽑아 낸다면, 그 특징들이 일종의 단서를 제공해 줄 수 있다.(이미지가 어떤것인지를 말하는것)
ML(machine learning)을 사용하기엔 시각 데이터가 너무 복잡하다.
입력이 복잡한 고차원의 데이터이기에 많은 파라미터가 필요하다.
학습 데이터가 부족해 overfiting 발생하고 성능이 좋지 않을 수 있다.
ImageNet의 motivation
- 이 세상의 모든 것을 인식하고 싶다.
- 기계학습의 overfiting 문제를 극복
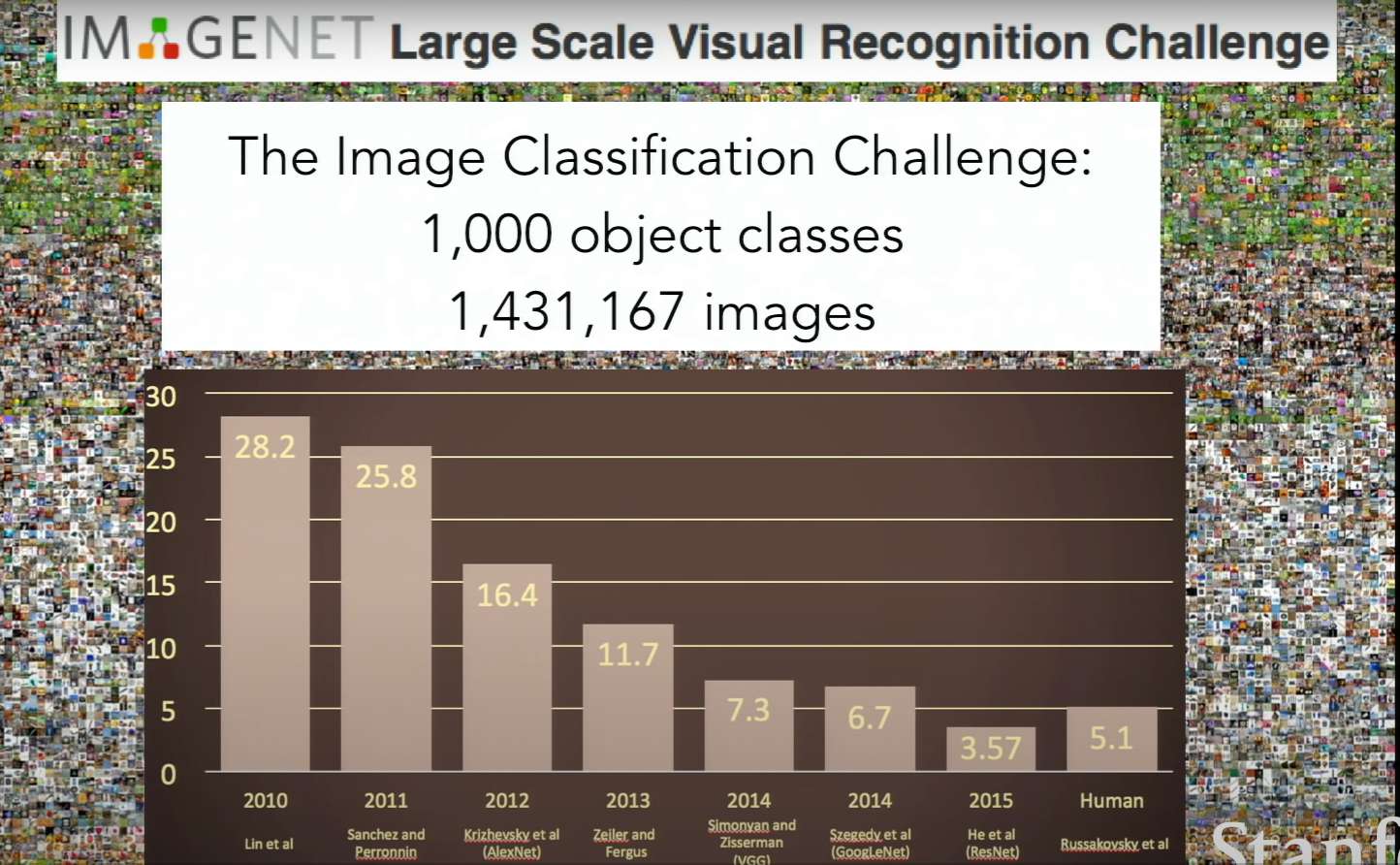 x축은 연도 y축은 오류율
x축은 연도 y축은 오류율
-> 2012년 AlexNet에서 오류가 감소한것이 중요(CNN 모델)
-
Image classification
: 이미지 한장을 몇개의 고정된 카테고리 안에서 정답을 고름 -
Object detection
: 이미지에 네모 박스를 객체의 위치에 그려아함 -
Image captioning
: 이미지가 입력으로 주어지면, 이미지를 묘사하는 적절한 문장을 생성
Convolution Neural Network, CNN, Convnet - 최근 컴퓨터 비전 분야의 진보를 끌어낸 주역
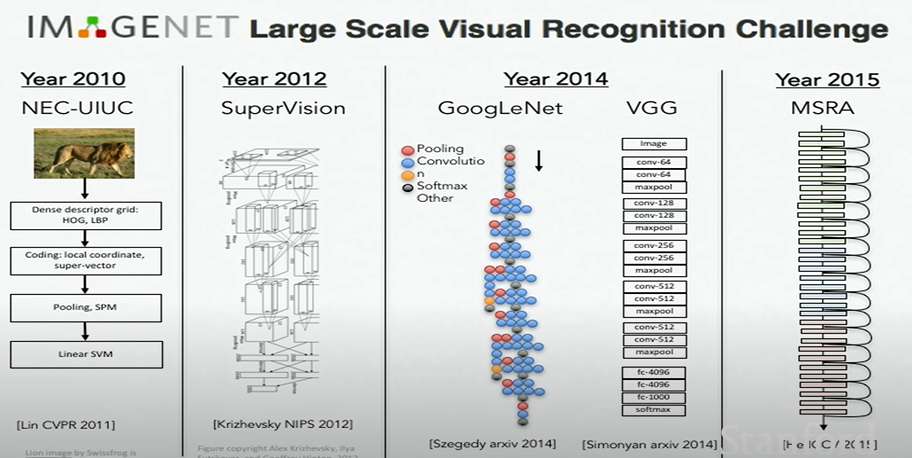
초기를 보면 계층적(hierarchical)이다. 특징을 뽑고 지역 불변 특징을 계산하고 pooling을 거치고 여러 단계를 통해 최종 linear svm에 전달.
2012년 7-Layer CNN, AlexNet(=SuperVision)을 이후 CNN은 매년 더 깊어졌다.
GoogleNet, VGG, ResNet 등 네트워크가 깊어진 모델들이 나오게 되었다.
1998년 얀르쿤이 숫자 인식을 위한 CNN을 내놓았지만 최근에서야 다시 떠오른 이유는?
-> 컴퓨터의 사양(기술)의 발전, 데이터의 차이가 있다. 연산량 증가는 딥러닝 역사에 중요한 요소이다.
