
2장 정리중
Image Classification
: A core task in Computer Vision
입력받은 이미지를 사전에 분류해 놓은 class로 분류하는 것
-
Challenges
- ViewPoint variation : 바라보는 방향의 달라짐
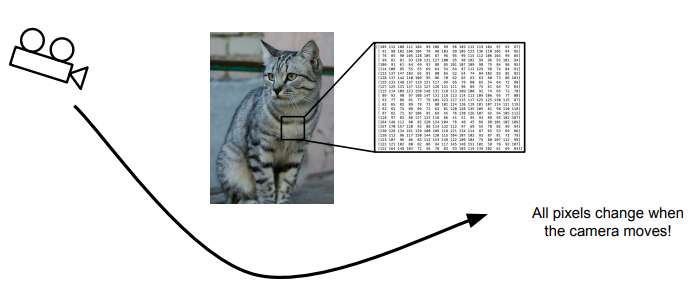
- Illumination : 조명의 문제
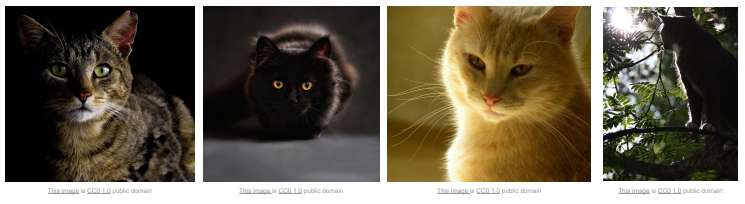
- Deformation : 객체의 자세 변경(e.g. 다양한 자세의 고양이)

- Occlusion : 가려지는것

- Background Clutter : 배경색과 비슷한 경우

- Intraclass variation : 하나의 클래스 내에 다양한 모습

-> 이러한 변형들에 알고리즘은 강인해야한다.
- ViewPoint variation : 바라보는 방향의 달라짐
세상에 존재하는 다양한 객체들에 유연하게 적용 가능한, 확장성 있는 알고리즘을 만들어야한다.
- Insight
- Data-Driven Approach
- Collect a dataset of images and labels
- Use Machine Learning to train a classifier
- Evaluate the classfier on new images
- 입력 이미지를 고양이로 인식하려면 2개의 함수가 필
- train
입력은 이미지와 레이블, 출력은 모델 - predict
입력은 모델, 출력은 이미지의 예측값
- Data-Driven Approach
- First classifier : Nearest Neighbor
def train(images, labels): # Machine Leraning... return model-> memorize all data and labelsdef predict(model, teat_images): # Use model to predict labels... return test_labels-> predict the label of the most similar training image. 새로운 이미지가 들어오면, 새로운 이미지와 기존의 학습 데이터를 비교해서 가장 유사한 이미지로 레이블링해 예측
- Example Dataset : CIFAR10
- 10개의 클래스
- 5만장의 training images
- 1만장의 testing images
- L1 Distance = 멘하탄거리(Manhattan distance)
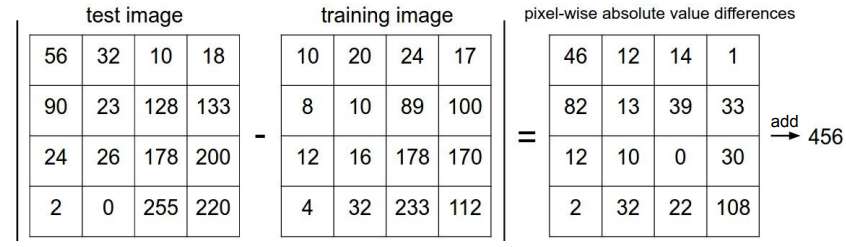
test/training 이미지의 같은 자리의 픽셀을 서로 빼고 절댓값을 취한다
= 픽셀간의 차이값을 계산하고 모든 픽셀의 수행 결과를 모두 더한다.
- Q. With N examples, how fast are training and prediction?
-> Train O(1) : 데이터를 기억하기만 하면된다.
-> Predict O(N) : test time에서 N개의 학습 데이터 전부를 테스트 이미지와 비교해야한다.

- NN분류기는 공간을 나눠서 각 레이블로 부류한다
- NN알고리즘은 가장 가까운 이웃만을 보기때문에 영역에 오류가 있을 수 있다(잡음(noise))
-> 이러한 문제들이 발생해, k-nn 알고리즘이 탄생했다
Distance metric을 이용해서 가까운 이웃을 k개 만큼 찾고, 이웃끼리 투표하는 방법. 가장 많은 득표소를 획득한 레이블로 예측한다.
L1 distance(픽셀간 차이 절댓값의 합), L2 distance 모두 사용- L2 Distance = 유클리드 거리(Euclidean distance)
- L2 Distance = 유클리드 거리(Euclidean distance)
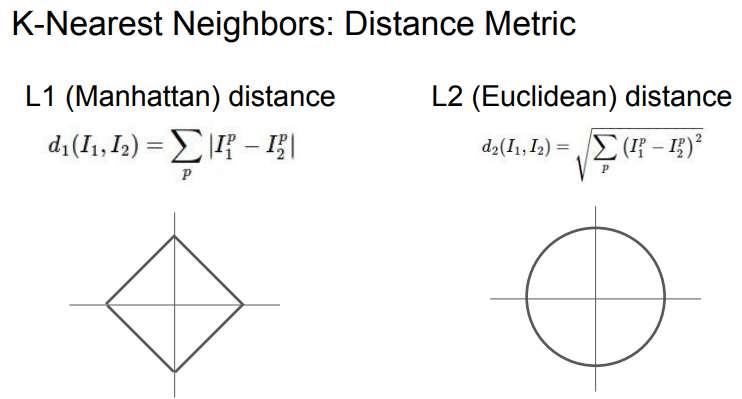
- 만약 특징 벡터의 각각 요소들이 개별적인 의미를 가지고 있다면(e.g. 키, 몸무게) L1이 적합할수도.
- 특징 벡터가 일반적인 벡터이고, 요소들간의 실질적인 의미를 잘 모르는 경우라면, L2가 어울릴수도있다.
